51job专题

企业招聘采集算法(58,51job,海南在线,智联招聘,百度招聘,猎聘网)
招聘功能与算法 1.采集招聘列表页,请求API接口,去重后存入数据库,自动点击下一页 采集:职位,企业职位id,企业id。 职位表,企业表 2.自动遍历职位详情表,企业详情表,企业职位表。并入库。 3.根据ID自动采集企业信息 4.封装不同招聘网配置函数 资源地址 猎聘网 58招聘 51job 琼州人才 智联招聘 招聘任务 帮助找IOS,安卓,测试,

Python3.6爬虫集合 xpath bs4 re 爬51job前程无忧招聘信息 豆瓣音乐等等
总结一下这两天自己写的爬虫,之前一直用框架爬虫,感觉有必要熟练最基础的没有框架爬虫才能让我更好理解框架,代码在链接内,代码中都有详细的注释 1. 发送邮件,这里选择发送网页邮件,其他邮件发送可以看廖雪峰老师的教程 * 邮件协议为SMTP,端口为25 * 需要模块 email(构造邮件) smtplib(发送邮件) * 代码传送门 * 无具体

为什么51job这么牛? 具有很多改进功能的招聘网站有大的机会吗? - 日常的商业模式思考...
[img]http://images.51job.com/im/mk/artimages/100522.jpg[/img] 忽然大家都谈起了51job, 那我也说几句, 请大伙拍砖. 网上招聘这事情就像Robin说的,水很深. 为什么这么简单的技术和操作能做出来的生意,水这么深? 让我扎下去,摸摸底,说说感觉。 一般而言,市场可以简单地分为商品市场和生产要素市场. 生产

简单使用requests_html模块爬取51Job招聘网的招聘数据
前言 本菜鸡是python和html初学者,此文记录一下学习历程,并希望可以给有需要的同好提供一点思路。这个程序只是简单的使用了requests_html库,所以效率可能不是很高。 requests_html库介绍 库安装指令:pip install requests_html 思路 打开想要爬取的网站进行分析 https://jobs.51job.com/all/以爬取不同的行业

第一天打卡:异步爬虫 51job网
网址(首页):滑动验证页面 如图1所示: 查看所需数据是否存在于网页源代码中,发现需要的数据存在用javascript所写的脚本中,不可直接用原始URL获取数据,如下图所示: 如何寻找所需数据? 步骤一:如图所示,在network中清除,重新加载网页 步骤二:如下图所示,查看返回的是否是json文件(用在线json解析,看格式“集合”) ,发现里面包含了json,即我们所
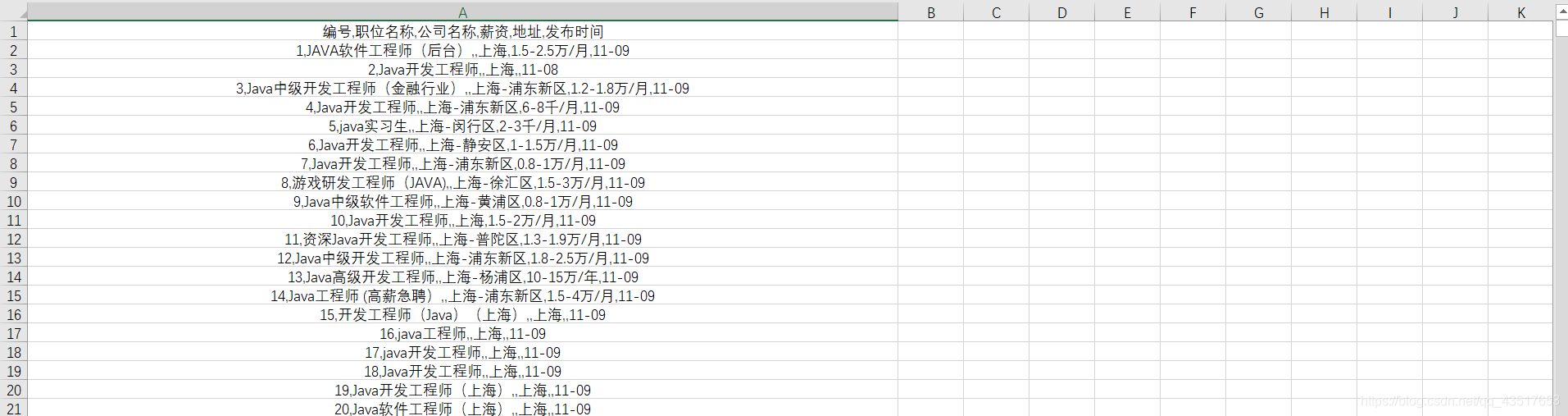
python爬虫之XPath(爬取51job招聘信息)
目录 xpath简介爬取51job招聘信息 xpath简介 前面介绍了这么多种解析网页的方式,今天再来介绍一种xpath, XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。 它可以确定元素在XML中的位置,同样我们也可以用它来获取dom节点在html中的位置,就可以便利我们爬取数据 这是今天大概内容的简介 我

【招聘乱想】 51job,日本人,天上人间和花姑娘
4月6日 近日看了2则消息。一个是“ 天上人间在51job的招聘广告”,另一个是“ 日本资本收购51job” 。我感觉这些都是对51job这样的上市公司的非利好新闻。本人对日本国和中国娱乐界的典范都谈不上特别的厌恶,但是以51job在中国人力资本招聘界影响和地位来看,我总是心里觉得非常不爽。 地球人都知道21世纪最贵的就是人才,人才的信息价值可想有多么珍贵! 51job作为一个公开在

爬虫——Python 爬取51job 职位信息
既然要爬取职位信息,那么首先要弄清楚目标页面的分布规律。 输入职位关键词和相应的地点等条件,然后搜索就可以看到岗位信息。 首先通过翻页来查看url的变化,以此来找到翻页时url的规律 把前面几页的url 复制下来放到文本文档里对比 不难发现除了页码外其他都没有改变 下面开始代码 # 导入相应的包#-*-coding:utf-8-*-from bs4 import Beautif
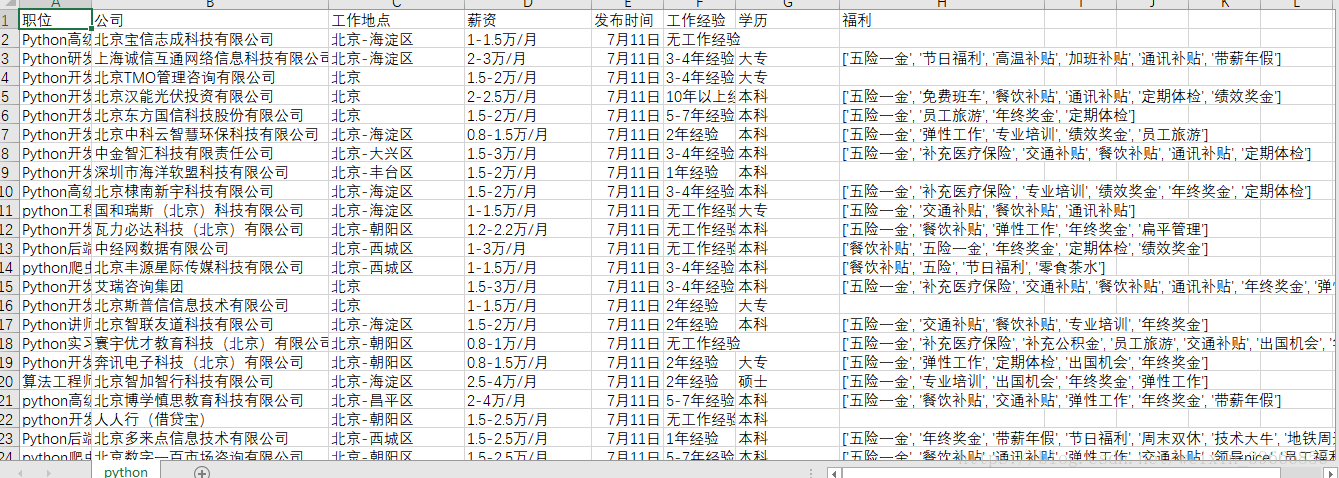
Python爬虫爬取51job招聘网站
最近学习爬虫,做了一个python爬虫工具写在这里记录一下。 # python爬51job工具,稍微改改就可以爬其他网站# edit by mengqi Date:2018-07-11# encoding:uft-8import csv # 爬下来的数据要写到csv文件中,所以要引入这个模块from urllib import request, errorf

java 爬取51job招聘信息
本案例是基于webmagic和jsoup对51job招聘信息的爬取,并将爬取到的数据存入mysql数据库中。 Jsoup jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 jsoup的主要功能如下: 从一个URL,文件或字符串中解析HTML;使用DO


Python采集51job招聘信息
前言 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。 很多人学习python,不知道从何学起。 很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。 很多已经做案例的人,却不知道如何去学习更加高深的知识。 那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤QQ群:96156
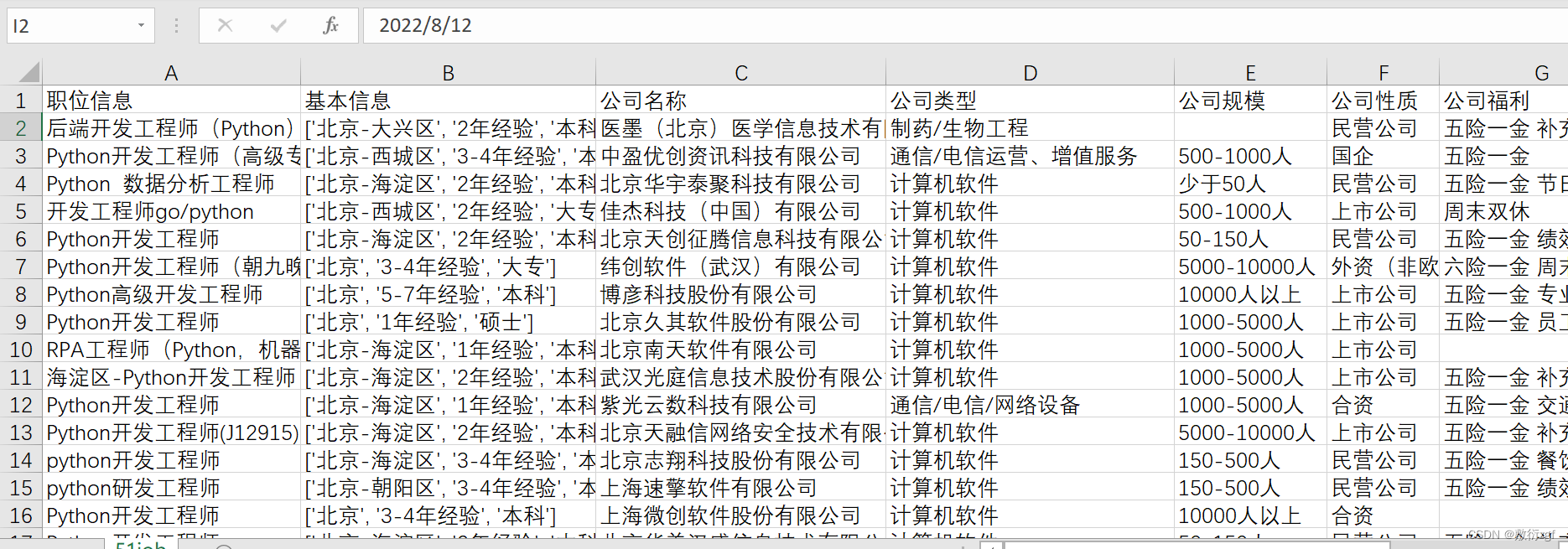
Python_51job案例分析
import csvimport timeimport requestsimport re # 正则表达式 内置模块,不用安装import jsonimport pprint # 可视化输出 按照一定格式输出f = open('51job.csv',mode='a',encoding='ANSI',newline='')csv_writer = csv.DictWriter(f,fiel
关于scrapy爬取51job网以及智联招聘信息存储文件的设置
通过这两个文件,,可以存储数据(但是注意在爬虫文件中也在写相应的代码 具体参考51job网和智联招聘两个文件) 1.先设置items文件 # -*- coding: utf-8 -*-# Define here the models for your scraped items## See documentation in:# https://doc.scrapy.org/en

基于Python的前程无忧、51job、智联招聘等招聘网站数据获取及数据分析可视化大全【代码+演示】
需要本项目的可以私信博主,获取,或者文末卡片获取 import pandas as pdimport globimport warningswarnings.filterwarnings("ignore")# 指定目录directory = './data/'# 使用glob来获取所有.xlsx文件excel_files = glob.glob(directory + '*.xls

换坑季-51Job前程无忧 Python爬虫
写了个简易的Python爬虫,实现对目的工作的分析。 说明,只用了正则re库进行数据处理,requests进行请求,开了4个简易的函数线程。 url是以下界面的url: 主要实现了以下CSV功能: 全部代码: import requestsimport reimport csvfrom threading import Threaddef req(i):count = 1try:for

Python网络爬虫(一):爬取51job前程无忧网数据并保存至MongoDB数据库
Python网络爬虫(一):爬取51job前程无忧网数据并保存至MongoDB数据库 前言 参考博客: link.Python爬虫(7):多进程抓取拉钩网十万数据: 版本:Python3.7 编辑器:PyCharm 数据库:MongoDB 整体思路: 1.网页解析,查找所需信息的位置 2.开始网页爬取 3.爬取结果存入MongoDB数据库 爬虫 1.网页解析 打开网页后发现共有四大类
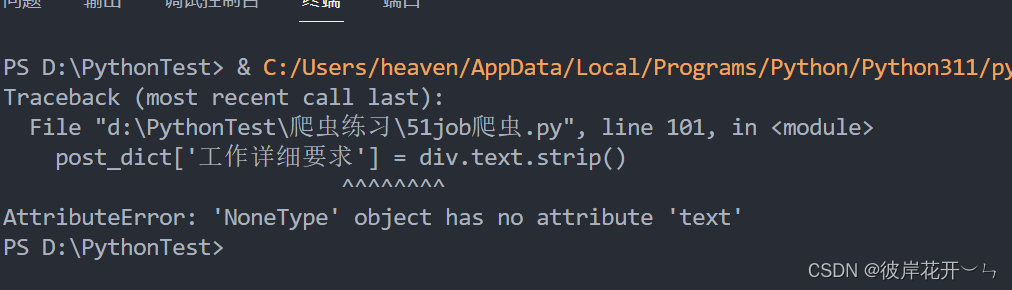
51job爬虫的一些问题
各位大佬,我想爬取51job的求职详细信息,具体要求是进入官网搜索数字化管理,进到搜索结果页 获取里面的职位名称,薪资等信息,再点击进入每个职位的详细页面,获取里面的岗位职责等具体要求, 我写了一个代码,可以爬取第一个搜索页的 职位名称和薪资等信息,但进到详细页的时候 无法获取详细页的岗位职责等具体信息。 报错信息如下: import requestsimpo

51JOB上海地区java招聘职位分析(二)
前段时间发表了51JOB上海地区java招聘职位分析引起了大家的共鸣,其中有赞成的,也有反对的,也有消极的,也有人提出了比较很好的见解,总之无论是什么笔者都欢迎各位朋友提出宝贵的意见,笔者一定会认真阅读大家的留言。 但是我想,在我们争论,谩骂之后问题总是要解决的。各位朋友,特别是已经毕业或者即将毕业的朋友工作还是要找的。有人说51JOB上面的招牌企业是骗人的,有
爬虫实战(二) 51job移动端数据采集
在上一篇51job职位信息的爬取中,对岗位信息div下各式各样杂乱的标签,简单的Xpath效果不佳,加上string()函数后,也不尽如人意。因此这次我们跳过桌面web端,选择移动端进行爬取。 一、代码结构 按照下图所示的爬虫基本框架结构,我将此份代码分为四个模块——URL管理、HTML下载、HTML解析以及数据存储。 二、URL管理模块 这个模块负责搜索

抓取前程无忧51job岗位数据,实现数据可视化——心得体会
最近找工作,经常浏览51job,刚好学了python一段时间了,所以有了一个想法:为什么不将我需要的岗位信息给爬出来呢? 在51job网站搜索“数据分析师”,查看源代码,发现每一个招聘公告包含岗位、公司、薪资、地区等信息。所以可以实现如下几个目的: 1.根据关键词抓取招聘信息; 2.连接mysql,创建表格,并插入数据; 3.初步清洗数据,实现可视化 一、网页抓取函数 https:
桌底下的需求(转自51job)
最近,销售员小陈觉得越来越吃力,几个单子相继在招标中落败。在经典的“顾问式销售”技巧——锁定关键人物、掐痛点、目标分解等的攻势下,精明的客户已渐渐有了免疫力。小陈向销售总监洋泾浜抱怨:“我们该做的都做了,效果却见不到。”老洋问:“顾问式销售的核心是为客户提供价值,你是如何做的?” 小陈答道:“我做的完全符合目标分解模式:根据客户方最高管理层确定的总目标,给下级部门依次做目标分解,最后
51JOB上海地区java招聘职位分析
临近毕业,总是有很多人特别是即将毕业的朋友老是问我如何找工作云云。说实在话这些问题还真是难回答,说好找吧,对方马上急问是否能帮忙吧,我可没有那么大本事;说不好找吧,对方急问有什么办法,我可没有什么好办法,否则我早就发了。 今天因为帮公司人士找人所以到51JOB上面逛了一圈。由于职业习惯不小心搜索了一下关键字java,结果出来一窜招聘信息,于是便仔细分析了一下。先将
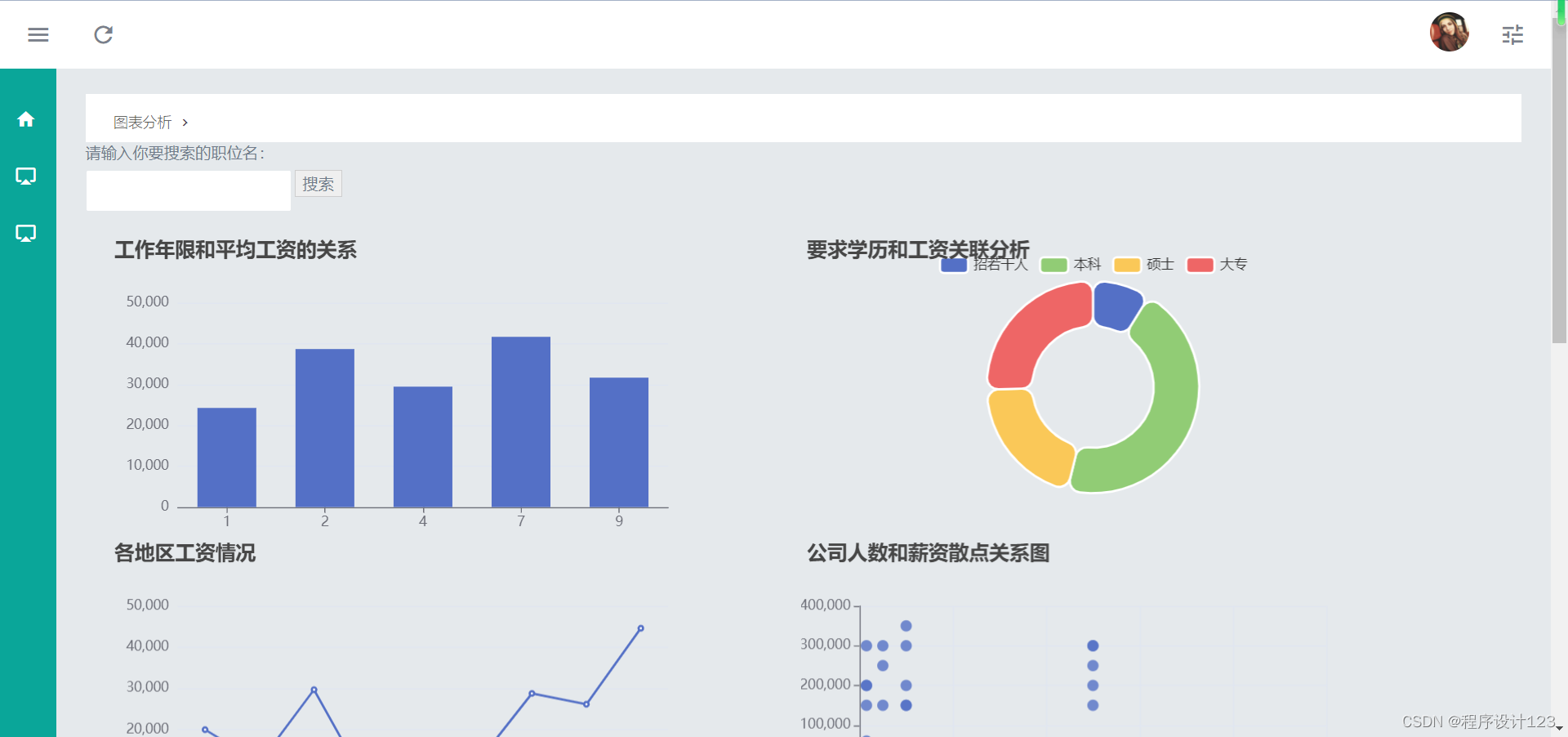
基于Python的51job的招聘信息可视化分析系统的设计与实现
开发工具(eclipse/idea/vscode等):pychram 数据库(sqlite/mysql/sqlserver等):sqlite或者mysql 功能模块(请用文字描述,至少200字): 1 用户登录功能 2 用户注册功能,输入有效的邮箱进行注册。可以接收注册邮箱验证。 3.数据查看功能,可以查看各种招聘信息,并且可以搜索查看和分页查看 4 爬虫功能,使用爬虫对数据进行爬取,使用pand