本文主要是介绍Python 基于机器学习模型的车牌检测和识别系统 有GUI界面 【含Python源码 MX_004期】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、系统介绍
车牌的检测和识别技术在现代社会中的应用场景可谓十分广泛,不仅涉及交通管理领域,还延伸至社区安保等多个方面。例如,在交通违章管理中,通过车牌追踪可以有效追踪违章车辆,维护交通秩序;在小区或地下车库的门禁系统中,车牌识别则能实现快速、准确的车辆进出管理。在车牌识别和检测的过程中,由于车牌具有独特的物理特性,如规整的矩形形状、固定的长宽比、特定的色调和纹理等,使得我们可以利用多种方法来进行有效的识别和检测。传统的基于形状的方法,通过识别车牌的矩形轮廓来定位车牌位置;基于色调的方法,则利用车牌特有的颜色和色调信息来区分车牌和其他物体;而基于纹理的方法,则是通过分析车牌表面的纹理特征来识别车牌。此外,有基于文字特征的方法,通过分析车牌上的字符特征来进行识别。
本文在车牌检测和识别的项目中,主要的流程可以分为以下几个步骤:
首先我们需要输入原始图片,并对其进行预处理。通过二值化操作,将图片转换为黑白二值图像,以简化后续的处理过程;接着利用边缘检测技术,提取出图片中的边缘信息,进一步确定车牌的轮廓;最后通过基于色调的颜色微调方法,对车牌的颜色进行微调,以提高车牌识别的准确性。
其次我们需要定位并裁剪出车牌区域。在预处理后的图像中,我们可以根据车牌的矩形形状和长宽比等特征,利用图像分割技术将车牌区域从背景中分离出来;然后通过裁剪操作,将车牌区域从原始图像中提取出来,为后续的识别工作做好准备。
接下来我们需要对裁剪出的车牌进行进一步的处理和识别。一种常用的方法是基于直方图的波峰波谷分割法。这种方法通过分析车牌图像的直方图特征,找到波峰和波谷的位置,从而将车牌字符从背景中分割出来;然后通过训练好的机器学习模型对分割出的字符进行识别。在这个项目中,我们训练了两个支持向量机(SVM)模型,一个用于识别省份简称(如“鲁”),另一个用于识别字母和数字。这些模型通过大量的训练数据学习车牌字符的特征表示,从而实现对车牌字符的准确识别。
最后为了方便用户使用和部署,我们利用PyQt5框架将整个算法封装成一个图形用户界面(GUI)程序。通过GUI程序,用户可以方便地输入原始图片、查看识别和检测结果、以及进行其他相关操作。此外我们还对整个程序进行了打包和发布,使其可以作为一个独立的安装软件供用户使用。
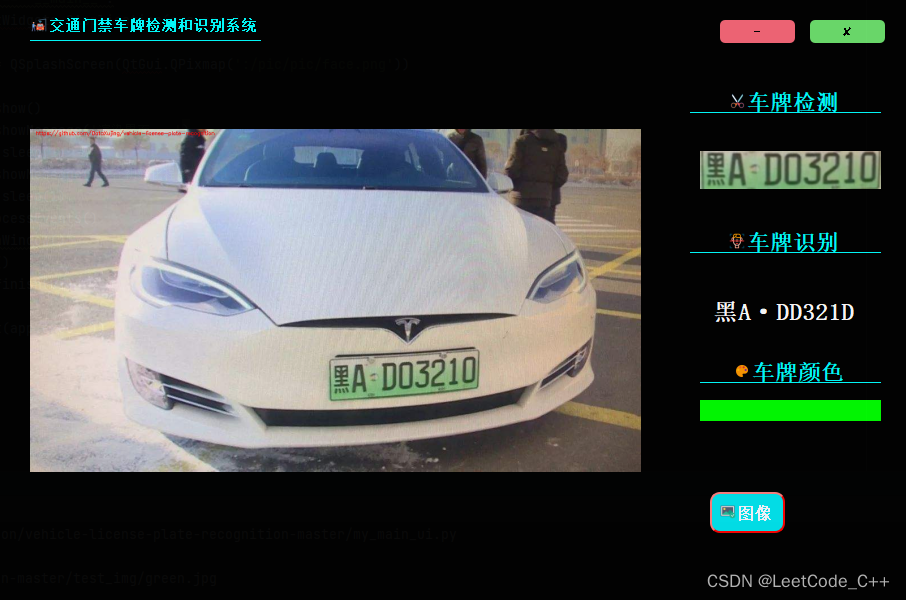
二、系统界面
三、部分代码:
def Cardseg(rois,colors,save_path):'''把一个roi列表和color列表,对应的每个车牌分割成一个一个的字然后做预测分类当然也可以考虑OCR的办法,这里使用的是传统的分类问题解决的!!!!'''seg_dic = {}old_seg_dic = {}for i, color in enumerate(colors):if color in ("blue", "yello", "green"):card_img = rois[i]gray_img = cv2.cvtColor(card_img, cv2.COLOR_BGR2GRAY)#黄、绿车牌字符比背景暗、与蓝车牌刚好相反,所以黄、绿车牌需要反向if color == "green" or color == "yello":gray_img = cv2.bitwise_not(gray_img)ret, gray_img = cv2.threshold(gray_img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)#查找水平直方图波峰x_histogram = np.sum(gray_img, axis=1)x_min = np.min(x_histogram)x_average = np.sum(x_histogram)/x_histogram.shape[0]x_threshold = (x_min + x_average)/2wave_peaks = find_waves(x_threshold, x_histogram)if len(wave_peaks) == 0:# print("peak less 0:")continue#认为水平方向,最大的波峰为车牌区域wave = max(wave_peaks, key=lambda x:x[1]-x[0])gray_img = gray_img[wave[0]:wave[1]]#查找垂直直方图波峰row_num, col_num= gray_img.shape[:2]#去掉车牌上下边缘1个像素,避免白边影响阈值判断gray_img = gray_img[1:row_num-1]y_histogram = np.sum(gray_img, axis=0)y_min = np.min(y_histogram)y_average = np.sum(y_histogram)/y_histogram.shape[0]y_threshold = (y_min + y_average)/5 #U和0要求阈值偏小,否则U和0会被分成两半wave_peaks = find_waves(y_threshold, y_histogram)#for wave in wave_peaks:# cv2.line(card_img, pt1=(wave[0], 5), pt2=(wave[1], 5), color=(0, 0, 255), thickness=2) #车牌字符数应大于6if len(wave_peaks) <= 6:# print("peak less 1:", len(wave_peaks))continuewave = max(wave_peaks, key=lambda x:x[1]-x[0])max_wave_dis = wave[1] - wave[0]#判断是否是左侧车牌边缘if wave_peaks[0][1] - wave_peaks[0][0] < max_wave_dis/3 and wave_peaks[0][0] == 0:wave_peaks.pop(0)#组合分离汉字cur_dis = 0for i,wave in enumerate(wave_peaks):if wave[1] - wave[0] + cur_dis > max_wave_dis * 0.6:breakelse:cur_dis += wave[1] - wave[0]if i > 0:wave = (wave_peaks[0][0], wave_peaks[i][1])wave_peaks = wave_peaks[i+1:]wave_peaks.insert(0, wave)#去除车牌上的分隔点point = wave_peaks[2]if point[1] - point[0] < max_wave_dis/3:point_img = gray_img[:,point[0]:point[1]]if np.mean(point_img) < 255/5:wave_peaks.pop(2)if len(wave_peaks) <= 6:# print("peak less 2:", len(wave_peaks))continuepart_cards = seperate_card(gray_img, wave_peaks)def accurate_place(card_img_hsv, limit1, limit2, color,cfg):row_num, col_num = card_img_hsv.shape[:2]xl = col_numxr = 0yh = 0yl = row_num#col_num_limit = cfg["col_num_limit"]row_num_limit = cfg["row_num_limit"]col_num_limit = col_num * 0.8 if color != "green" else col_num * 0.5 # 绿色有渐变for i in range(row_num):count = 0for j in range(col_num):H = card_img_hsv.item(i, j, 0)S = card_img_hsv.item(i, j, 1)V = card_img_hsv.item(i, j, 2)if limit1 < H <= limit2 and 34 < S and 46 < V:count += 1if count > col_num_limit:if yl > i:yl = iif yh < i:yh = ifor j in range(col_num):count = 0for i in range(row_num):H = card_img_hsv.item(i, j, 0)S = card_img_hsv.item(i, j, 1)V = card_img_hsv.item(i, j, 2)if limit1 < H <= limit2 and 34 < S and 46 < V:count += 1if count > row_num - row_num_limit:if xl > j:xl = jif xr < j:xr = jreturn xl, xr, yh, yl
四、完整代码:Python 基于机器学习模型的车牌检测和识别系统
这篇关于Python 基于机器学习模型的车牌检测和识别系统 有GUI界面 【含Python源码 MX_004期】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




