本文主要是介绍【鱼眼镜头11】Kannala-Brandt模型和Scaramuzza多项式模型区别,哪个更好?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kannala-Brandt模型和Scaramuzza多项式模型在描述鱼眼相机畸变时都有其特定的数学表示和应用,但它们之间存在一些区别。以下是对两者区别的分点表示和归纳:
-
数学表示:
- Kannala-Brandt模型:它假设图像光心到投影点的距离和角度的多项式存在比例关系。具体地,它涉及到相机坐标系、图像坐标系、物点坐标、入射角、畸变像点和非畸变像点等参数,并通过这些参数之间的关系来描述径向畸变。
- Scaramuzza多项式模型:此模型通常采用多项式函数来描述相机镜头的畸变,特别适用于鱼眼相机。通过选择适当的多项式阶数,它可以模拟不同类型的鱼眼相机畸变。多项式中的系数通常需要通过相机标定来确定。
-
应用与特点:
- Kannala-Brandt模型:由于其特定的数学假设,它适用于描述鱼眼相机的径向畸变。该模型能够很好地处理鱼眼相机由于极端短焦和广角而产生的剧烈畸变。
- Scaramuzza多项式模型:由于其多项式形式的灵活性,它可以模拟包括鱼眼相机在内的多种类型相机的畸变。通过调整多项式的阶数和系数,它可以适应不同品牌和型号的鱼眼相机。
-
参数确定:
- 对于两种模型,其参数(如多项式系数)通常需要通过相机标定来确定。标定过程通常包括拍摄一组已知空间坐标的标定物图像,并通过最小化标定物上点的实际坐标与其在图像上的投影坐标之间的差异来求解模型参数。
-
适用范围:
- 两者都主要用于鱼眼相机的畸变建模,但Kannala-Brandt模型由于其特定的假设可能更适合于处理某些类型的鱼眼相机畸变,而Scaramuzza多项式模型则由于其灵活性而具有更广泛的应用范围。
总结来说,Kannala-Brandt模型和Scaramuzza多项式模型在描述鱼眼相机畸变时都有其独特的方法,但它们在数学表示、应用特点、参数确定和适用范围等方面存在差异。选择哪种模型取决于具体的应用场景和需求。
谁更好?
在比较Kannala-Brandt模型和Scaramuzza多项式模型哪个更好时,需要考虑多个因素,包括模型的适用性、灵活性、准确性以及是否支持自动标定等。以下是对这两个模型的比较和分析:
-
适用性:
- Kannala-Brandt模型:该模型能够很好地适用于普通、广角以及鱼眼镜头,特别是在处理鱼眼相机的径向畸变时表现出色。然而,它主要关注径向畸变的建模,对于其他类型的畸变可能不够准确。
- Scaramuzza多项式模型:此模型采用泰勒多项式来建模,可以同时适用于catadioptric(相机+镜子)和dioptric(鱼眼)两种全向相机。它不仅可以模拟径向畸变,还可以模拟其他类型的畸变,因此具有更广泛的适用性。
-
灵活性:
- Kannala-Brandt模型:由于其特定的数学假设和参数设置,可能对于某些特定类型的鱼眼相机具有较好的建模效果,但对于其他类型的相机可能需要调整或修改模型。
- Scaramuzza多项式模型:通过选择不同阶数的多项式,该模型可以灵活地适应不同类型的鱼眼相机和折反射相机。此外,它还可以适应市场上各种鱼眼镜头,其视野可达195度。
-
准确性:
- 准确性在很大程度上取决于模型参数的标定和图像数据的质量。由于两个模型都经过了广泛的实验验证和应用,因此在适当的应用场景下都可以获得相对准确的标定结果。然而,对于特定的相机和镜头,可能需要根据实际情况选择更适合的模型。
-
自动标定:
- Kannala-Brandt模型:文章中没有明确提到该模型是否支持自动标定。通常情况下,模型参数的标定需要手动进行或依赖于特定的标定软件。
- Scaramuzza多项式模型:该模型所在的工具箱提供了自动标定功能,即畸变中心和标定点都是自动检测的,无需用户干预。这使得标定过程更加简便和高效。
综上所述,Scaramuzza多项式模型在适用性、灵活性和自动标定方面具有优势。然而,在实际应用中,还需要根据具体的相机类型、镜头参数和应用场景来选择最适合的模型。此外,还需要注意标定数据的准确性和可靠性对于模型性能的影响。
径向畸变表式沿半径方向的偏移量, 径向畸变的形成原因是镜头制造工艺不完美,使得镜头形状存在缺陷, 通常又分为桶性畸变和枕形畸变,dr 分别代表 往外偏和往里偏.
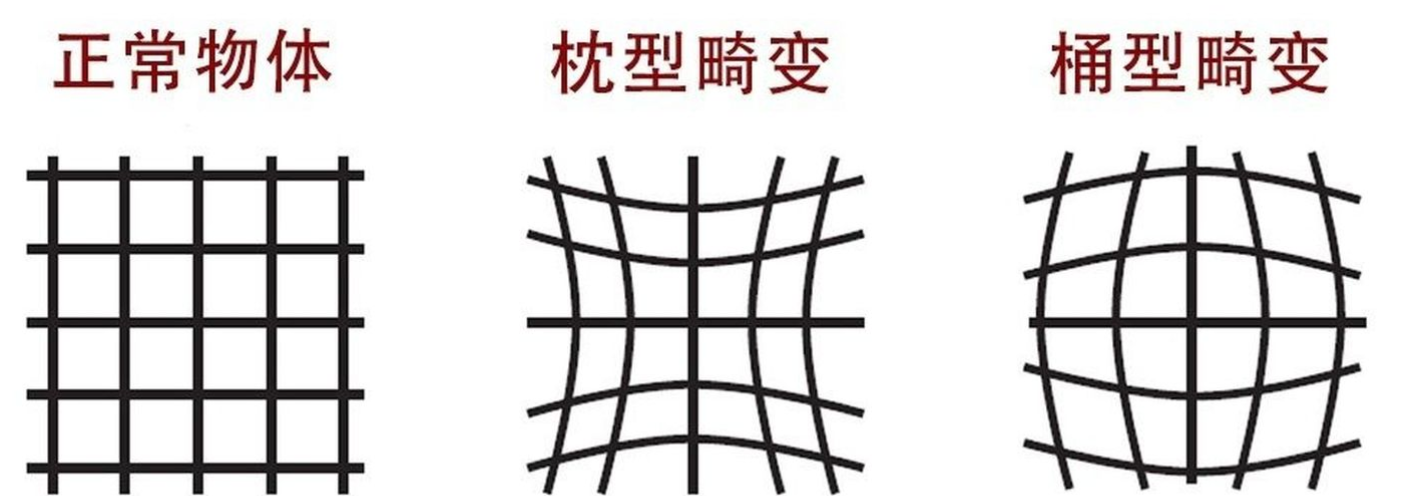
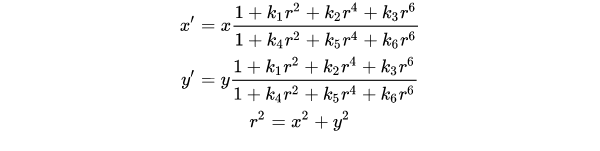
上述内容的理解你需要阅读博客
【鱼眼镜头9】论文Omnidirectional Camera,鱼眼是全向相机的折射相机的一种重要类型,满足单一有效视点的特性, Taylor模型(适用于鱼眼相机),统一投影模型(在鱼眼应用受限)
这篇关于【鱼眼镜头11】Kannala-Brandt模型和Scaramuzza多项式模型区别,哪个更好?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







