本文主要是介绍SleepFM:利用对比学习预训练的多模态“睡眠”基础模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。

SleepFM
睡眠医学是一个关键领域,涉及监测和评估生理信号以便于诊断睡眠障碍和了解睡眠模式。多导睡眠图 (PSG)等技术可记录睡眠期间的大脑、心脏和呼吸活动,从而反映一个人的睡眠健康状况。这些数据对于对睡眠阶段分类和识别睡眠障碍至关重要。
PSG 通常包括脑电图 (EEG)、眼电图 (EOG)、肌电图 (EMG)、心电图 (ECG) 和呼吸通道。每种模式都提供了独特的视角:大脑活动信号 (BAS) 测量大脑功能,心电图监测心律,呼吸传感器量化呼吸模式,共同提供睡眠健康的全面评估。
手动分析涉及由训练有素的技术人员进行目视检查,费时费力,而且容易出错。这种传统方法面临着重大挑战,尤其是随着睡眠数据量的增加。因此迫切需要能高效和准确的多种睡眠数据的融合自动化分析技术。
目前睡眠数据分析方法主要依赖于监督深度学习模型。这些模型在自动化睡眠分期和睡眠呼吸障碍等方面的确斩获不少。然而大多数现有方法依赖于来自比较狭窄的语料,并没有利用PSG提供的全部数据。
此外,虽然对比学习在其他领域取得了成功,但它在整合 BAS、ECG 和呼吸信号进行睡眠分析方面的应用仍未得到充分探索。
来自斯坦福大学和丹麦技术大学的研究人员推出SleepFM,这是一种用于睡眠分析的开创性多模态基础模型。该模型利用了来自14,000多名参与者的庞大多模态睡眠记录数据集,这些数据在1999年至2020年间在斯坦福睡眠诊所收集的总计超过100,000小时的睡眠数据。SleepFM 利用对比学习方法来整合大脑活动、心电图和呼吸信号。这种集成使模型能够捕获全面的生理表征,从而显着提高睡眠分析的准确性。

对比学习
对比学习(Contrastive learning)代表了机器学习方法的范式(paradigm)转变,特别是在处理未标记数据集的场景。这种方法的核心是基于数据的相似性和不同性对数据进行二元分类。该框架有效地将相似的实例放置在潜在空间中,同时确保不同类别进行分离。它在具体的表现就是相似性的数据应该在学到的嵌入(Embedding)空间保持紧密对齐,而那些不同的数据则应该相离更远。
对比学习最重要的是数据增强,此步骤通过各种转换来生成一系列数据不同维度的表示方法。包括裁剪、翻转、旋转和其他扰动,有助于扩大数据集的多样性。关键还是要增强数据的异质性,从而将模型引入相同实例的多个视角。
举个例子,将苹果的各个维度的照片输入模型,告诉模型这都是苹果

架构详解
SleepFM采用三种一维卷积神经网络 (CNN) 从每种模态(BAS、ECG 和呼吸信号)生成嵌入。这些模型的架构基于为对 ECG 测量进行分类而开发的 1D CNN。
每个 CNN 都经过定制以处理其各自模式的特定特征:10 个用于 BAS 的通道,2个用于 ECG 的通道,7个用于呼吸通道。引入了一种Leave-One-Out的技术,在捕捉不同生理信号之间的协同关系明显优于标准的成对的对比学习。
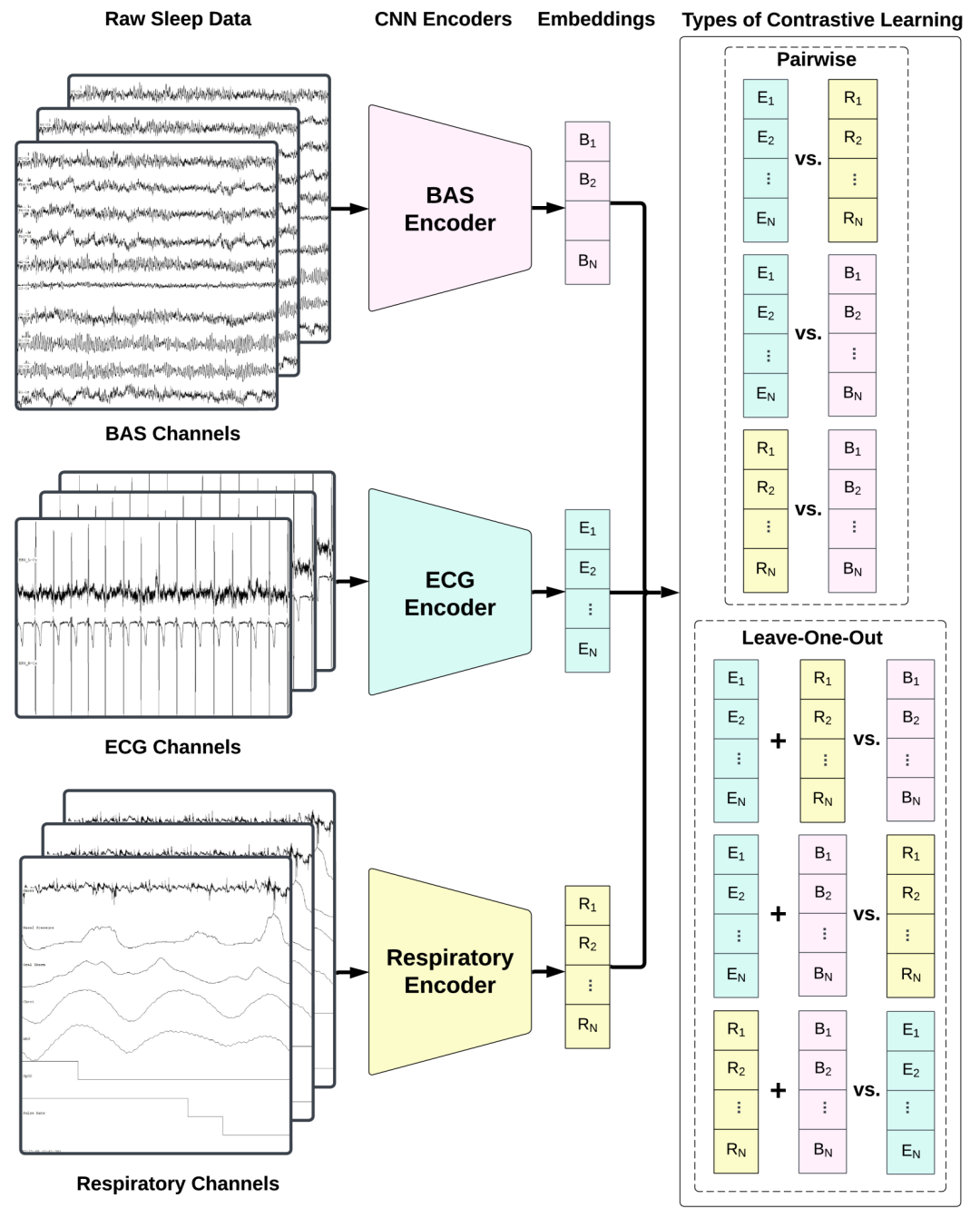
在这次的项目中,研究人员探索了两种用于跨模态学习联合表示的对比学习CL的框架进行模型的预训练。一种为标准成对的 CL,另外一种为Leave-One-Out CL(上图)。
在这里有三种模态,也就是在同一时间有三个相匹配的输入。Leave-One-Out构建对比学习样本时,将其中的两个输入与余下的输入构成样本对,如此可以从一个片段构建出三个样本对。
关键的指导思想将来自不同模态的正匹配对在Embedding空间中拉近,同时拉开负匹配对。这里正匹配来自不同模态的经过时间对齐的30秒数据块。其余的所有都被视为负匹配对。
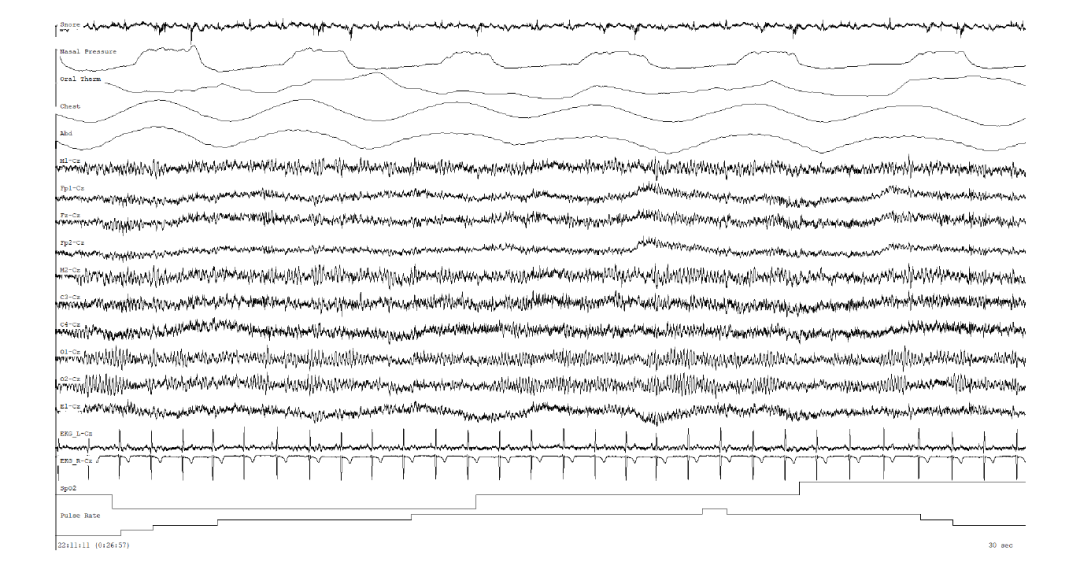
按照睡眠研究中使用的标准剪辑持续时间,将所有参与者的总睡眠持续时间细分为连续的 30 秒剪辑。然后将数据集重新采样为 256Hz,以标准化所有参与者的采样率。此外,专业的睡眠技术人员为睡眠阶段和 SDB的每个剪辑贴上了标签。
模型预训练涉及使用设置为0.001的初始学习率和0.9的动量来最小化随机梯度下降的对比损失。学习率每5个周期衰减10倍。可训练的温度参数初始化为0。训练最多跨越20个周期,并根据验证损失提前停止,采用 32 个批处理大小,并在每个周期验证检查点以确保稳健的正则化。
通过这种自监督方法完成预训练后,利用学习到的模态编码器为训练、验证和测试集生成Embedding。随后利用Embeding来进行分类器训练。
大白话就是这里其实重点在于多模态的对齐,然后使用这个基础模型再去进行睡眠阶段分类和 SDB事件检测的模型训练。下图为利用SleepFM去做下游任务的表现。
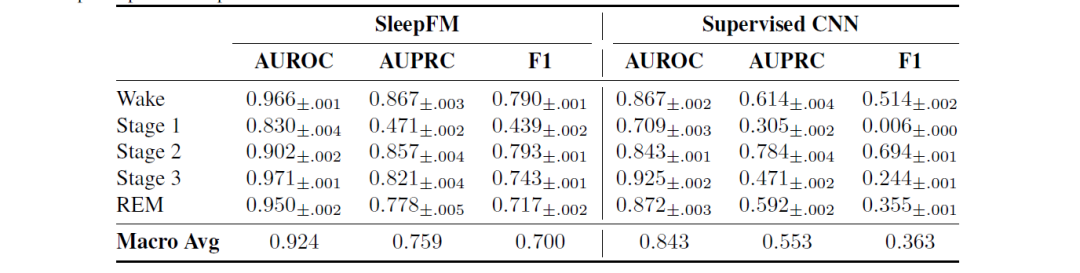
小编认为该模型的成功主要归功于它能够学习丰富的多模态生理数据表示,这对于准确的睡眠分析至关重要。
而且SleepFM在人口统计学属性分类方面也表现出色,在从30秒的生理数据片段中预测年龄和性别方面表现出很高的准确性。该模型在0-18岁、18-35岁、35-50岁和50+年龄组的AUROC分别为0.982、0.852、0.784和0.915。对于性别分类,AUROC为0.850,明显优于基线模型。
这篇关于SleepFM:利用对比学习预训练的多模态“睡眠”基础模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





