finetuning专题
![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)
[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs
引言 今天带来LoRA的量化版论文笔记——QLoRA: Efficient Finetuning of Quantized LLMs 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 我们提出了QLoRA,一种高效的微调方法,它在减少内存使用的同时,能够在单个48GB GPU上对65B参数的模型进行微调,同时保持16位微调任务的完整性能。QLoRA通过一个冻结的4位量化预
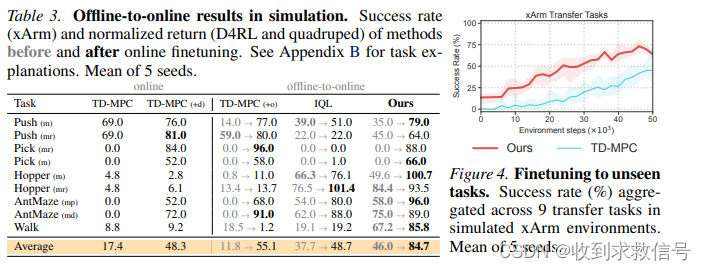
O2O : Finetuning Offline World Models in the Real World
CoRL 2023 Oral paper code Intro 算法基于TD-MPC,利用离线数据训练世界模型,然后在线融合基于集成Q的不确定性估计实现Planning。得到的在线数据将联合离线数据共同训练目标策略。 Method TD-MPC TD-MPC由五部分构成: 状态特征提取 z = h θ ( s ) z = h_\theta(s) z=hθ(s)隐动力学模型 z ′

使用QLoRA在自定义数据集上finetuning 大模型 LLAMA3 的数据比对分析
概述: 大型语言模型(LLM)展示了先进的功能和复杂的解决方案,使自然语言处理领域发生了革命性的变化。这些模型经过广泛的文本数据集训练,在文本生成、翻译、摘要和问答等任务中表现出色。尽管LLM具有强大的功能,但它可能并不总是与特定的任务或领域保持一致。 什么是LLM微调? 微调LLM涉及对预先存在的模型进行额外的训练,该模型之前使用较小的特定领域数据集从广泛的数据集中获取了模式和特征。在“L

tensorflow从已经训练好的模型中,恢复(指定)权重(构建新变量、网络)并继续训练(finetuning)
之前已经写了一篇《Tensorflow保存模型,恢复模型,使用训练好的模型进行预测和提取中间输出(特征)》,里面主要讲恢复模型然后使用该模型 假如要保存或者恢复指定tensor,并且把保存的graph恢复(插入)到当前的graph中呢? 总的来说,目前我会的是两种方法,命名都是很关键! 两种方式保存模型, 1.保存所有tensor,即整张图的所有变量, 2.只保存指定scope的变量 两种方式

Finetuning vs. Prompting:大语言模型两种使用方式
目录 前言1. 对于大型语言模型的两种不同期待2. Finetune(专才)3. Prompt(通才)3.1 In-context Learning3.2 Instruction-tuning3.3 Chain of Thought(COT) Prompting3.4 用机器来找Prompt 总结参考 前言 这里和大家分享下关于大语言模型的两种使用方式,一种是 Finetun

Finetuning Large Language Models: Sharon Zhou
Finetuning Large Language Models 课程地址:https://www.deeplearning.ai/short-courses/finetuning-large-language-models/ 本文是学习笔记。 Goal: Learn the fundamentals of finetuning a large language model (LLM).
CVPR 2023: Cross-Domain Image Captioning with Discriminative Finetuning
基于MECE原则,我们可以使用以下 6 个图像字幕研究分类标准: 1. 模型架构 编码器-解码器模型:这些传统的序列到序列模型使用单独的神经网络来处理图像和生成字幕。编码器,通常是卷积神经网络(CNN),从图像中提取视觉特征。解码器,通常是循环神经网络(RNN)如 LSTM,然后逐字生成字幕,条件是编码后的图像特征。这是早期作品如 Show and Tell [44] 和 VGG+LSTM
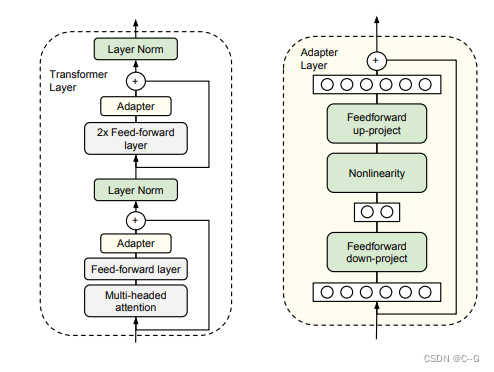
20、Finetuning
微调是指调整大型语言模型(LLM)的参数以适应特定任务的过程,用于改进预训练模型的性能。这是通过在与任务相关的数据集上训练模型来完成的。所需的微调量取决于任务的复杂性和数据集的大小。 PEFT(Parameter-Efficient Fine-Tuning)是hugging face开源的一个参数高效微调大模型的工具,里面集成了4种微调大模型的方法,可以通过微调少量参数就达到接近微调全量参数

基于飞浆NLP的BERT-finetuning新闻文本分类
目录 1.数据预处理 2.加载模型 3.批训练 4.准确率 1.数据预处理 导入所需库 import numpy as npfrom paddle.io import DataLoader,TensorDatasetfrom paddlenlp.transformers import BertForSequenceClassification, BertTokenizerfrom

吴恩达ChatGPT《Finetuning Large Language Models》笔记
课程地址:https://learn.deeplearning.ai/finetuning-large-language-models/lesson/1/introduction Introduction 动机:虽然编写提示词(Prompt)可以让LLM按照指示执行任务,比如提取文本中的关键词,或者对文本进行情绪分类。但是,微调LLM,可以让其更一致地做具体的任务。例如,微调LLM对话时
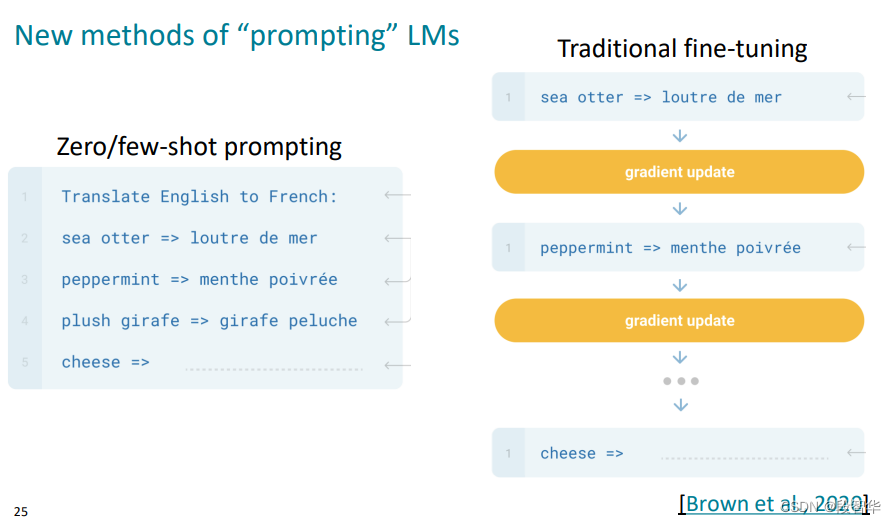
斯坦福ChatGPT: Prompting, Instruction Finetuning, and RLHF(二)
斯坦福ChatGPT: Prompting, Instruction Finetuning, and RLHF(二)