本文主要是介绍计算机毕业设计hadoop+spark+hive知识图谱音乐推荐系统 音乐数据分析可视化大屏 音乐爬虫 LSTM情感分析 大数据毕设 深度学习 机器学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
新余学院本科毕业设计(论文)开题报告
| 学 号 | 202253025 | 学生姓名 | 毛维星 |
| 届 别 | 24届 | 专 业 | 数据科学与大数据技术 |
| 指导教师 姓名及职称 | 潘诚 研究生 | ||
| 毕业设计 (论文)题目 | 基于Hadoop+Spark的音乐数据仓库的设计与实现 | ||
| 开 题 报 告 内 容 |
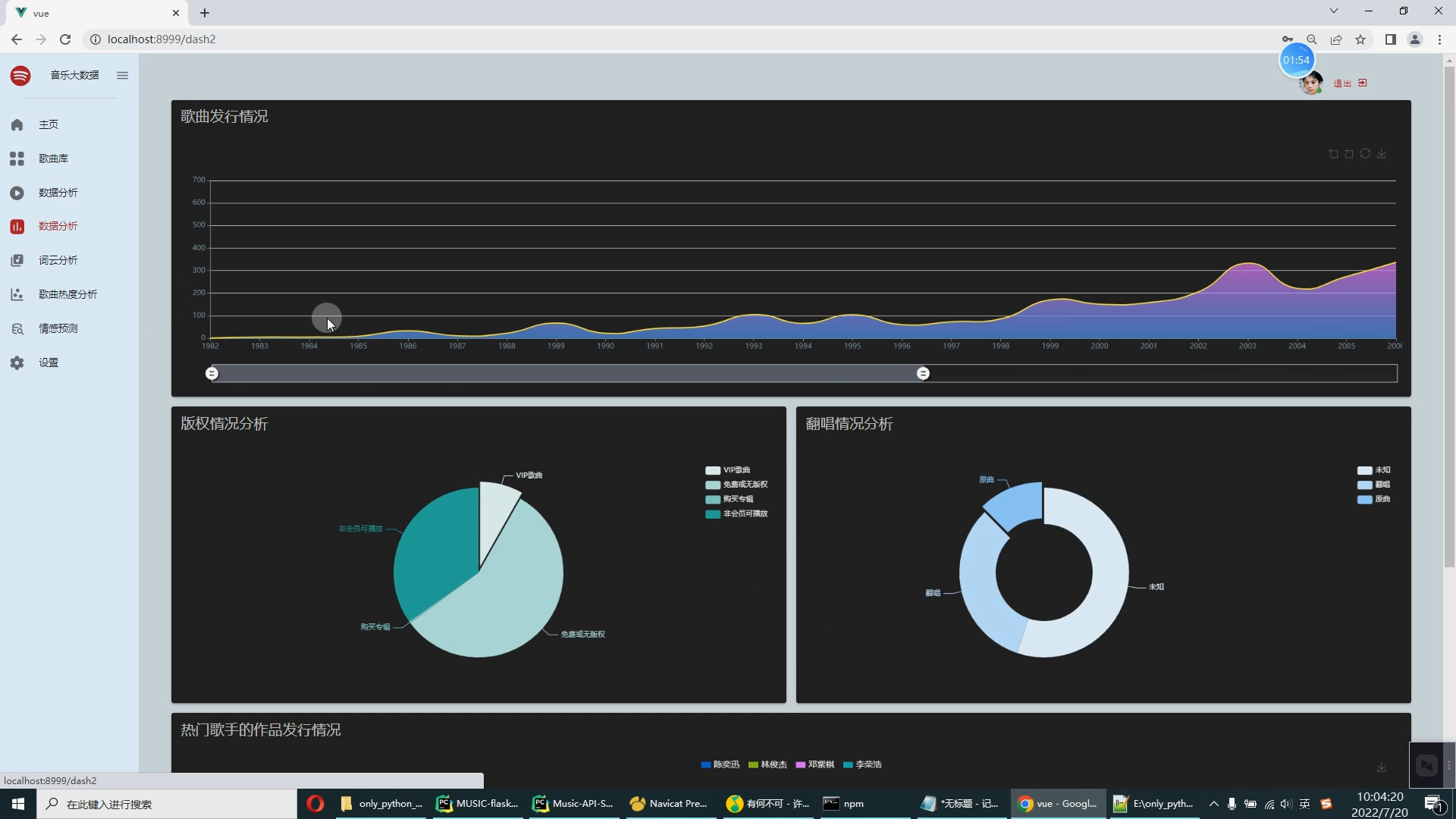
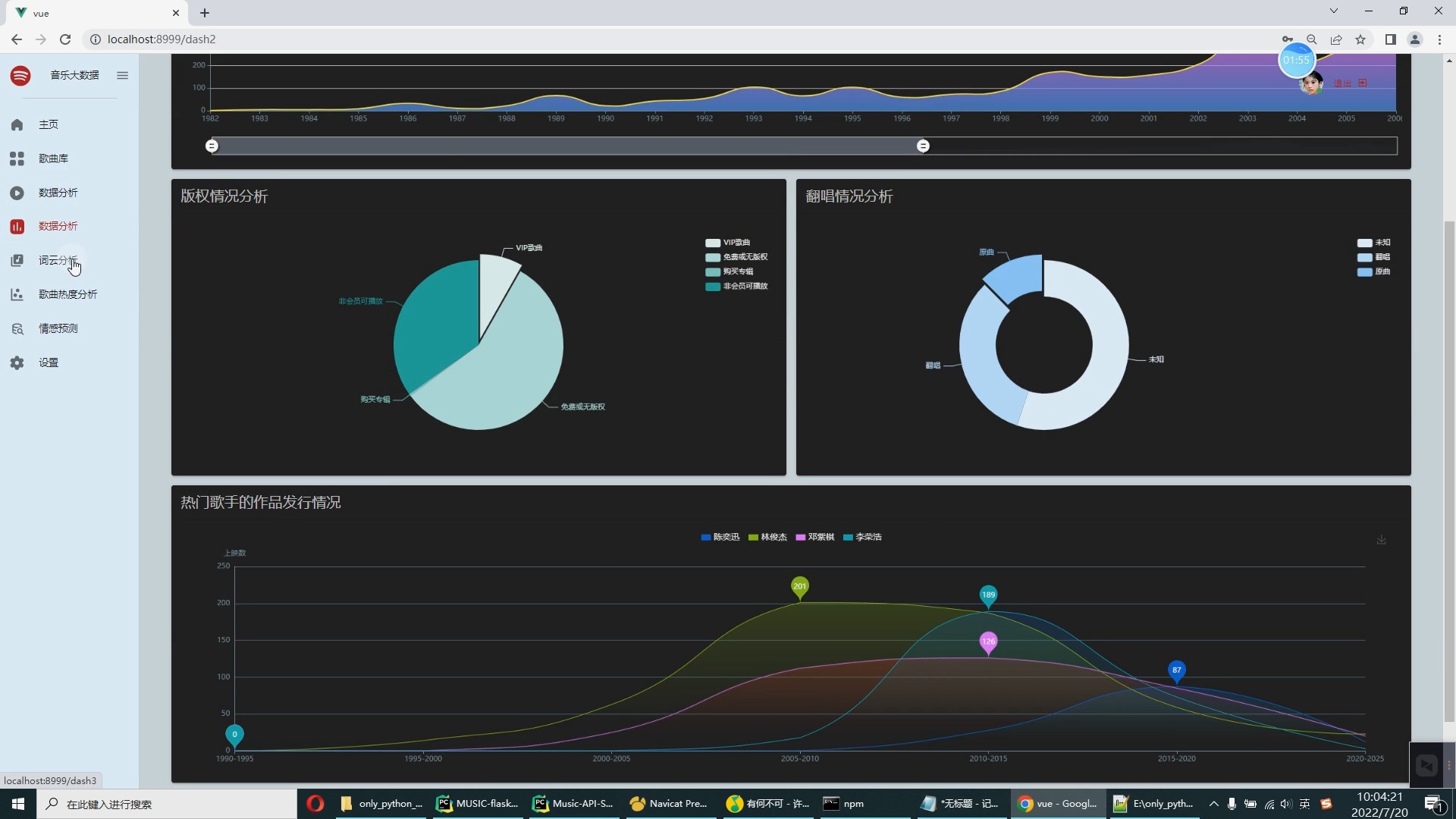
随着移动互联网迅猛发展、数字音乐的兴起,人们听音乐的方式转变为在线音乐,导致在线音乐的需求不断在增加,各大音乐网站上也有了海量的用户群体。成长在移动互联网环境下年轻一代,越发依赖在线音乐。QQ音乐、酷我音乐、网易云音乐等是国内现有的几大主流音乐平台。其中网易云音乐登顶音乐类App用户的榜首。网易云音乐最初的目标是建立一个音乐社交网络,就不同操作系统客户端上线效率而言,网易云音乐侧重于小众圈子,提高了对小众人群的关注,而小众人群有比较大的概率形成社群,经过这种网络关系来提升品牌价值。根据易观分析发布的《2021中国在线用户洞察报告》中的数据显示,相比酷我音乐、酷狗音乐和QQ音乐等,网易云音乐是年轻用户占比最大的平台,35岁以下的用户约占80%。如图1所示,根据《2020年网易云音乐销售手册》显示:网易云的用户中,以学生及白领、15~35岁、高学历、一二线城市、可支配收入高的群体为主,听歌的人群更加年轻化。因此对网易云音乐进行数据可视化分析,有利于提高用户的音乐体验,即用户可以根据自己的喜好,选择自己对应音乐标签的听音乐,也有利于更加直观地剖析音乐数据,辅助音乐公司做出决策。
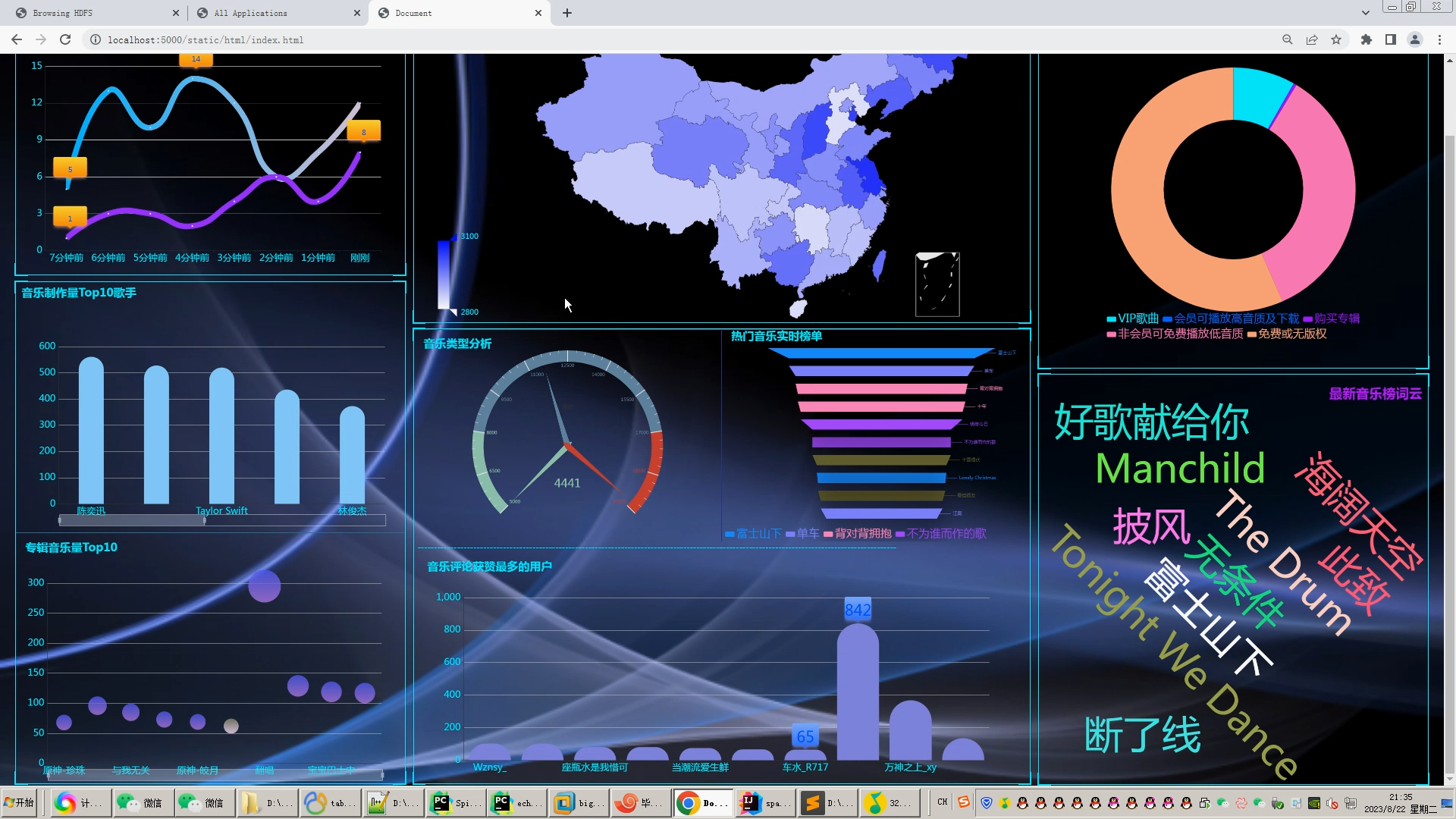
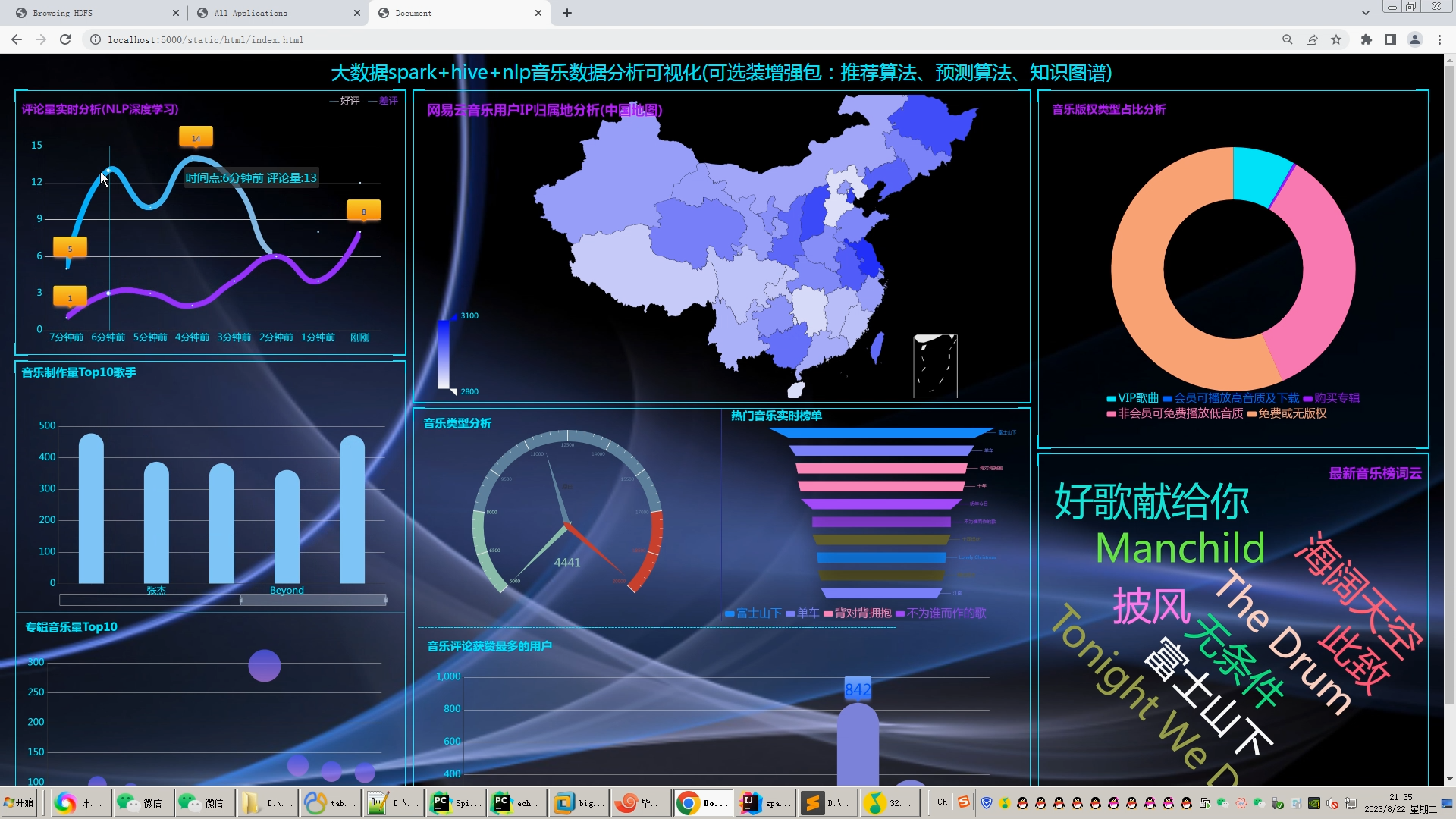
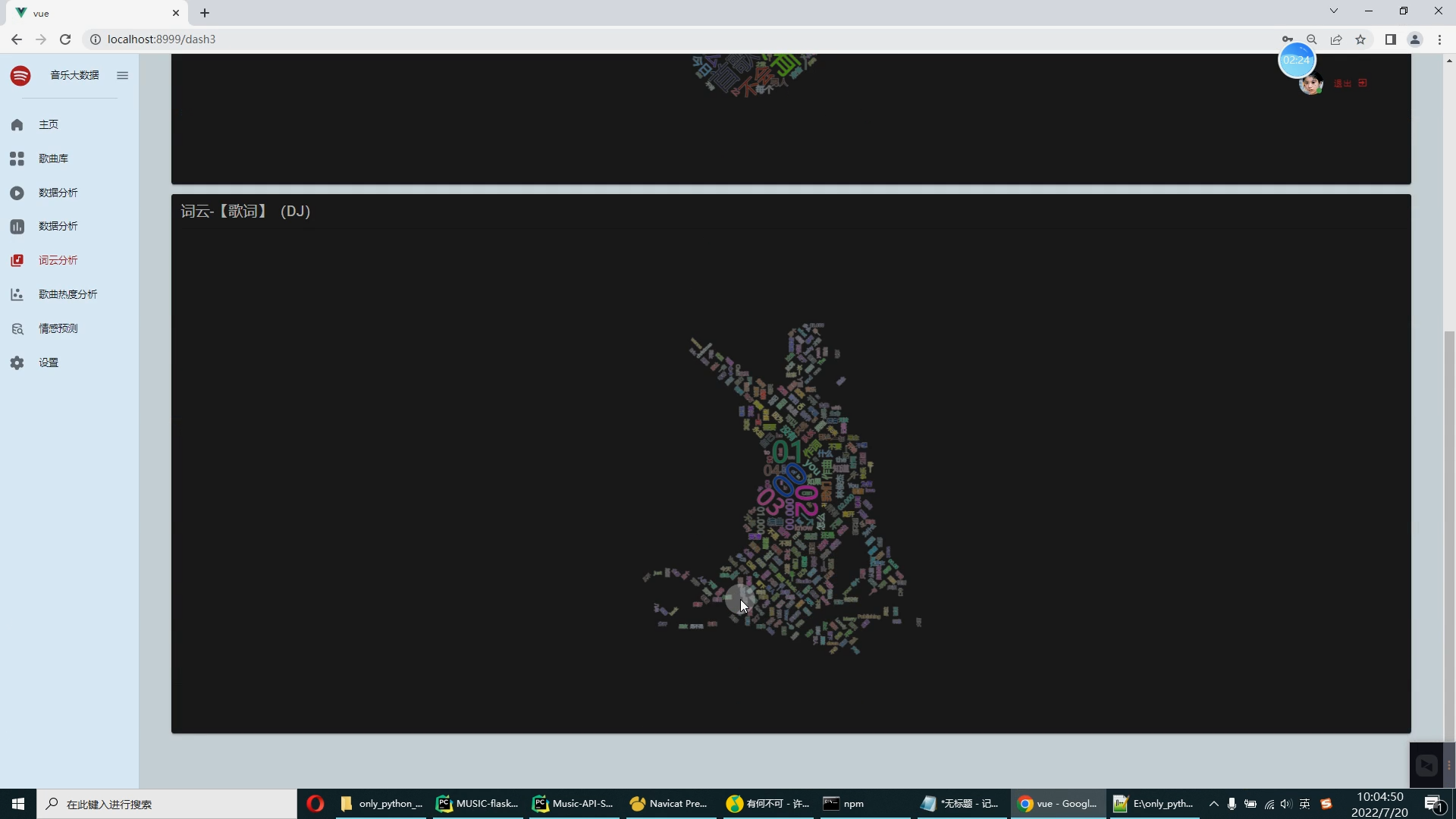
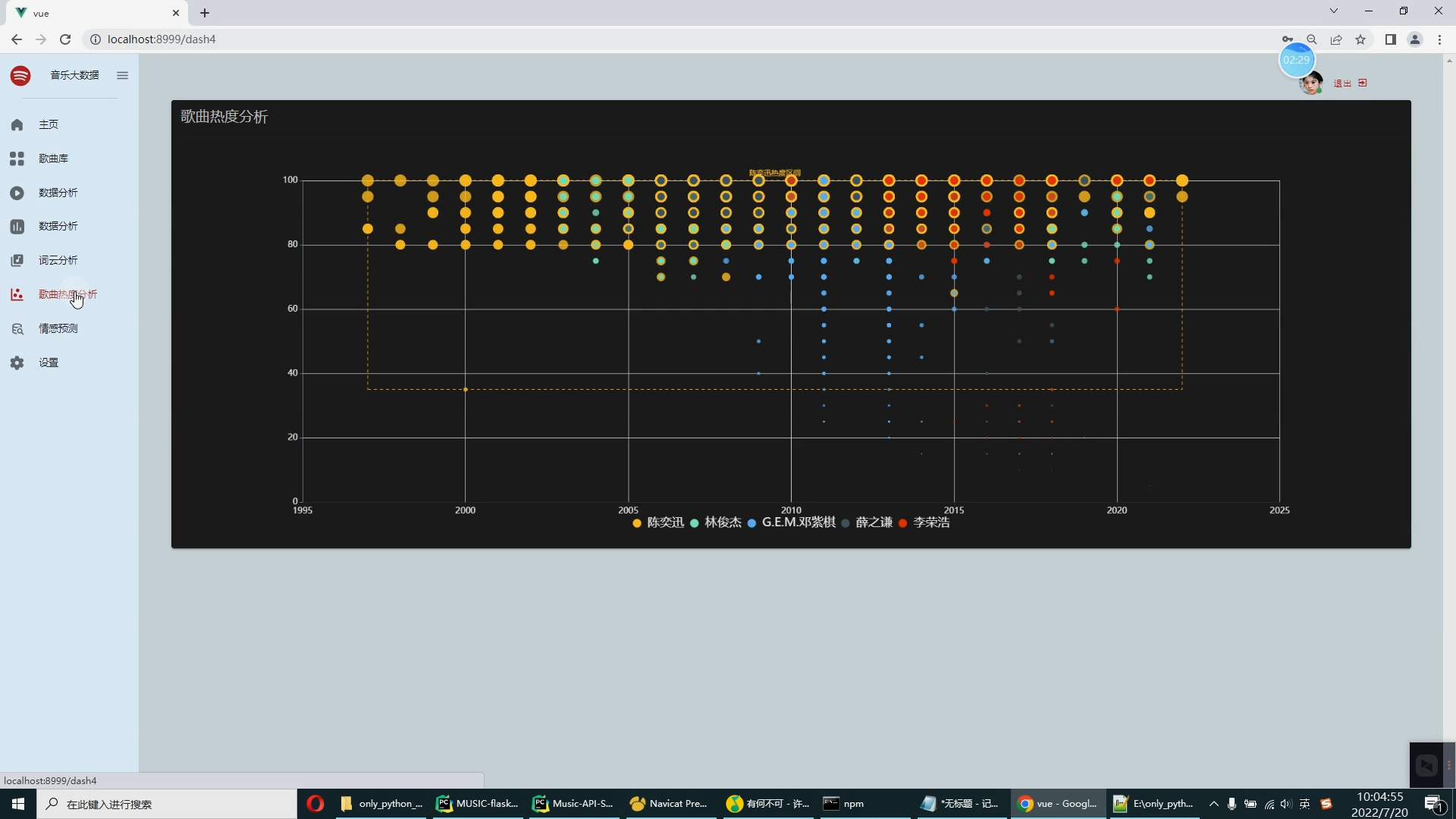
可视化分析主要应用于海量数据关联分析。由于涉及的信息比较分散,数据结构有可能不统一,而且通常以人工分析为主,再加上分析过程的非结构性和不确定性,所以普通的数据分析系统不易形成固定的分析流程或模式,很难将数据调入应用系统中进行分析挖掘。而功能强大的可视化数据分析平台,可以辅助人工操作,将数据进行关联分析,并做出完整的分析图表。图表中包含所有事件的相关信息,也能完整展示数据分析的过程和数据链走向。同时,这些分析图表也可通过另存为其他格式,供相关人员调阅。 大数据处理通常包括数据的采集、整理、存储、分析和挖掘、展示等多个环节。可视化是大数据分析的重要环节之一,因为它可能以更直观的图形、表格、地图等方式展现数据。“可视化分析并不是简单地将单一来源的数据用非常漂亮的图表展现出来,而是对不同来源的数据,比如财务数据、销售数据、人力资源数据、商业分析数据等进行分析,形成企业自己的洞见,然后再通过直观、形象的方式把它呈现出来。这才是真正的可视化。 早在2009 年,Qlik 就已经进入中国市场,目前拥有大量客户,比如联想、苏泊尔等。“中国客户对可视化分析、云服务、数据可控等有很强烈的需求。现在对我们来说,最大的挑战在于时间紧迫。我们要以更快的速度、更全面的产品和服务满足中国不同行业客户快速增长的需求。 用户要对大数据有正确的理解,大数据是用钱买不来的,一个企业如果想充分利用大数据,那么可以从一个细分的应用开始,逐渐扩展,慢慢了解和掌握数据的属性。这时,用户就需要一个平台化的工具。 在互联网信息时代,基于网络人们可以对各种信息轻松掌握,对于各种数据背后所反映出来的信息越来越重视。例如新浪微博、知乎等人们日常使用的APP背后都离不开大数据的支持。设计一个对流行音乐的数据分析,从不同方面呈现时下音乐的热度以及流行元素。以此为契机,也能在以后对其他数据的研究有更加深入的了解。
内容:
拟解决的问题:
| ||
| 开 题 报 告 内 容 | 学生签名: 年 月 日 | ||
| 指导 教师 对 开题 报告 意见 | 指导教师签名: 年 月 日 | ||
说明:本表须双面打印。
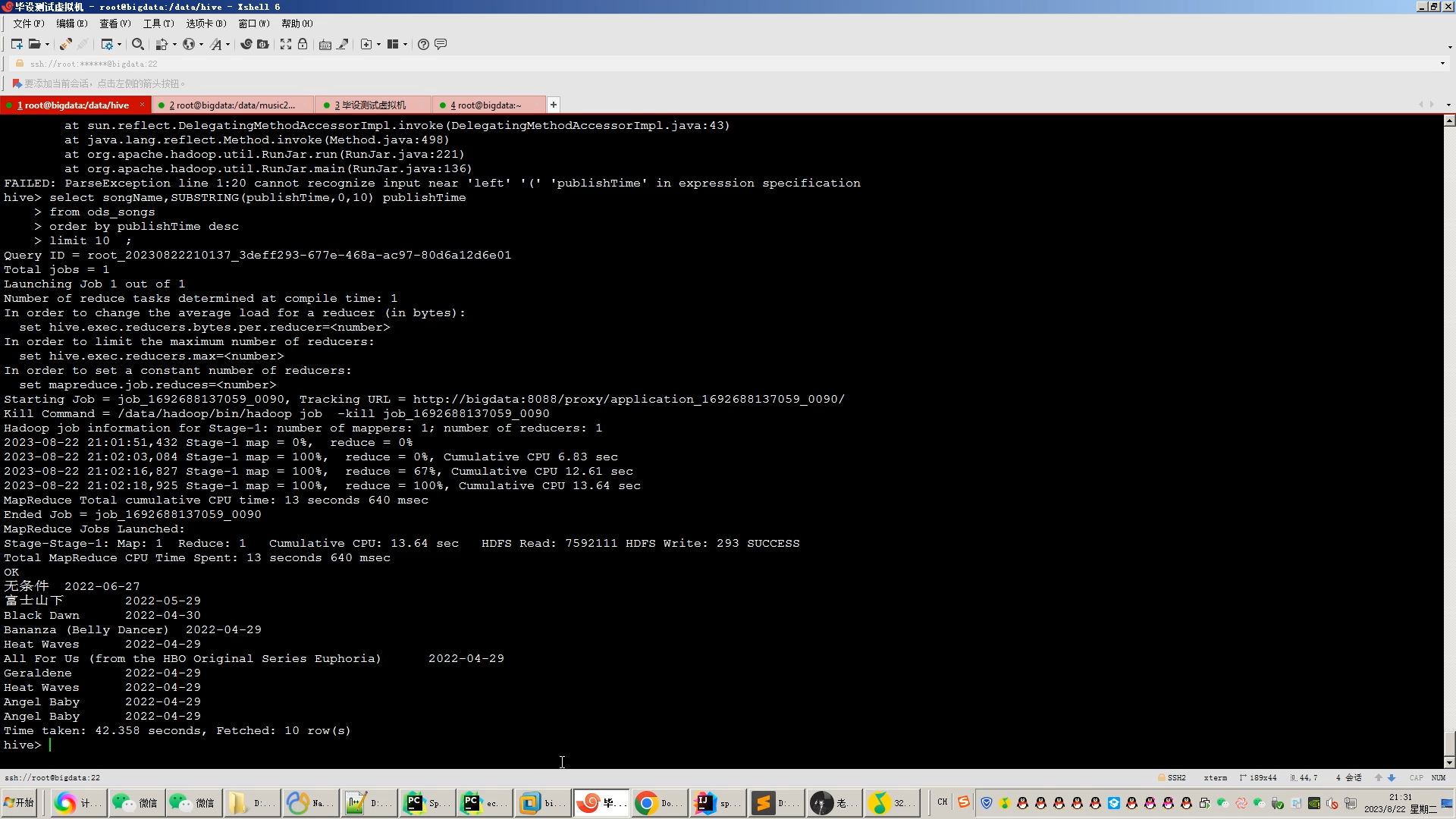
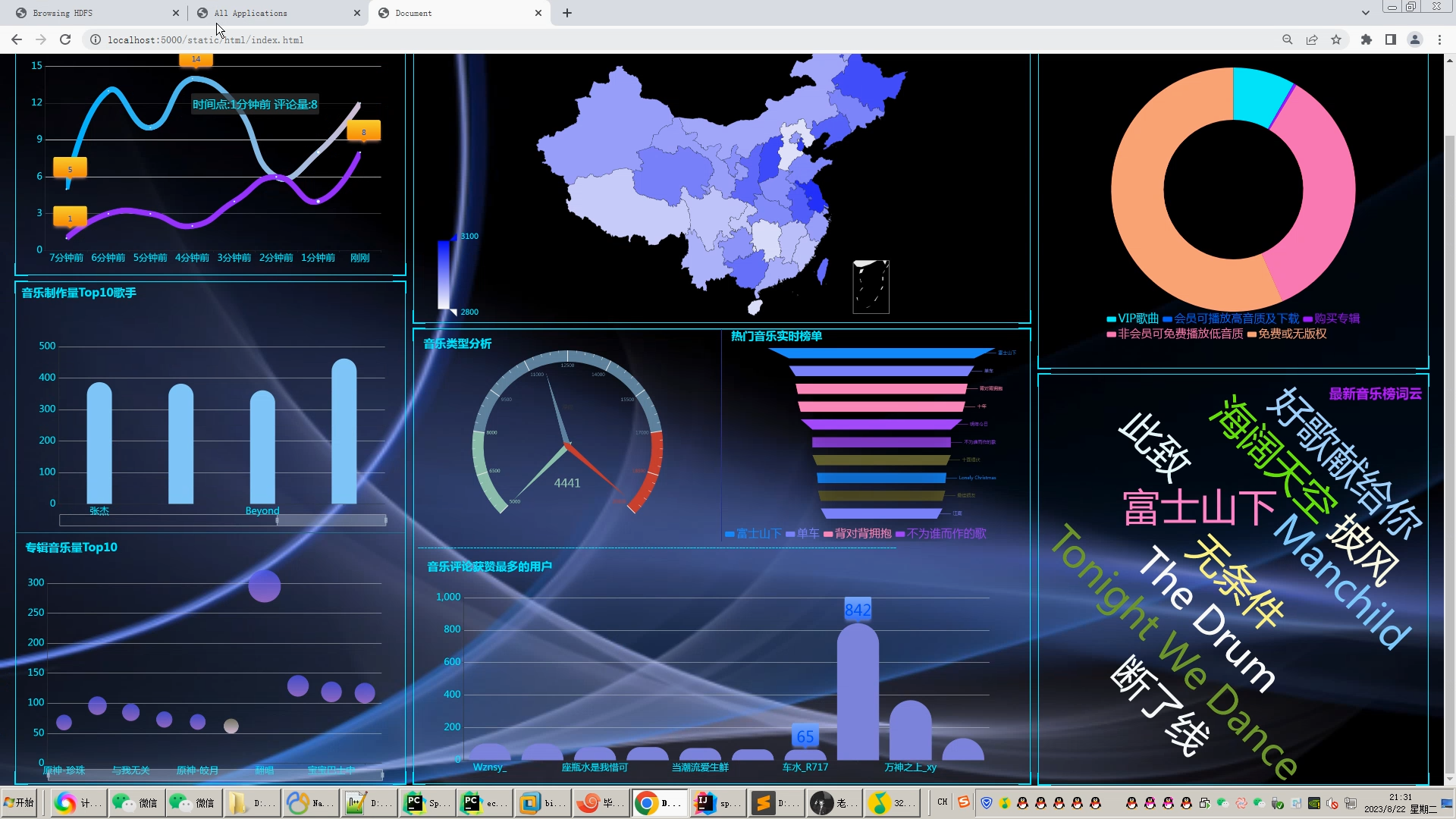








核心算法代码分享如下:
# -*- codeing = utf-8 -*-
# @Time: 2022/4/29 12:10
# @Author: Administrator
# @File: lyric.py
# @Desc: 评论情感分析
import pymysql
from snownlp import SnowNLP
connect = pymysql.connect(host="bigdata",port=3306, user="root",password="123456", database="hive_music2024")
cur = connect.cursor()
cur.execute('''SELECT * FROM tb_comment''')
rv = cur.fetchall()
for result in rv:id=result[0]songId=result[1]userId=result[2]content=result[3]nickname=result[4]avatar=result[5]commentId=result[6]likedCount=result[7]isHot=result[8]pubTime=result[9]s = SnowNLP(content)score = s.sentimentsif score < 0.5:label='negative'else:label = 'positive'print('情感分析',label,score, content)sql = "replace into tb_comment2 (songId,userId,content,nickname,avatar,commentId,likedCount,isHot,pubTime,label,score) " \"values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"data = (songId,userId,content,nickname,avatar,commentId,likedCount,isHot,pubTime,label,score)cur.execute(sql, data)connect.commit()这篇关于计算机毕业设计hadoop+spark+hive知识图谱音乐推荐系统 音乐数据分析可视化大屏 音乐爬虫 LSTM情感分析 大数据毕设 深度学习 机器学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







