locks专题

brew install opencv@2 时报错 Error: Can't create update lock in /usr/local/var/homebrew/locks!
解决方案,报错里已经说明了: 我的解决方案: sudo chown -R "$USER":admin /usr/local stackoverflow上的答案 I was able to solve the problem by using chown on the folder: sudo chown -R "$USER":admin /usr/local Also you'

6.S081的Lab学习——Lab8: locks
文章目录 前言一、Memory allocator(moderate)提示:解析 二、Buffer cache(hard)解析: 三、Barrier (moderate)解析: 总结 前言 一个本硕双非的小菜鸡,备战24年秋招。打算尝试6.S081,将它的Lab逐一实现,并记录期间心酸历程。 代码下载 官方网站:6.S081官方网站 安装方式: 通过 APT 安装 (De

Java中synchronized与java.util.concurrent.locks.Lock区别
相同点:Lock能完成synchronized所实现的所有功能 区别:Lock比synchronized更精确的线程语义和性能;chronized会自动释放锁,而Lock需要程序员手动释放,而且必须在finally从句中释放。Lock更强大的功能,如tryLock方法可以非阻塞方式去拿锁: import java.util.concurrent.locks.Lock;import jav
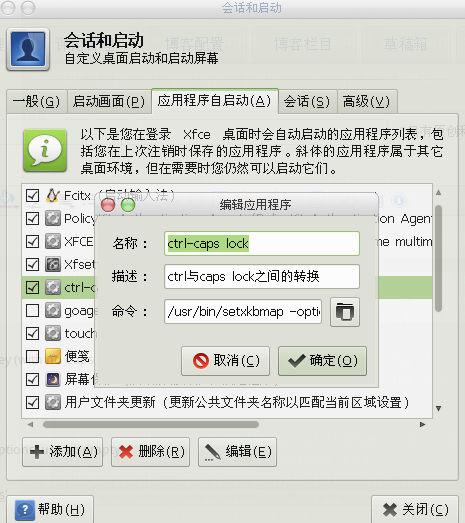
XFCE下ctrl与caps locks两个键互换
1. 先安装setkbmap这个软件: sudo emerge -av setxkbmap 2. 一次性的设置如下: Swap Control and Caps Lock Keys方法一:将Caps Lock键变成另一个control键(这样就没有了Caps Lock键)/usr/bin/setxkbmap -option 'ctrl:nocaps'方法二:两者相互交换/u

Failure obtaining db row lock: No row exists in table QRTZ_LOCKS for lock named:
项目里做了使用Spring+Quartz建立一个任务调度管理模块, 实现了基于service层的定时任务管理,包括任务创建、执行、暂停、启动、定时设置、日志等。 在另外一个项目使用时出现如下Error: Failure obtaining db row lock: No row exists in table QRTZ_LOCKS for lock named: TRIGGER_ACCESS

PostgreSQL的视图pg_locks
PostgreSQL的视图pg_locks pg_locks 是 PostgreSQL 提供的系统视图,用于显示当前数据库中的锁信息。通过查询这个视图,数据库管理员可以监控锁的使用情况,识别潜在的锁争用和死锁问题,并优化数据库性能。 pg_locks 视图字段说明 以下是 pg_locks 视图中的一些主要字段及其说明: locktype:锁的类型,如 relation, extend,
MySQL插入大批量数据时报错“The total number of locks exceeds the lock table size”的解决办法
事情的原因是:我执行了一个load into语句的SQL将一个很大的文件导入到我的MySQL数据库中,执行了一段时间后报错“The total number of locks exceeds the lock table size”。 首先使用命令 show variables like '%storage_engine%' 查看MySQL的存储引擎: mysql> show variab

mysql大批量删除(修改)The total number of locks exceeds the lock table size 错误的解决办法
一、问题描述 开发中对一张大表进行批量的更新或者删除的时候 会报以下错误: The total number of locks exceeds the lock table size 从字面上理解,就是当前操作锁住的总行数已经超过设置的锁表的大小。 二、解决办法 解决方案一:分批进行更新或者删除 如给delete 语句后面加上limit ,一次 1w条 delete fr

InnoDB Data Locking - Part 2.5 “Locks“ (Deeper dive)
All together now 现在让我们把在 InnoDB Data Locking – Part 2 “Locks” 中学习到的有关表锁和记录锁的知识结合起来,以理解以下情况: 我们看到: 第一个 SELECT * FROM t FOR SHARE; 在 5、10、42 和 supremum 伪记录上创建了 S 锁。本质上,这意味着整个轴都被锁【lock】覆盖了。这
Java中的同步(Synchronization)和锁(Locks)有何区别,如何使用它们?
在 Java 中,同步(Synchronization)和锁(Locks)都是用于管理多线程之间对共享资源的访问,以避免并发问题,如数据不一致或者线程干扰等问题。虽然它们的目的相同,但具体的实现机制和使用场景有所不同。 同步(Synchronization) 同步是 Java 中原生支持的线程同步机制,主要是通过 synchronized 关键字来实现的。你可以将方法或代码块标记为 synch
Java多线程包的Locks一览
Java多线程包的Locks一览 Java多线程包提供了Locks,用作线程控制,看到这个名字自然要想起原生的Synchronized关键字,二者有什么优劣呢? Synchronized在得不到锁时只能等待,但是Locks可以使用tryLock这样的方法 听起来好处也有限,但还是看看Locks的几个API吧 //要求获得锁,会阻塞整个线程void lock();//要求获得
MYSQL锁之InnoDB record,gap and next-key locks
InnoDB 在行级锁包括record loc,gap lock(区间锁),next-key locks,其中: Record lock: 索引记录锁,就是仅仅锁着单独的一行 Gap lock: 在索引记录之间进行锁,包括第一条索引数据前和最后一条索引数据后 Next-key lock:是 record lock和a gap lock的组合,gap lock 在某记录前 i
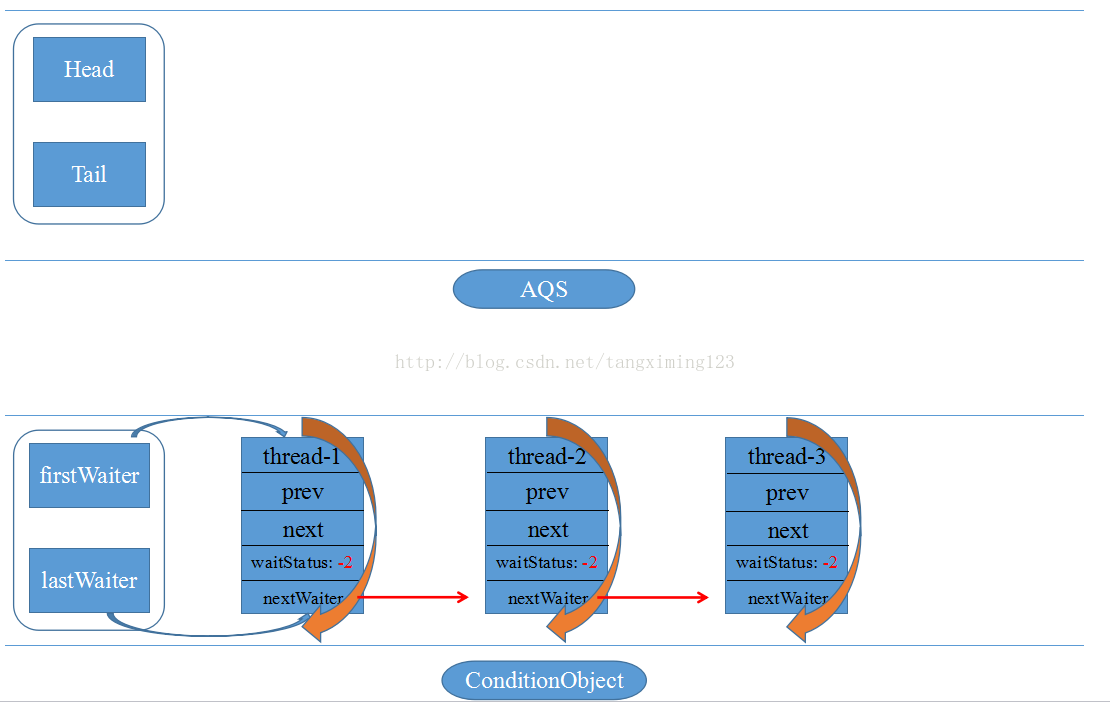
J.U.C — Locks — ReentrantLock(二)
条件变量Condition Condition实现了synchronized同步器的wait/notify/notifyAll的功能,Condition接口提供的API如下: Condition需要与Lock绑定,一个Lock可以有多个Condition,获取Condition的方式是lock.newCondition()。Condition的实现类在AQS

J.U.C — Locks — ReentrantLock(一)
整体结构 公平锁和非公平锁 如果获取一个锁是按照请求的顺序得到的,那么就是公平锁,否则就是非公平锁。 公平锁保证一个阻塞的线程最终能够获得锁,因为是有序的,所以总是可以按照请求的顺序获得锁。 不公平锁意味着后请求锁的线程可能在其前面排列的休眠线程恢复前拿到锁,这样就有可能提高并发的性能。 这是因为通常情况下挂起的线程重
Caused by: java.lang.UnsupportedOperationException: Exceeded maximum number of wifi locks
问题如下: Caused by: java.lang.UnsupportedOperationException: Exceeded maximum number of wifi locks 问题原因: 先看代码如下: WifiManager manager = (WifiManager) this.getSystemService(Context.WIFI_SERVICE)
Can't open file 'svn/myapp/db/txn-current-locks':permission denied
Can't open file 'svn/demo/db/txn-current-locks':permission denied 将svn一直到NAS上,测试svn是否能正常运行。 使用svn提交文件的时候,提示:Can't open file 'svn/demo/db/txn-current-locks':permission denied. 原因是:版本库的文件夹属主变成了ro
synchronized 和java.util.concurrent.locks.Lock的异同
简述synchronized 和java.util.concurrent.locks.Lock的异同? 答:Lock是Java 5以后引入的新的API,和关键字synchronized相比主要相同点:Lock 能完成synchronized所实现的所有功能;主要不同点:Lock有比synchronized更精确的线程语义和更好的性能,而且不强制性的要求一定要获得锁。synchronized会自动
创建文件系统 报错: crfs: mkpatch: /etc/locks: Do not specify an existing file:
记录一次 创建 文件系统失败的case: 我是现建lv ,在这个基础上建 fs 的: 报错: crfs: mkpatch: /etc/locks: Do not specify an existing file: 查找: cd /etc/ 发现 : locks ---> link 到 /var/locks 在去cd /var 发现 locks 没有 解决过程: mkdir

「实验记录」MIT 6.S081 Lab8 locks
#Lab8: locks I. SourceII. My CodeIII. MotivationIV. Memory allocator (moderate)i.Motivationii. Solutioniii. Result V. Buffer cache (hard)i. Motivationii. SolutionS1 - 定义 bcache 结构体S2 - bcache 的相关操作
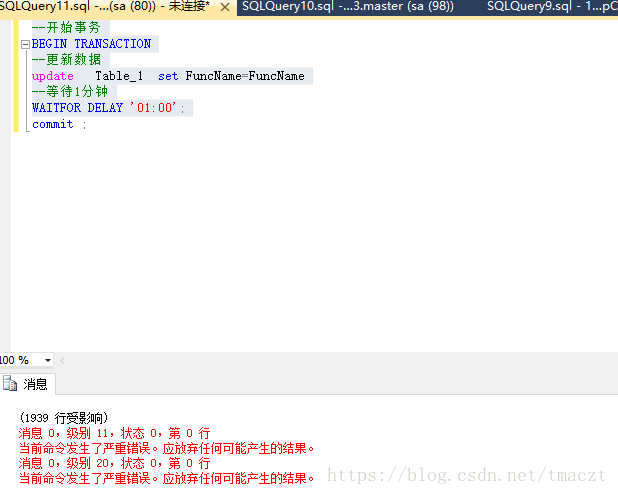
SqlServer 使用sys.dm_tran_locks处理死锁问题
1、模拟资源锁定 --开始事务BEGIN TRANSACTION--更新数据update Table_1 set FuncName=FuncName--等待1分钟WAITFOR DELAY '01:00'; 2、查看锁对象 SELECT request_session_id spid ,OBJECT_NAME(resource_associated_entity_id)

Multi-Programming-10 Re-entrant Locks
1.What is the difference between synchronized and re-entrant lock? 这里是关于该问题的讨论。 中文简单解释一下: 问题:'synchronized'和 're-entrant lock'有什么不同,或者换种说法--这两种方式分别在哪些情形下适用? 解答:官方关于're-entrant lock'的解释--重入锁和内
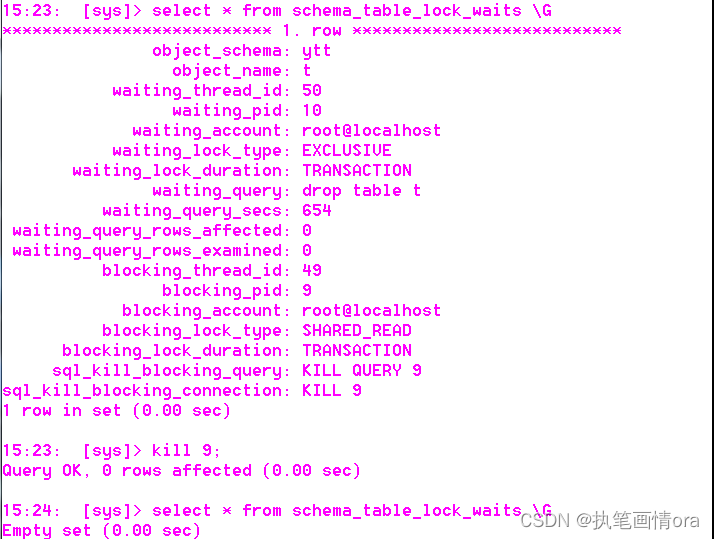
Mysql数据库管理-阻塞lock问题分析处理 session和schema_table_locks_waits
1 schema_table_lock_waits 1 首先启用mdl锁等待事件相关的instruments 15:31: [sys]> select name from performance_schema.setup_instruments limit 10; +---------------------------------------------------------+ | n

项目上线到 Linux 使用Spring Quartz的时候出错,Table '**.QRTZ_LOCKS' doesn't exist
解决方法: mysql数据库区分大小写。所以找不到大写的表名。应该在my.cnf的[mysqld]节点下加入lower-case-table-names=1
2023-10-10 mysql-{mysql_rm_table_no_locks}-出错后回滚-记录
摘要: 2023-10-10 mysql-{mysql_rm_table_no_locks}-出错后回滚-记录 mysql_rm_table_no_locks 完整函数代码: /**Execute the drop of a normal or temporary table.@param thd Thread handler@param tabl

java.util.concurrent.locks.Condition详解
Condition翻译成中文是“条件”,一般我们称其为条件变量,每一个Condition对象都通过链表保存了一个队列,我们称之为条件队列。 当然了,这里所说的Condition对象一般指的是Condition接口的实现类ConditionObject,比如我们实现同步锁的基础AQS内部的ConditionObject类。 一、Condition接口 Condition只是一个简单的

【LittleXi】【MIT6.S081-2020Fall】Lab: locks
【MIT6.S081-2020Fall】Lab: locks 【MIT6.S081-2020Fall】Lab: locks内存分配实验内存分配实验准备实验目的1. 举一个例子说明修改前的**kernel/kalloc.c**中如果没有锁会导致哪些进程间竞争(races)问题2. 说明修改前的kernel/kalloc.c中锁竞争contention问题及其后果3. 解释acquire和rel