本文主要是介绍python爬虫之XPath(爬取51job招聘信息),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- xpath简介
- 爬取51job招聘信息
xpath简介
前面介绍了这么多种解析网页的方式,今天再来介绍一种xpath,
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
它可以确定元素在XML中的位置,同样我们也可以用它来获取dom节点在html中的位置,就可以便利我们爬取数据
这是今天大概内容的简介
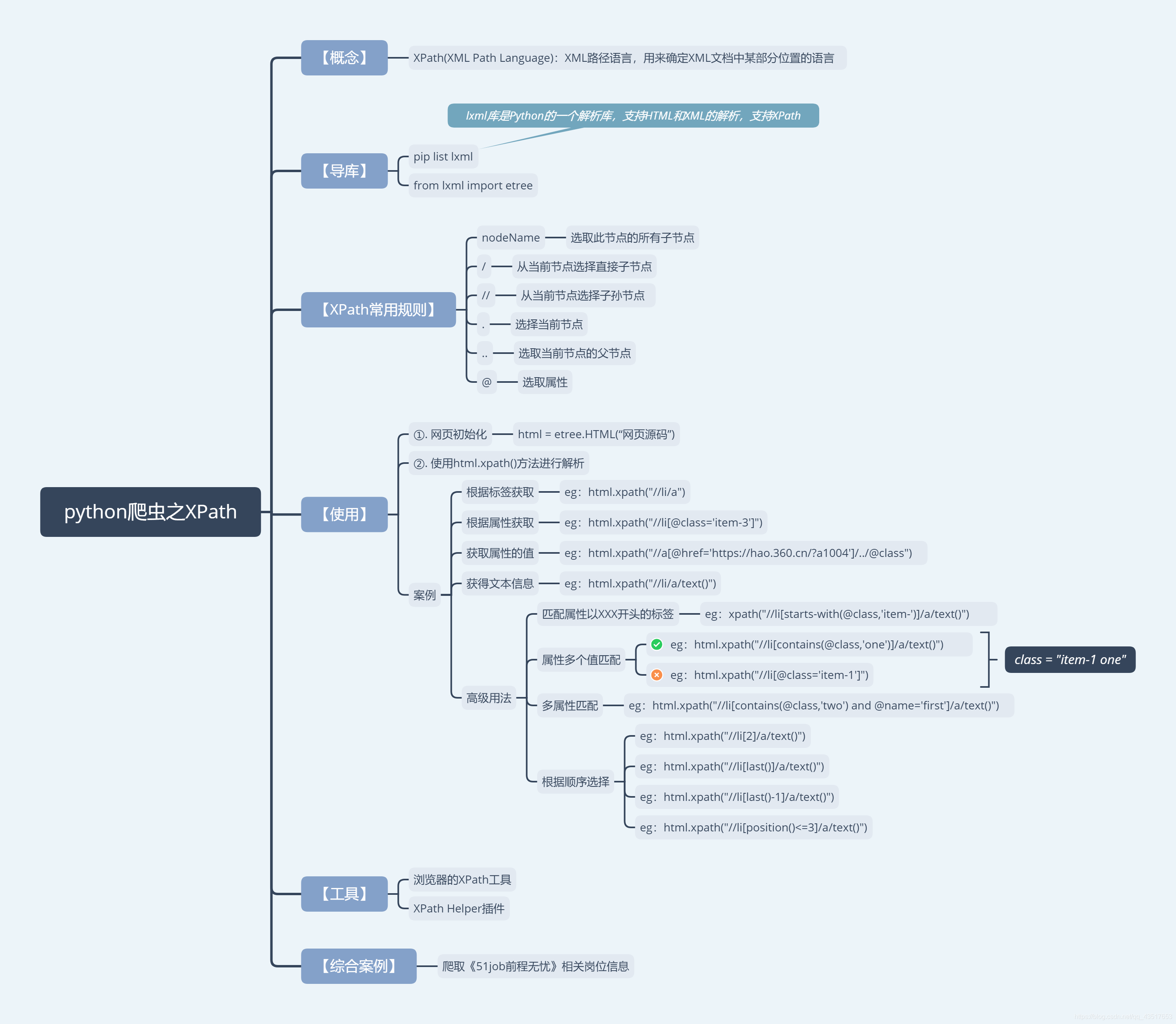
我在这里也就不详细介绍XPath的语法了,介绍一些我们够用的就行,想了解自己去看API了:https://www.w3school.com.cn/xpath/index.asp
| nodename | 选取此节点的所有子节点。 |
|---|---|
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
至于语法当然可以不需要我们自己手动写,我们可以利用浏览器的工具,就哪CSND来举例子,我要获取左侧导航‘程序人生’这个标签的xpath路径
首先要利用浏览器的元素选择器,找到它的html位置

然后我们选择我们要的元素右击copy XPath,
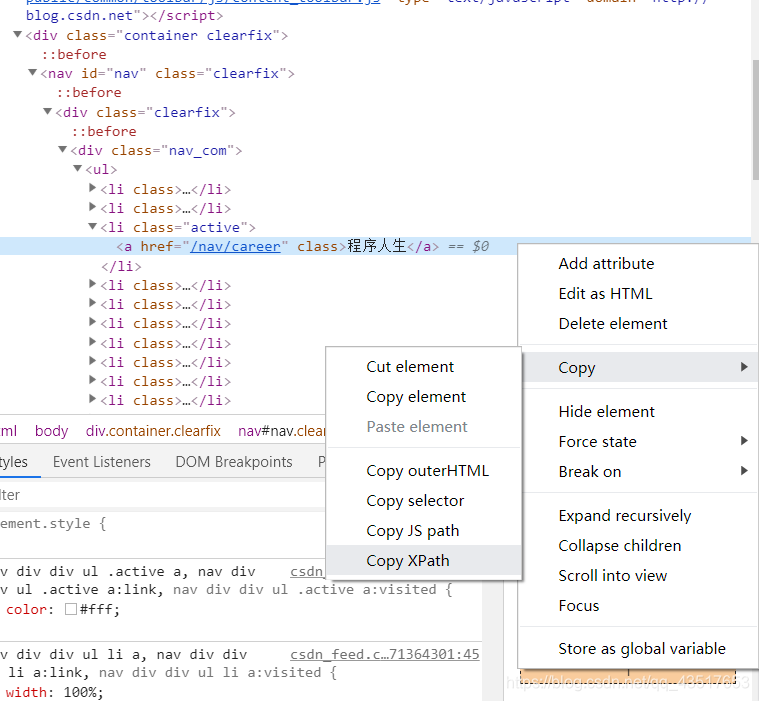
然后我们粘贴下来://*[@id=“nav”]/div/div/ul/li[3]
这就是程序人生的XPath路径,然后我们就能根据这个来爬取它的这一整块的信息了,后面我的案例就是这样做的
爬取51job招聘信息
案例就直接上代码了,思路都大同小异,分析信息的页面、页码、元素等等,然后写代码
"""
爬取 51job 相关职位信息,并保存成cvs文件格式
"""
import requests
from lxml import etree
import csv
# csv后缀的格式就是excel文件打开的格式,我们等于是直接存入了excel中
import timeheaders = {"User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14"
}f = open("java职位.cvs","w",newline="")
writer = csv.writer(f)
writer.writerow(['编号', '职位名称', '公司名称', '薪资', '地址', '发布时间'])i = 1;
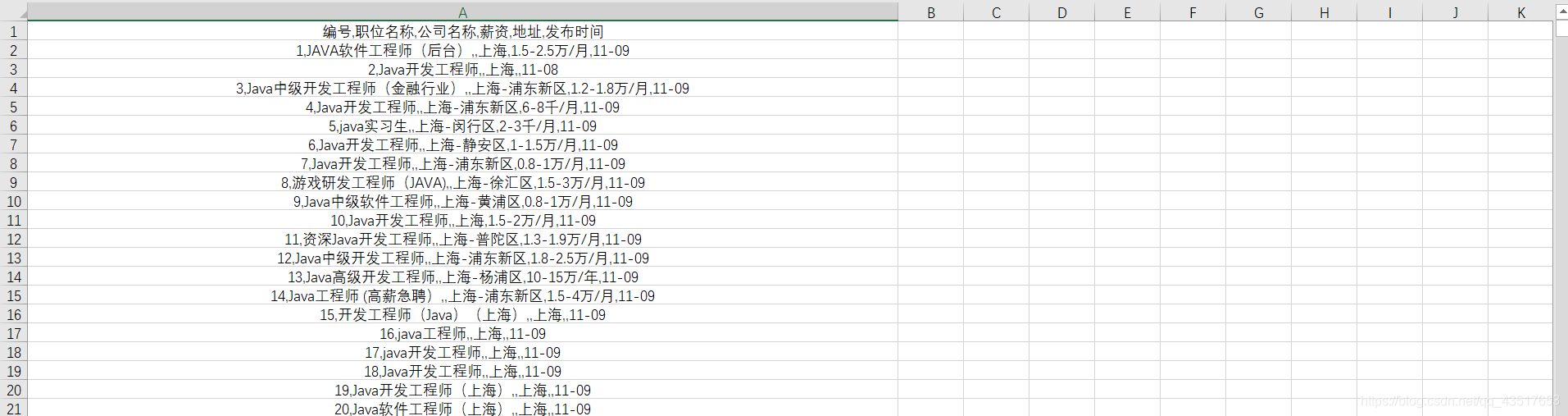
for page in range(1,159):requests_get = requests.get(f"https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=",headers=headers)requests_get.encoding="gbk"if requests_get.status_code == 200:html = etree.HTML(requests_get.text)els = html.xpath("//div[@class='el']")[4:]for el in els:jobname = str(el.xpath("p[contains(@class,'t1')]/span/a/@title")).strip("[']")jobcom = str(el.xpath("span[@class='t2']/a/@titlr")).strip("[']")jobaddress = str(el.xpath("span[@class='t3']/text()")).strip("[']")jobsalary = str(el.xpath("span[@class='t4']/text()")).strip("[']")jobdate = str(el.xpath("span[@class='t5']/text()")).strip("[']")writer.writerow([i, jobname, jobcom, jobaddress, jobsalary, jobdate])i += 1print(f"第{page}页获取完毕")最后存入excel中的样子
end…
这篇关于python爬虫之XPath(爬取51job招聘信息)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




