本文主要是介绍O2O : Finetuning Offline World Models in the Real World,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CoRL 2023 Oral
paper
code
Intro
算法基于TD-MPC,利用离线数据训练世界模型,然后在线融合基于集成Q的不确定性估计实现Planning。得到的在线数据将联合离线数据共同训练目标策略。
Method

TD-MPC
TD-MPC由五部分构成:
- 状态特征提取 z = h θ ( s ) z = h_\theta(s) z=hθ(s)
- 隐动力学模型 z ′ ‘ = d θ ( z , a ) z'`=d_\theta(z,a) z′‘=dθ(z,a)
- 奖励模型 r ^ = R θ ( z , a ) \hat{r}=R_\theta(z,a) r^=Rθ(z,a)
- planning policy a ^ = π θ ( z ) \hat{a}=\pi_\theta(z) a^=πθ(z)
- 终止状态下的 q ^ = Q θ ( z , a ) \hat{q}=Q_\theta(z,a) q^=Qθ(z,a)
通过联合训练进行优化,损失函数为:
L ( θ ) = E ( s , a , r , s ′ ) 0 : h ∼ B ⌊ ∑ t = 0 h ( ∥ z t ′ − s g ( h ϕ ( s t ′ ) ) ∥ 2 2 ⏟ Latent dynamics + ∥ r ^ t − r t ∥ 2 2 ⏟ Reward + ∥ q ^ t − q t ∥ 2 2 ⏟ Value − Q θ ( z t , a ^ t ) ⏟ Action ) ⌋ ( 1 ) \mathcal{L}(\theta)=\mathbb{E}_{(\mathbf{s},\mathbf{a},r,\mathbf{s}^{\prime})_{0:h}\sim\mathcal{B}}\left\lfloor\sum_{t=0}^{h}\left(\underbrace{\|\mathbf{z}_{t}^{\prime}-\mathrm{sg}(h_{\phi}(\mathbf{s}_{t}^{\prime}))\|_{2}^{2}}_{\text{Latent dynamics}}+\underbrace{\|\hat{r}_{t}-r_{t}\|_{2}^{2}}_{\text{Reward}}+\underbrace{\|\hat{q}_{t}-q_{t}\|_{2}^{2}}_{\text{Value}}-\underbrace{Q_{\theta}(\mathbf{z}_{t},\hat{\mathbf{a}}_{t})}_{\text{Action}}\right)\right\rfloor(1) L(θ)=E(s,a,r,s′)0:h∼B t=0∑h Latent dynamics ∥zt′−sg(hϕ(st′))∥22+Reward ∥r^t−rt∥22+Value ∥q^t−qt∥22−Action Qθ(zt,a^t) (1)
在Offline 设定下,分布偏移将导致Q估计以及隐模型以及价值函数的错误估计。启发于IQL,通过只对in-sample的动作尽心TD-backups来估计,缓解过估计问题。因此对模型价值函数利用离线数据进行训练时,此时Q函数采用IQL中的期望回归方法优化
L V ( θ ) = ∣ τ − 1 { Q ϕ ( z t , a t ) − V θ ( z t ) < 0 } ∣ ( Q ϕ ( z t , a t ) − V θ ( z t ) ) 2 , \mathcal{L}_{V}(\theta)=|\tau-1_{\{Q_{\phi}(\mathbf{z}_{t},\mathbf{a}_{t})-V_{\theta}(\mathbf{z}_{t})<0\}}|(Q_{\phi}(\mathbf{z}_{t},\mathbf{a}_{t})-V_{\theta}(\mathbf{z}_{t}))^{2}, LV(θ)=∣τ−1{Qϕ(zt,at)−Vθ(zt)<0}∣(Qϕ(zt,at)−Vθ(zt))2,
同时对planning policy采用AWR的更新,即 exp ( β ( Q ϕ ( z t , a t ) − V θ ( z t ^ ) ) ) log π θ ( a t ∣ z t ) \exp(\beta(Q_\phi(\mathbf{z}_t,\mathbf{a}_t)-V_\theta(\hat{\mathbf{z}_t})))\log\pi_\theta(\mathbf{a}_t|\mathbf{z}_t) exp(β(Qϕ(zt,at)−Vθ(zt^)))logπθ(at∣zt)
Uncertainty Estimation as Test-Time Behavior Regularizatio
离线训练的模型依旧存在OOD数据过估计,需要在线微调。文章提出基于不确定性估计的planning实现在线交互过程中的动作选择。planning一定程度缓解基于约束的离线算法导致的在现阶段探索能力不足。进而导致算法样本效率低的问题。
首先构建集成Q函数模型,计算基于标准差的不确信度,作为惩罚项对奖励进行调整,实现保守的在线planning。
R ^ = γ h ( Q θ ( z h , a h ) − λ u h ) + ∑ t = 0 h − 1 γ t ( R θ ( z t , a t ) − λ u t ) , u t = s t d ( { Q θ ( i ) ( z t , a t ) } i = 1 N ) \hat{\mathcal{R}}=\gamma^{h}\left(Q_{\theta}(\mathbf{z}_{h},\mathbf{a}_{h})-\lambda u_{h}\right)+\sum_{t=0}^{h-1}\gamma^{t}\left(R_{\theta}(\mathbf{z}_{t},\mathbf{a}_{t})-\lambda u_{t}\right),\quad u_{t}=\mathrm{std}\left(\{Q_{\theta}^{(i)}(\mathbf{z}_{t},\mathbf{a}_{t})\}_{i=1}^{N}\right) R^=γh(Qθ(zh,ah)−λuh)+t=0∑h−1γt(Rθ(zt,at)−λut),ut=std({Qθ(i)(zt,at)}i=1N)
除此外,还维护两个buffer分别存储离线数据于在线数据,通过balance sampling数据训练模型、策略以及价值函数。
结果

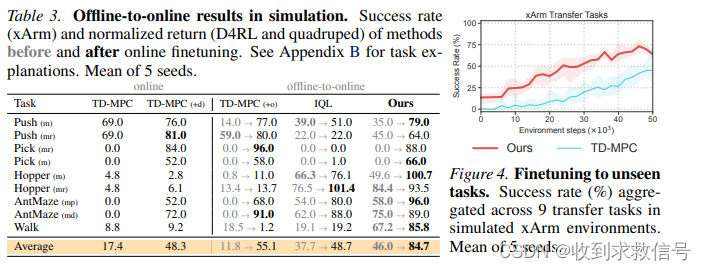
这篇关于O2O : Finetuning Offline World Models in the Real World的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![World of Warcraft [Warrior Freeblue][Hunter Grandel]](https://i-blog.csdnimg.cn/direct/3f012800ff5447ffaadf8d4482393da7.png)
![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)



