本文主要是介绍InnoDB Data Locking - Part 2.5 “Locks“ (Deeper dive),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
All together now
现在让我们把在 InnoDB Data Locking – Part 2 “Locks” 中学习到的有关表锁和记录锁的知识结合起来,以理解以下情况:

我们看到:
- 第一个
SELECT * FROM t FOR SHARE;在 5、10、42 和 supremum 伪记录上创建了 S 锁。本质上,这意味着整个轴都被锁【lock】覆盖了。这正是防止任何其他事务修改此查询【query】的结果集【result set】所需要的。此外,这首先需要在表 t 上设置 IS 表锁。 -
DELETE FROM t WHERE id=10;首先获得 IX 表锁以表明其修改表的意图,然后获取 X,REC_NOT_GAP 以仅修改 id=10 的记录 - 最后
INSERT INTO t VALUES (4);看到它已经有 IX,因此它继续执行插入。这是一个非常棘手的操作,需要我谈谈我们已经抽象出来的细节。它首先临时锁存【latching】(请注意这个词:“锁存【latching】”,而不是“锁定【locking】”!)页面,以查看这是否是放置新记录的正确位置,然后锁存【latching】插入点右侧点【point】的 Lock System 队列,并检查是否有任何 *,GAP, S 或 X 锁。在我们的例子中,这里没有任何锁,所以我们立即着手插入记录(这会有一个隐式锁,因为该记录在“last modified by”字段中具有我们当前事务的 ID,我希望这可以解释了为什么 4 上没有显式 X,REC_NOT_GAP 锁)。相反的情况是:这里存在一些冲突的锁,然后为了明确跟踪冲突,将创建一个处于等待的【waiting】 INSERT_INTENTION 锁,以便在操作被授予【Granted】后可以重试该操作。在轴上插入新点后,会将现有的间隙一分为二,而我们最后一步就是来处理这个。因此,无论这个旧间隙已经存在什么锁,都必须继承到插入点左侧新创建的间隙。这就是我们在第 4 行看到 S,GAP 的原因:它是从行 5 行的 S 锁继承而来的。
这只是涉及的实际复杂情况的冰山一角(我们还没有讨论从已删除的行继承锁、二级索引、唯一性检查......),但可以从中得到一些高层次的想法:
- 一般来说,为了提供可序列化性【serializability】,您需要“锁定您看到的内容”,这不仅包括点,还包括它们之间的间隙——您也看到了它们!如果您能想象查询【query】在扫描时如何访问表,您基本上可以猜出它必须锁定【lock】什么。这意味着拥有良好的索引很重要,这样您就可以直接跳转到要锁定的点,而不必锁定整个扫描范围【scanned range】。
- 反之亦然:如果您不关心可序列化性【serializability】,您可以考虑不锁定某些内容。例如,在较低隔离级别的
READ COMMITTED中,我们尝试避免锁定行之间的间隙(因此,其他事务可以在它们之间插入行,从而导致所谓的“幻影行”效果,这对您来说应该是显而易见的) - 在 InnoDB 中,所有行,包括“正在插入【being inserted】”和“正在删除【being deleted】”的行,都物理存在于索引中,因此出现在轴上,并将其分成间隙。这与其他一些引擎形成了对比,那些引擎将“正在进行的【ongoing】”更改保存在“暂存区【scratch pad area】”中,并仅在提交时将其合并到公共图片【common picture】中。这意味着,尽管从概念上讲,并发事务之间没有交互(例如,在提交之前,我们不应该看到该事务插入的行),但在底层实现中,它们交互相当多(例如,事务可能存在对一个正式不存在的行有一个等待锁)。因此,看到 performance_schema.data_locks 报告出现尚未插入或已删除的行(后者最终将被清除)时,不要感到惊讶
Record Locks’ compression (and missing LOCK_DATA)
在上面的例子中,您看到了一个有用的 LOCK_DATA 列,它显示了放置记录锁的索引列的行值。这对于人们分析情况是非常有用,但将此“LOCK_DATA”显式存储在内存对象中会很浪费,所以当您查询 performance_schema.data_locks 表时,这个数据实际上是从 Lock System 的内存中可用的压缩信息与缓冲池页面中可用的数据相结合,来动态重建的。也就是说,Lock System 通过记录所在页面的 <space_id, page_no> 和 heap_no (即记录在页面【page】内的编号,需要注意的是,这些编号通常不必与页面上的记录值具有相同的顺序,因为它们是由一个小的堆分配器【heap allocator 】分配的,当您删除、插入和调整行大小时,它会尝试尽可能地重用页面内的空间)来识别记录锁。这种方法有一个很好的优点,即使用三个固定长度的数字来描述一个点: space_id, page_no, heap_no。此外,由于查询必须锁定同一页上的多行是一种常见用例,因此所有仅在 heap_no 上不同的锁(通常)都存储在一个对象中,该对象具有足够长的位图【bitmap】,以便 heap_no-th 位可以表示给定记录是否应该被该锁【lock】实例覆盖。(这里有一些权衡,因为即使我们只需要锁定单个记录,我们也会“浪费”整个位图的空间。幸运的是,每页的记录数通常足够小,您可以负担得起这 n/8 个字节)
因此,即使 performance_schema.data_locks 中分别报告每个记录锁,它们通常只对应于同一锁对象中的不同位,您可以通过查看 OBJECT_INSTANCE_BEGIN 列来看到这一点:

请注意, SELECT..FROM t.. 按语义顺序(即按 id 升序)返回行,这意味着通过主键索引扫描的最简单方法确实是按主键的顺序访问行,因为它们在页面的堆【heap】内形成一个链接列表。但是,SELECT..from performance_schema.data_locks 揭示了一些内部实现的提示: id=5 的新插入行进入了 id=3 的已删除行留下的空洞中。我们看到所有记录锁【record locks】都存储在同一个对象实例中并且我们可以猜测该实例的位图已为所有实际行和最高伪记录对应的 heap_no 设置了位。
现在,让我们证明 Lock System 实际上并不知道列的值是什么,因此必须查阅缓冲池【Buffer Pool】中实际页面的内容来填充 LOCK_DATA 列。缓冲池【Buffer Pool】可以被认为是磁盘上实际页面的缓存(抱歉,我过于简单化了:实际上,它可能比磁盘上页面的数据更新,因为它还包含存储在重做日志增量中的页面补丁)。Performance_schema 仅使用来自缓冲池【Buffer Pool】的数据,而不使用来自磁盘的数据,因此如果它在缓冲池中找不到页面,它将不会尝试从磁盘获取数据,而是在 LOCK_DATA 列中报告 NULL。我们如何强制从缓冲池中逐出页面?一般来说:我不知道。但是,似乎有效的方法是将如此多的新页面推送到缓冲池,以致其达到其容量限制,并且必须逐出最旧的页面。为此,我将打开一个新客户端,并创建一个大到无法放入缓冲池的表。有多大呢?

好的,我们需要推入 128MB 的数据。(这个实验可以通过调整缓冲池的大小来简化,这通常可以动态完成,但不幸的是,“a chunk”的默认大小太大,无论如何我们也无法低于 128MB)

这应该足够了。让我们再看看 performance_schema.data_locks:
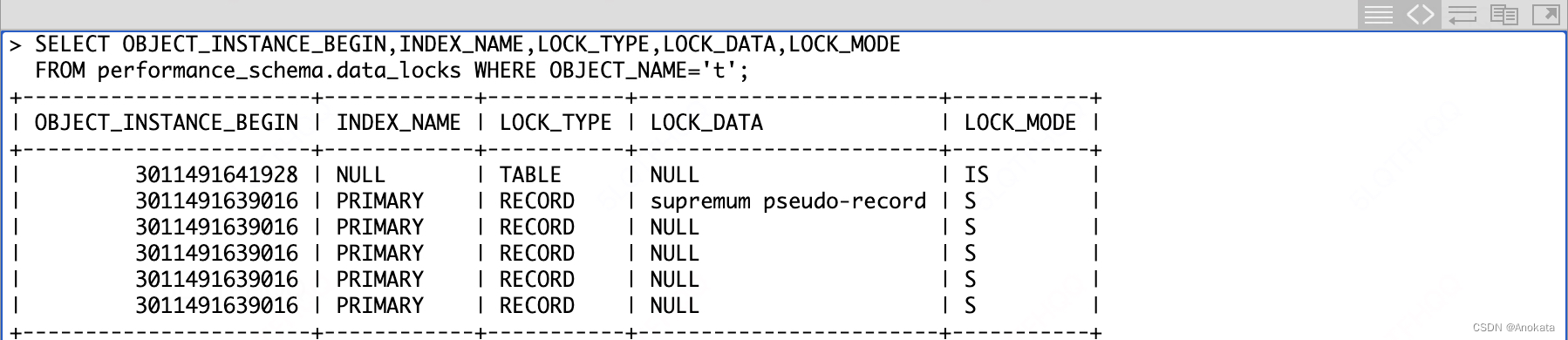
哈!你看到了吗?现在我们在 LOCK_DATA 列中有了 NULL。但不要害怕,这只是向人类呈现信息的方式—— Lock System 仍然知道哪个页面上的哪个 heap_no 被锁定,因此如果您尝试从另一个客户端访问这些记录之一,您将不得不等待:

因此,如果您在 LOCK_DATA 中看到 NULL,请不要惊慌。这仅表示该页面当前在缓冲池中不存在罢了。
正如您所料,运行 DELETE 会将页面带入内存,因此您现在可以毫无问题地查看数据:

Lock splitting
正如前面所暗示的,“轴”的“点”和“点之间的间隙”的思维模型(理论上)可以在 Lock System 中以两种不同的方式建模:
- 选项 A:点和间隙属于两种不同的资源。因此,间隙 (15,33) 是一种资源,而点 [33] 是另一种资源。可以使用一组简单的访问模式(例如,只有 X 和 S)来单独请求和授予每个资源
- 选项 B:将点和间隙组合为一种资源,并提供一组更广泛的访问模式,这些访问模式对您想要对间隙和记录执行的操作进行编码 (X, X,REC_NOT_GAP, X,GAP, S, S,REC_NOT_GAP, S,GAP,…)
InnoDB(目前)使用选项 B。我看到的主要好处是,在最常见的情况下(当事务需要在扫描期间锁定间隙和记录时),它只需要内存中的一个对象而不是两个,这不仅节省了空间,而且需要更少的内存查找,并且通常让我们使用快速路径来处理列表中的单个对象。
然而,这个设计决定并不是一成不变的,因为从概念上讲,它认为 X = X,GAP + X,REC_NOT_GAP 和 S = S,GAP + S,REC_NOT_GAP,并且 InnoDB 8.0.18 能够通过下面描述的所谓“锁分割”技术利用这些方程式。
事务必须等待甚至死锁的一个常见原因是,它已经锁定了记录,但没有锁定之前的间隙(例如,它有 X,REC_NOT_GAP),并且必须“升级【upgrade】”以覆盖记录之前的间隙(例如,它请求 X),可惜它必须等待另一个事务(例如,另一个事务正在等待 S,REC_NOT_GAP)。(事务通常不能忽略仍在等待的请求的原因是为了避免让等待者挨饿。您可以在 deadlock_on_lock_upgrade.test 中看到详细描述的此类场景)
“锁拆分”技术采用上面给出的方程式,并从中得出 needed - possessed = missing,在我们的例子中:
X – X,REC_NOT_GAP = X,GAP,
因此,对 X 的事务请求被默默地转换为更适中的请求:仅针对 X,GAP。在这种特殊情况下,这意味着请求可以立即被授予(回想一下 *,GAP 请求永远不必等待任何事情)从而避免了等待和死锁。
Secondary indexes
如前所述,每个索引都可以看作是一个单独的轴,该轴上有自己的点【point】和间隙【gap】,这些点和间隙可以被锁定【lock】,这会使图【picture】变得稍微复杂一些。通过遵循一些常识性规则,您可能可以自己找出对于给定查询必须锁定哪些点和间隙。基本上,您需要确保,如果一个事务修改了影响另一个事务结果集【result set】的内容,那么无论查询计划如何,该读取事务所需的锁必须与执行修改的事务所需的锁冲突。有几种方法可以设计规则来实现这一目标。
比如,考虑如下这张表:

让我们试着弄清楚下面这条语句应该需要哪些锁:
DELETE FROM point2D WHERE x=1;
这里有两个轴:x 轴和 y 轴,我们应该至少锁定点 x 轴上的点 (1),这似乎是合理的,那么 y 轴呢?我们能避免在 y 轴上锁定任何东西吗 ?老实说,我认为这取决于数据库实现,但是考虑一下,如果锁只存储在 x 轴上,
SELECT COUNT(*) FROM point2D WHERE y=2 FOR SHARE;
那么该查询将将如何操作。合理地说,这个 SELECT 将首先使用列 y 上的索引来查找匹配的行,但是为了知道它是否被锁定,它必须了解它在列 x 上的值。这仍然是一个合理的要求:InnoDB 确实在每个二级索引条目中存储了主键的列(在我们的例子中 x 就是主键),因此在索引中查找 y 的 x 值并不是什么大问题。然而,回想一下,在 InnoDB 中,锁并没有真正绑定到 x 的值(例如,这可能是一个相当长的字符串),而是绑定到 heap_no (我们在位图中用作偏移量的一个编号)—您需要知道 heap_no 才可以检查锁是否存在。因此,现在必须深入到主键索引并加载包含该记录的页面,以便了解该记录的 heap_no 值。这通常不是很快。
因此,另一种方法是确保无论使用哪个索引来查找 x=1 的行,都可以发现该行上的锁,而无需参考任何其他索引。这可以通过在 y 轴上锁定 y=2 的点来实现。这样,上面提到的 SELECT 查询在尝试获取自己的锁时将看到它被锁定。这个 SELECT 应该取什么锁 ?同样,这可以通过几种方式实现:它可以只锁定 y 轴上 y=2 的点,或者它也可以跳转到主键索引锁定 x 轴上 x=1 的点。正如我已经说过的,出于性能原因,第一种方法似乎更快,因为它避免了对主键索引的查找。
所以,让我们看看我们的怀疑是否与现实相符。首先,让我们检查通过二级索引进行选择【select】的事务所持有的锁(优化器可能会选择扫描主键索引的查询计划,而不是使用二级索引,即使在你认为这很疯狂的查询时也是如此——在这样的决策中,会有一种关于探索/利用的权衡【explore/exploit trade-off 】。此外,我们人类关于什么更快的直觉可能是错误的)

这符合我们的期望:我们在整个表上看到一个意图锁 (IS),在特定记录上看到一个不包含间隙的锁(S,REC_NOT_GAP),两者都是“共享的【shared】”。注意,LOCK_DATA 列将这条记录描述为2,1,因为它所列出的列的顺序,与存储在该行的二级索引的条目中的顺序相同:首先是被索引的列(y),然后是主键的缺失部分(x),因此,2,1的意思是 <y=2,x=1>。
让我们回滚这个事务,让它回到原来的状态,现在让我们检查一下 DELETE 单独使用了那些锁:

嗯,这很令人费解:我们在整个表上看到了预期的意图锁 (IX),我们在主键索引记录本身上看到了锁,都是“排他的【exclusive】”,但我们没有在二级索引上看到任何锁。如果 DELETE 只获取主键索引上的锁,SELECT 只获取二级索引上的锁,那么 InnoDB 如何防止这两个操作并发执行呢?
让我们保持这个 DELETE 事务打开,并启动另一个客户端,看看它是否能够看到删除的行:

嗯…SELECT 阻塞了(这很好),但是怎么阻塞的呢?
让我们检查一下 performance_schema.data_locks 找出是什么情况:
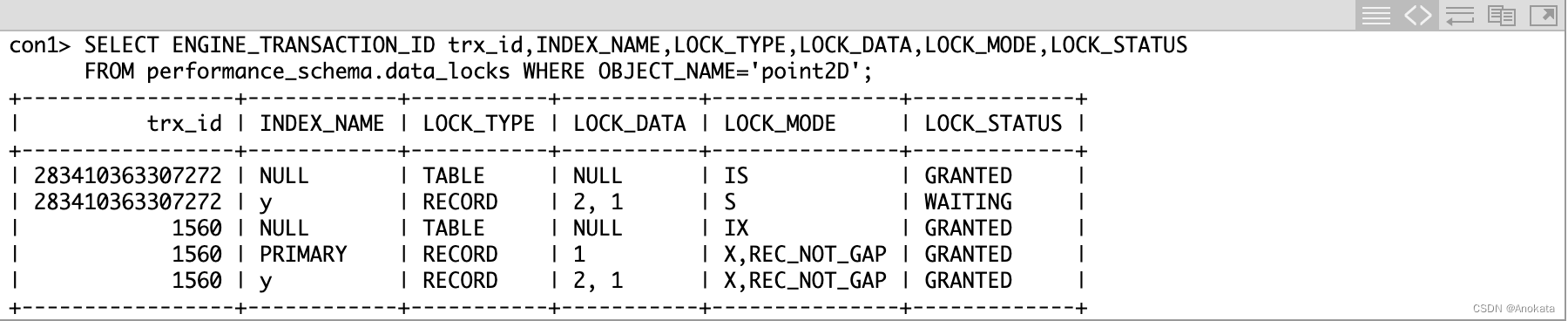
哈!我们的事务(283410363307272)正在等待获得二级索引记录 <y=2,x=1> (以及它之前的间隙)上的 S 锁,我们可以看到它必须等待的可能原因是执行 DELETE (1560) 的事务正在以 X,REC_NOT_GAP 模式锁定相同的 <y=2,x=1> 。
但是,就在一秒钟之前,当我们检查1560 事物持有的锁时,我们还没有看到任何这样的锁——这把锁是现在才出现的,这是怎么回事?考虑到 1560 目前没有“积极地做任何事情”,这就更令人费解了——它怎么可能获得锁呢?
回想一下 performance_schema.data_locks 只显示显式锁,而不显示隐式锁,并且隐式锁可以在需要时转换为显式锁,以便跟踪谁必须等待谁。在实践中,这意味着当事物 283410363307272 请求 Lock System 授予它在 <y=2,x=1> 上的 S 锁时, Lock System 首先检查该记录上是否存在它可以推断的隐式锁。这是一个相当复杂的过程,它存在于 lock_sec_rec_some_has_impl :
- 检查 page_get_max_trx_id(page) 的值—对于每个页面,我们存储修改过该二级索引页面的所有事务中的最大 id 。
DELETE操作确实将它“碰撞”到它其自己的 id (除非它已经更大)。 - 然后,我们将这个max_trx_id与某个 trx_rw_min_trx_id() 进行比较,后者跟踪仍在活动的事务中的最小id。换句话说,我们尝试探试地判断是否有可能某些活动的事务对二级索引有隐式锁,并且我们在这里进行了一些权衡
- 在二级索引上,我们不跟踪每条记录的 max_trx_id ,而是跟踪整个页面的 max_trx_id,因此使用的存储空间更少,但是我们可以错误地认为我们的记录被修改了,尽管实际上该更改是应用于同一页面上的其他记录
- 我们不太仔细地检查这个max_trx_id 是否属于活动事务集,只是与其中的最小 id 进行比较(坦率地说,根据之前的简化,我们必须这样做以保持正确:我们不知道修改行的事务的实际 id,只知道这些事物的 id 的上限)。
- 如果探试说任何人都不可能对这条记录有隐式锁,因为没有任何活动事务的 id 低于修改该页面的最大事物 id。 我们可以在这里停止了,这意味着我们不必查阅主键索引,万岁!
- 否则,事情就会变得一团糟。我们进入 row_vers_impl_x_locked ,它将:
- 在主键索引中定位记录(在某些罕见的情况下,由于与清除线程竞争,该记录可能已经丢失【missing】)
- 检索最后一个修改该特定行的事务的 trx_id (注意,这是上面第一个探试式的更精确的模拟),然后
- 检查 trx_id 是否仍然处于活动状态(注意,这是上述第二个探试式的更精确的模拟)
- 如果事务仍然是活动的,那么它仍然可以在二级索引上没有隐式锁。例如,它可以修改一些非索引列,在这种情况下,二级索引条目在概念上不受影响,因此不需要隐式锁。为了检查这一点,我们必须繁琐地检索该行的先前版本,并精确地检查任何索引列是否受到影响,这在概念上意味着需要锁。这非常复杂。我不打算在这里解释,但是如果您感到好奇,您可以在 row_clust_vers_matches_sec 和 row_vers_impl_x_locked_low中阅读我的评论
- 最后,如果认为隐式锁是必要的,那么它将被转换为代表其合法所有者(来自主键索引记录头的trx_id)的显式锁(它总是 X,REC_NOT_GAP 类型)。
这里的主要结论是,在最坏的情况下,您不仅需要检索主键索引记录,还需要从 undo 日志中检索其以前的版本,以确定是否存在隐式锁。在最好的情况下,您只需查看二级索引页,并说“不”。
好吧,看起来执行 DELETE 的线程有点懒,而执行 SELECT 的线程必须做一些额外的工作来明确DELETE 留下的隐式锁。
但是,你可能会好奇:如果首先执行 SELECT,然后我们再开始 DELETE 会怎么样?假设 SELECT 只锁定二级索引,而 DELETE 似乎没有获得任何二级索引锁,那么它怎么可能被未提交的 SELECT 阻塞呢?在这个场景中,我们是否也执行一些隐式到显式的锁转换?似乎不太可能,因为 SELECT 不应该修改任何行,因此不应该将其 trx_id 放在行或页的 header 中,因此没有它的踪迹来推断隐式锁。
也许我们发现了一个bug?让我们 ROLLBACK
con1> ROLLBACK;
con2> ROLLBACK;
然后一起来检查这个新场景:

然后另一个客户端执行 DELETE:

似乎没有bug,因为 DELETE 正在等待。让我们看看显式锁:

(给超级敏锐的读者的技术提示: 283410363307272 不仅是一个可疑的长数字,它也和我们在前面的一个例子中看到的 id 完全相同。对于这两个谜团的解释很简单:对于只读事务,InnoDB不会浪费时间去分配一个真正单调的事务 id,而是从 trx 的内存地址中临时获取它。)
很好,我们得到了一个与前一个结果有点对称的结果,但是这次是 SELECT 被授予锁,而DELETE 具有等待锁(另一个不同之处在于这次 SELECT 使用 S,REC_NOT_GAP 而不是 S ,坦率地说,我不记得为什么我们还需要在前一种情况下要锁定间隙,幸运的是,这对我们的故事无关紧要)。
好吧,那么为什么执行 DELETE的 事务现在有一个显式的等待锁,即使我们看到单独执行 DELETE 并没有创建这样的锁?
答案是:DELETE 确实尝试在二级索引上获取一个锁(通过调用 lock_sec_rec_modify_check_and_lock),但这涉及到一个棘手的优化:当 Lock System 确定这个锁可以被授予时,因为已经没有冲突的锁了,而不是创建一个显式锁,而是避免这样做,因为调用者告诉它,如果需要,可以推断出一个隐式锁。(为什么?可能是为了避免必须分配 lock_t 对象:考虑一个单独的 DELETE 操作可能会影响在主键上形成连续范围的许多行—而与它们对应的二级索引条目可能到处都是,因此不能从压缩机制【 compression mechanism】中受益。此外,只要在 InnoDB 中有任何地方使用隐式锁,那么你就必须检查它们,如果你必须检查隐式锁,那么你最好在适用的地方使用它们,因为检查它们的成本已经支付了)。
在我们的例子中,Lock System 确定存在冲突,因此创建一个显式的 WAITING 锁来跟踪它。
总结一下,当前版本的 InnoDB 使用哪种解决方案来防止二级索引上的 DELETE 和 SELECT 冲突?
- DELETE 锁定两个索引,SELECT 只锁定一个索引?或者是
- DELETE 只锁定主键索引,SELECT 负责检查所有?
我想说,它很复杂,但更像第一种方法,需要注意的是,DELETE 对二级索引所采取的锁尽可能是隐式的。
好了,现在我们已经准备好讨论死锁检测【deadlock detection】了,这是我们的下一个主题。
这篇关于InnoDB Data Locking - Part 2.5 “Locks“ (Deeper dive)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!