本文主要是介绍在“AI PC”中使用NPU运行 Phi-3-mini,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎关注我的公众号“ONE生产力”,获取更多AI、云计算资讯分享!
前段时间,我做了一系列微软Phi-3-mini小语言模型的教程,很多朋友参考教程进行了实践,其中有一个朋友反馈说模型token推理很慢,没有答道我说的可用程度。我询问了他的硬件配置,他说是才买的联想“AI PC”,配备了Intel Core Ultra 7处理器。这配置可比我用的7840HS强多了,但为何运行效果不佳呢?因为没有正确使用Intel Core Ultra处理器内置的NPU。
什么是NPU?
网上有很多人吐槽“AI PC”,说这个无非是装了一些AI应用,其实和硬件没关系,X79洋垃圾一样可以用。这话对也不对,确实目前大多数AI应用都依赖云服务,说白了,给个浏览器就能用;但是对于利用本地算力的应用,这些老志强可能就力不从心了,此时就轮到这些“AI PC”发力了。
例如这位朋友的“AI PC”装备的Intel Ultra处理器内置了NPU。NPU(神经处理单元)是大型 SoC 上的专用处理器或处理单元,专为加速神经网络操作和 AI 任务而设计。与通用 CPU 和 GPU 不同,NPU 针对数据驱动的并行计算进行了优化,使其在处理视频和图像等大量多媒体数据以及处理神经网络数据方面非常高效。他们特别擅长处理与 AI 相关的任务,例如语音识别、视频通话中的背景模糊以及物体检测等照片或视频编辑过程。
虽然许多 AI 和机器学习工作负载在 GPU 上运行,但 GPU 和 NPU 之间存在关键区别。GPU 以其并行计算能力而闻名,但并非所有 GPU 在处理图形之外都同样高效。另一方面,NPU 专为神经网络操作中涉及的复杂计算而构建,使其对 AI 任务非常有效。
下面,我们来看看如何通过朋友这颗Intel Core Ultra处理器内置的NPU来加速运行Phi-3模型。
安装Intel NPU 加速库
Intel NPU 加速库 https://github.com/intel/intel-npu-acceleration-library 是一个 Python 库,旨在通过利用Intel神经处理单元 (NPU) 的强大功能在兼容硬件上执行高速计算来提高应用程序的效率。
使用 pip 安装 Python 库
pip install intel-npu-acceleration-library使用Intel NPU 加速库运行 Phi-3
1、使用Intel NPU 加速库量化原始 Phi-3 模型
from transformers import AutoTokenizer, TextStreamer, AutoModelForCausalLM,pipelineimport intel_npu_acceleration_libraryimport torchmodel_id = "microsoft/Phi-3-mini-4k-instruct"model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", use_cache=True,trust_remote_code=True).eval()tokenizer = AutoTokenizer.from_pretrained(model_id)print("Compile model for the NPU")model = intel_npu_acceleration_library.compile(model, dtype=torch.float16)2、量化成功后,继续执行调用 NPU 运行 Phi-3 模型。
pipe = pipeline("text-generation",model=model,tokenizer=tokenizer,)generation_args = {"max_new_tokens": 500,"return_full_text": False,"temperature": 0.0,"do_sample": False,}query = "<|system|>You are a helpful AI assistant.<|end|><|user|>Can you introduce yourself?<|end|><|assistant|>"output = pipe(query, **generation_args)output[0]['generated_text']3、在执行代码时,我们可以通过任务管理器查看NPU的运行状态:
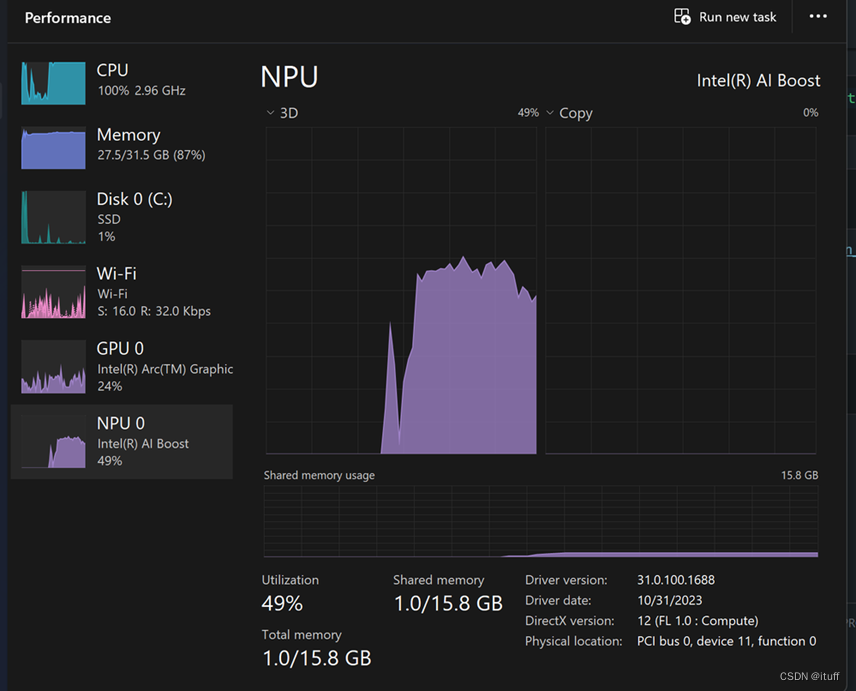
这篇关于在“AI PC”中使用NPU运行 Phi-3-mini的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





