xpath专题

![[Xpath] Xpath基础知识](https://i-blog.csdnimg.cn/direct/5b06e4310b5e4c31a6ac7169c8c9d2c2.png)
[Xpath] Xpath基础知识
1.Xpath(XML Path Language)介绍 Xpath用于在HTML文档中通过元素(HTML标签)和属性(HTML标签的属性)进行数据定位 Xpath的优势:灵活且稳定 HTML树状结构 HTML的结构是树形结构,HTML是根节点,所有的其他元素节点都是从根节点发出的,其他元素都是这棵树上的节点Node,每个节点还可能有属性和文本 所有的HTML标签都有很强的

爬虫二:获取豆瓣电影Top250(Requests+XPath+CSV)
描述: 在上一篇获取豆瓣图书Top250的基础上,获取豆瓣电影Top250的数据并将结果写入CSV文件中。 代码: # -*- coding: UTF-8 -*-import requestsfrom lxml import etreeimport timeimport csv# 从网页上获取电影数据moviedata = []count = 0for i in range(1

爬虫一:获取豆瓣图书Top250(Requests+XPath)
目的: 获取豆瓣图书Top250的所有书目信息。 豆瓣网址:https://book.douban.com/top250 代码: import requestsfrom lxml import etreeimport timefor i in range(10):url = 'https://book.douban.com/top250?start=' + str(25*i)data

HtmlCleaner无法通过XPath获取到数据
通过浏览器F12,选取的Xpath路径有时无法定位到目标即:objects为空,无法通过XPath获取到数据。 原因分析: 不同浏览器获取到的XPath不同XPath路径中有tbody标签Xpath路径有html,示例: Xpath: /html/body/div[2] 希望获取的数据是动态加载的 Xpath路径规则介绍: 语法 选取结点 表达式描述/从根节点选取//从匹配选择的当
爬虫工具:浅谈HtmlCleaner+XPath解析HTML
现在常用的网页解析工具有:Jsoup,JsoupXpath,HtmlCleaner。 jsoup 是一款Java 的XML、HTML解析器,可直接解析某个URL地址、HTML文本内容和已经存在的文件。 JsoupXPath是基于Jsoup的拓展,使用路径的形式解析XML和HTML文档。核心类为JXDocument;JsoupXPath的节点对象JXNode不仅可以获取标签节点,还可以获取属性节

BeautifulSoup4通过lxml使用Xpath定位实例
有以下html。<a>中含有图片链接(可能有多个<a>,每一个都含有一张图片链接)。最后一个<div>中含有文字。 上代码: import requestsfrom bs4 import BeautifulSoupfrom lxml import etreeurl='https://www.aaabbbccc.com'r=requests.get(url)soup = Beauti

打卡学习Python爬虫第五天|使用Xpath爬取豆瓣电影评分
思路:使用Xpath爬取豆瓣即将上映的电影评分,首先获取要爬取页面的url,查看页面源代码是否有我们想要的数据,如果有,直接获取HTML文件后解析HTML内容就能提取出我们想要的数据。如果没有则需要用到浏览器抓包工具,二次才能爬取到。其次观察HTML代码的标签结构,通过层级关系找到含有我们想要的数据的标签,提取出数据。最后保存我们的数据。 1、获取url 这里我们可以看到,有的电影是
爬虫的bs4、xpath、requests、selenium、scrapy的基本用法
在 Python 中,BeautifulSoup(简称 bs4)、XPath、Requests、Selenium 和 Scrapy 是五种常用于网页抓取和解析的工具。 1. BeautifulSoup (bs4) BeautifulSoup 是一个简单易用的 HTML 和 XML 解析库,常用于从网页中提取数据。 它的优点是易于学习和使用,适合处理静态页面的解析。 安装 BeautifulS

dom4j与xpath
DOM4J与Xpath~ (2007-06-18 17:05:20) 转载▼ 标签: dom4j xpath 分类: 学习 今天的笔记: 要从 XML 文档中提取信息,最快捷简单的办法就是在程序中嵌入 XPath 表达式。XPath是一种为查询 XML 文档而设计的查询语言(其他查询语言还包括结构化查询语言——SQL针对查询特定

Python网络数据抓取(9):XPath
引言 XPath 是一种用于从 XML 文档中选取特定节点的查询语言。如果你对 XML 文档不太熟悉,XPath 可以帮你完成网页抓取的所有工作。 实战 XML,即扩展标记语言,它与 HTML,也就是我们熟知的超文本标记语言,有相似之处,但也有显著的不同。HTML 有一套固定的标签,比如 body、head 或 p(段落),这些标签对于浏览器来说都有特定的含义。然而,XML 并不预设任何标签,你
深入理解XPath:从入门到精通
深入理解XPath:从入门到精通 引言 在Web自动化测试、网页数据抓取和XML文档处理等领域,XPath都是一种强大且常用的定位技术。通过XPath,我们可以精确定位和操作网页或XML文档中的元素。本文将详细介绍XPath的基本概念、语法、使用示例及高级用法,帮助你全面掌握XPath。 目录 XPath简介XPath基本语法XPath轴(Axes)XPath函数XPath运算符XPath

JavaWeb学习-XML系列-5-XML之XPath解析
上一篇学习了DOM4J里面的常见的解析文件和如何写一个xml文件内容。其实DOM4J这个开源的工具除了支持DOM解析之外,它还支持XPath解析,XPath解析也经常使用。这一篇,我们就来学习下如何通过xpath表达式来得到xml里面的内容。我们在Selenium UI自动化学习的时候经常使用xpath来定位元素,同样在一个xml里面,其实就是一个DOM树,从根节点开始,我们也可以通过路径的方式去
XSL 语言@等通配符,XPath等的说明
XSL 语言 2011-01-19 12:00:35 分类: XSL 指扩展样式表语言(EXtensible Stylesheet Language) CSS = HTML 样式表 HTML 使用预先定义的标签,标签的意义很容易被理解。 HTML 元素中的 <table> 元素定义表格 - 并且浏览器清楚如何显示它。 向 HTML 元素添加样式是很容易的。通过 CSS,很容易
dom4j中Xpath的应用
定义:XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。 此语言比较容易理解,仅举例: public voidbar(Document document) { //所有foo节点下的bar节点 List list =do
Chrome内验证xpath正确性
验证xpath也是类似的。语法是$x(“your_xpath_selector”)。 注意:语法中括号里需要通过双引号括起来,如果xpath语句中有双引号,要改成单引号,不然只能解析到第一对双引号的内容
页面元素定位 id 和 xpath 使用selenium IDE 浏览器插件获取
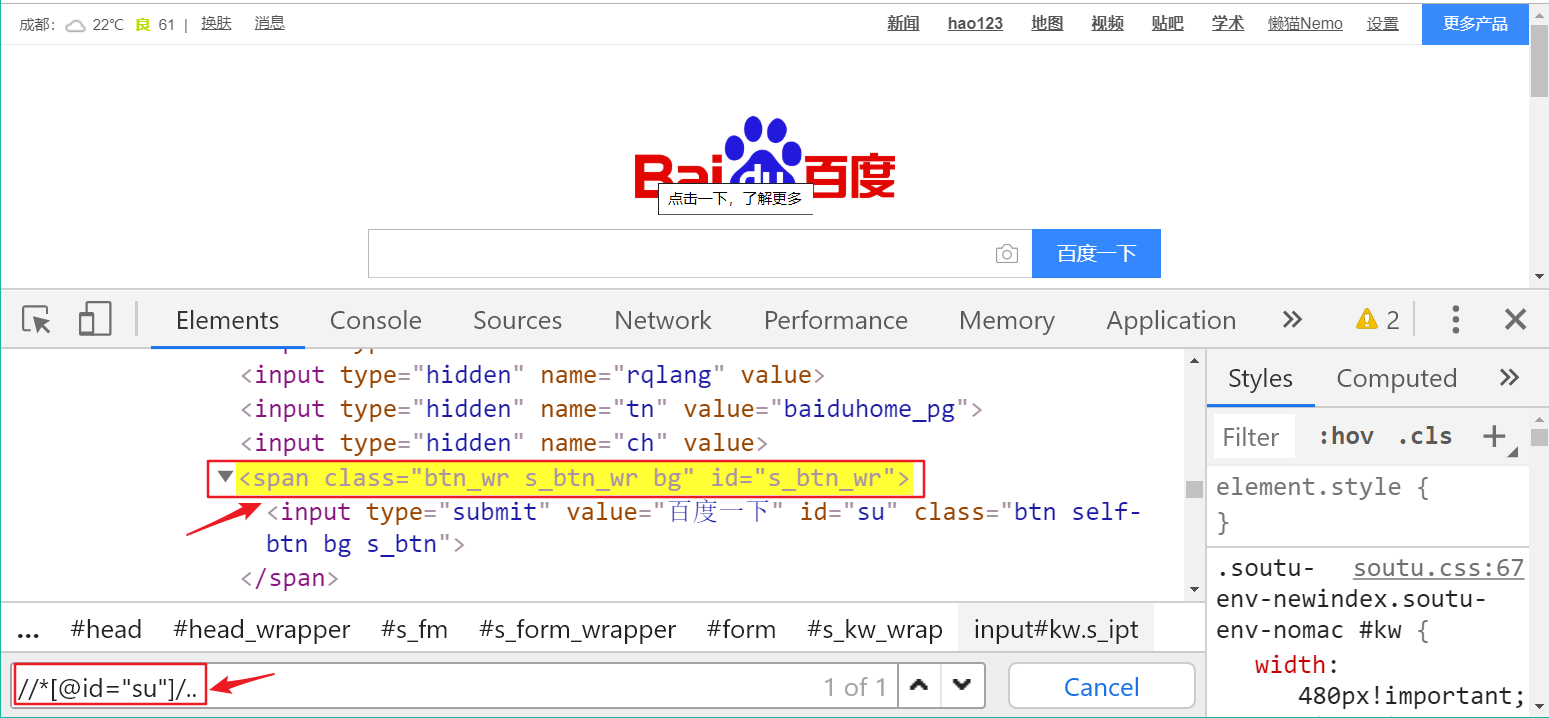
1. Chrome console 中验证xpath F12Ctrl + f方法一:element.//*[@id="su"]方法二:console$x("/html/body/script[1]") 参考: 1.如何在Chrome开发者工具或Firefox的Firebug中验证XPath表达式
【Python】【Scrapy 爬虫】理解HTML和XPath
为了从网页中抽取信息,必须对其结构有更多了解。我们快速浏览HTML、HTML的树状表示,以及在网页上选取信息的一种方式XPath。 HTML、DOM树表示以及XPath 互联网是如何工作的? 当两台电脑需要通信的时候,你必须要连接他们,无论通过有线方式 (通常是网线) 还是无线方式(比如 WiFi 或 蓝牙 )。所有现代电脑都支持这些连接。 但是当电脑多了,两两链接就会需要

使用chrome console检查css selector/xpath的有效性
定位元素时,一般用xpath或css selector来定位,定位时可以借助chrome浏览器或firefox浏览器的firebug来直接copy selector或copy xpath。此文介绍使用chrome怎样去验证css selector或xpath的有效性。 步骤 1. 按F12打开chrome的开发者工具; 2. 再按Esc键调出console 经过这俩步骤,chrome的E
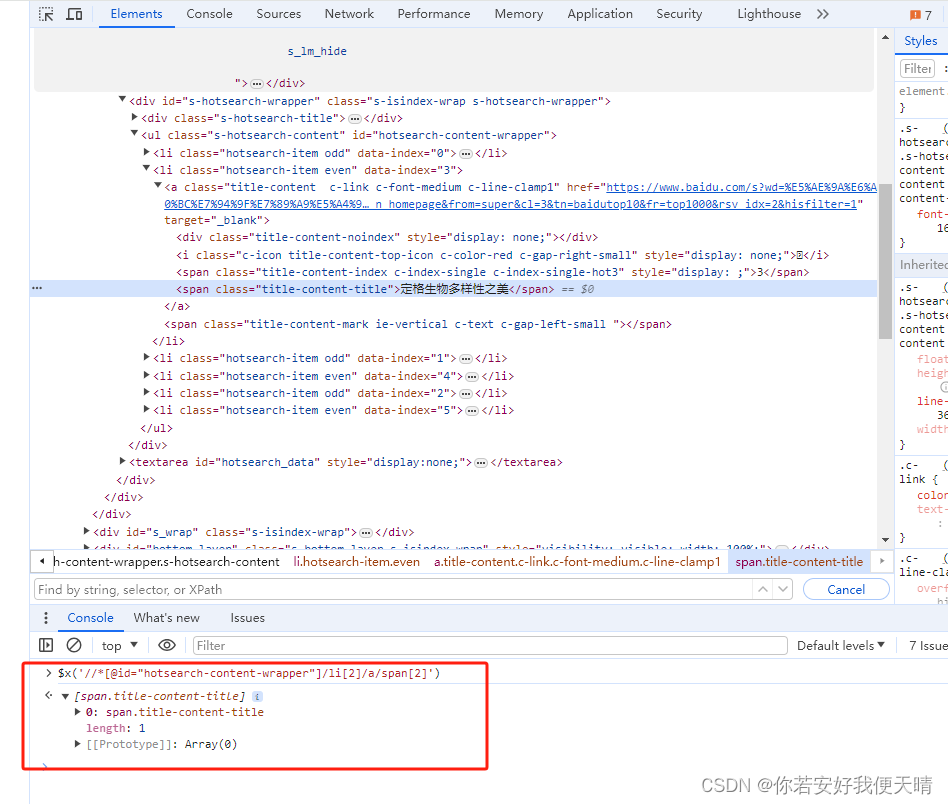
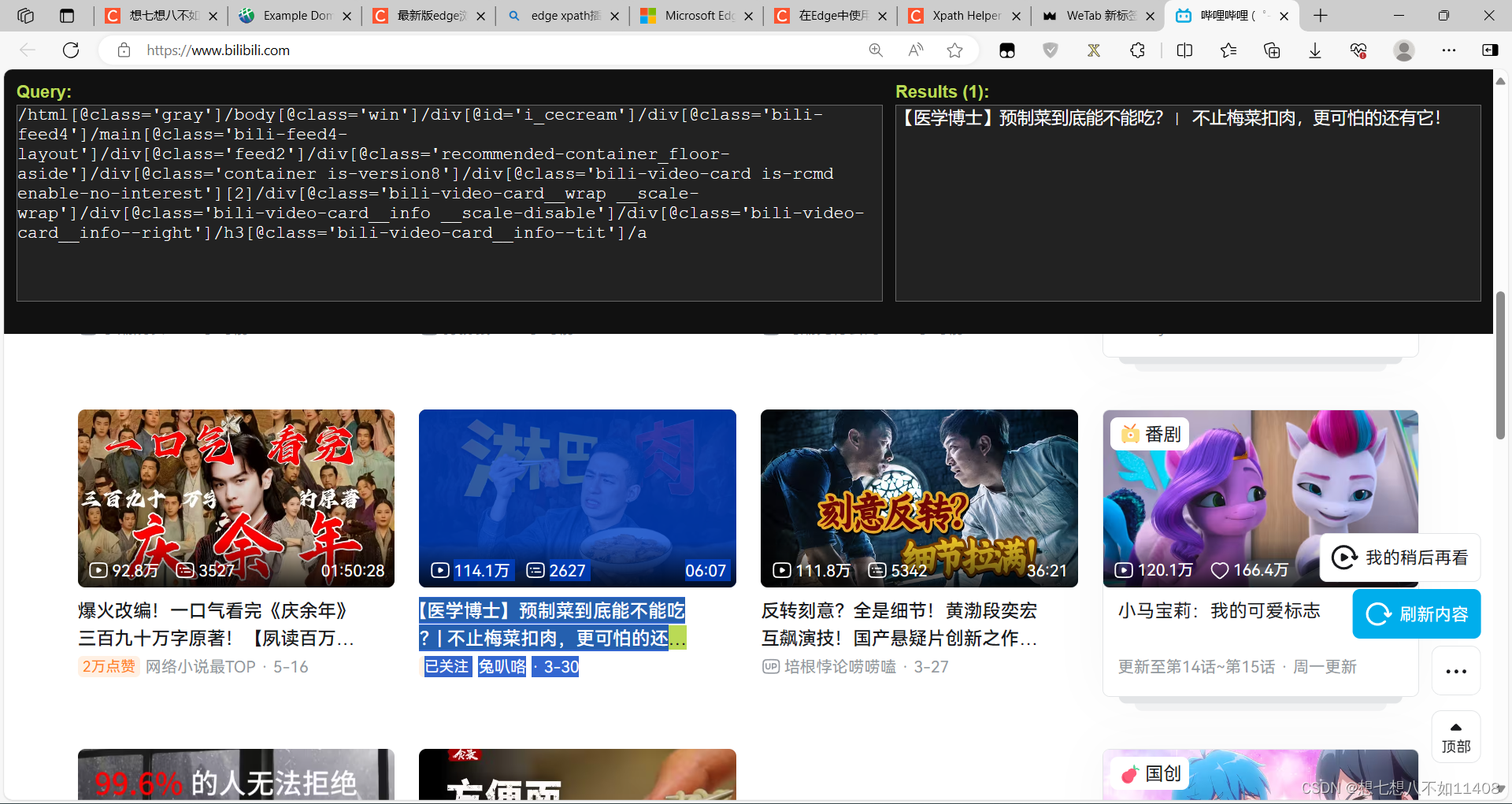
在chrome中查找和验证xpath
1、快速获取XPath表达式 按F12打开chrome浏览器的开发者模式,点击选择光标,选择页面上的元素位置,在控制台右键选择Copy XPath,表达式就复制到粘贴板中了。 获取到的xpath路径://*[@id="hotsearch-content-wrapper"]/li[2]/a/span[2] 获取到的full xpath路径:/html/body/div[2]/div[1
解析神器PK,花落谁家?Jsoup Or Xpath?
[b][color=green][size=large] 今天简单测了下使用Jsoup和Xpath解析XML的文件的方便程度,两者都可以完成解析,提取特定的元素或节点内容,但明显Jsoup更胜一筹,我们都知道Xpath是专业的xml结构化文档的查询语言,虽然语法功能强大,但是代码还是比较繁琐。虽然jsoup的出现,并不是专门用来解析XML使用的,但是使用jsoup这个轻巧的类库,我们可以完成网页

爬虫学习:XPath提取网页数据
目录 一、安装XPath 二、XPath的基础语法 1.选取节点 三、使用XPath匹配数据 1.浏览器审查元素 2.具体实例 四、总结 一、安装XPath 控制台输入指令:pip install lxml 二、XPath的基础语法 XPath是一种在XML文档中查找信息的语言,可以使用它在HTML源代码文档中通过元素、属性等方式进行
Python爬虫实战:爬取【某旅游交通出行类网站中国内热门景点】的评论数据,使用Re、BeautifulSoup与Xpath三种方式解析数据,代码完整
一、分析爬取网页: 1、网址 https://travel.qunar.com/ 2、 打开网站,找到要爬取的网页 https://travel.qunar.com/p-cs299979-chongqing 进来之后,找到评论界面,如下所示:在这里我选择驴友点评数据爬取 点击【驴友点评】,进入最终爬取的网址:https://travel.qunar.com/p-cs299
java操作xml之dom4j中的xpath实现用户登陆验证
直接上代码 xml文档:user.xml <?xml version="1.0" encoding="UTF-8"?><db><users username="aaa" password="123" age="25"></users><users username="bbb" password="123" age="25"></users><users username="ccc" pass
爬虫学习--5.xpath数据解析
xpath是XML路径语言,它可以用来确定xml文档中的元素位置,通过元素路径来完成对元素的查找。HTML就是XML的一种实现方式,所以xpath是一种非常强大的定位方式。 基本概念 XPath(XML Path Language)是一种XML的查询语言,他能在XML树状结构中寻找节点。XPath 用于在 XML 文档中通过元素和属性进行导航 xml是一种标记语法的文本格式,xpath可
appium ——Xpath定位元素
1.如果text元素是唯一的,可以通过text定位 //*[@text='text文本属性'] driver.find_element_by_xpath("//*[@text='#买家秀#承包你四季的橱柜!~']").click() 2.如果id唯一,通过ID定位 //*[@resource-id=’id属性’] # 也可以联合@resource-id属性和@text文本属性