本文主要是介绍爬虫学习--5.xpath数据解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
xpath是XML路径语言,它可以用来确定xml文档中的元素位置,通过元素路径来完成对元素的查找。HTML就是XML的一种实现方式,所以xpath是一种非常强大的定位方式。
基本概念
-
XPath(XML Path Language)是一种XML的查询语言,他能在XML树状结构中寻找节点。XPath 用于在 XML 文档中通过元素和属性进行导航
-
xml是一种标记语法的文本格式,xpath可以方便的定位xml中的元素和其中的属性值。lxml是python中的一个第三方模块,它包含了将html文本转成xml对象,和对对象执行xpath的功能
HTML树状结构图
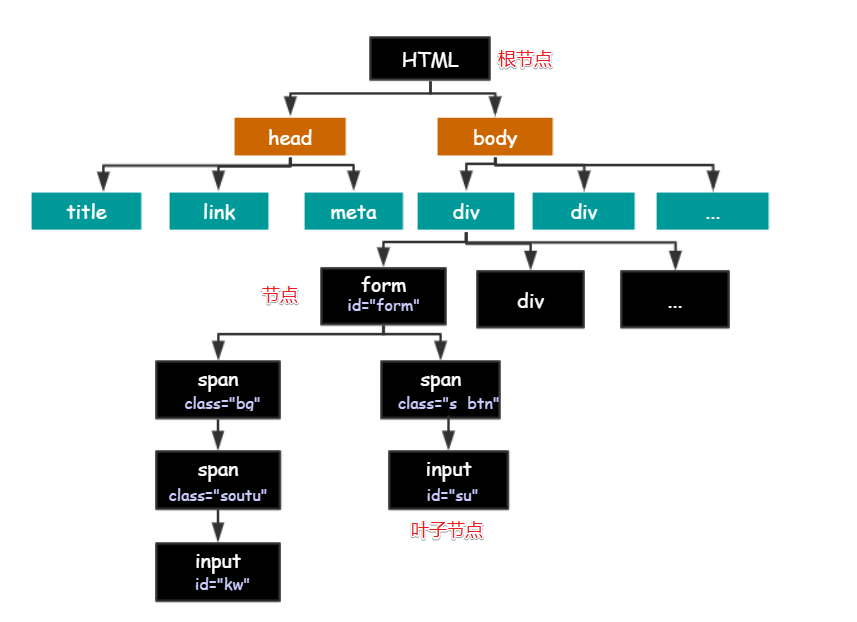
HTML 的结构就是树形结构,HTML 是根节点,所有的其他元素节点都是从根节点发出的。其他的元素都是这棵树上的节点Node,每个节点还可能有属性和文本。而路径就是指某个节点到另一个节点的路线。
节点之间的关系
-
父节点(Parent): HTML 是 body 和 head 节点的父节点;
-
子节点(Child):head 和 body 是 HTML 的子节点;
-
兄弟节点(Sibling):拥有相同的父节点,head 和 body 就是兄弟节点。title 和 div 不是兄弟,因为他们不是同一个父节点。
-
祖先节点(Ancestor):body 是 form 的祖先节点,爷爷辈及以上👴;
-
后代节点(Descendant):form 是 HTML 的后代节点,孙子辈及以下👶。
Xpath中的绝对路径与相对路径
Xpath 中的绝对路径从 HTML 根节点开始算,相对路径从任意节点开始。通过开发者工具,我们可以拷贝到 Xpath 的绝对路径和相对路径代码:
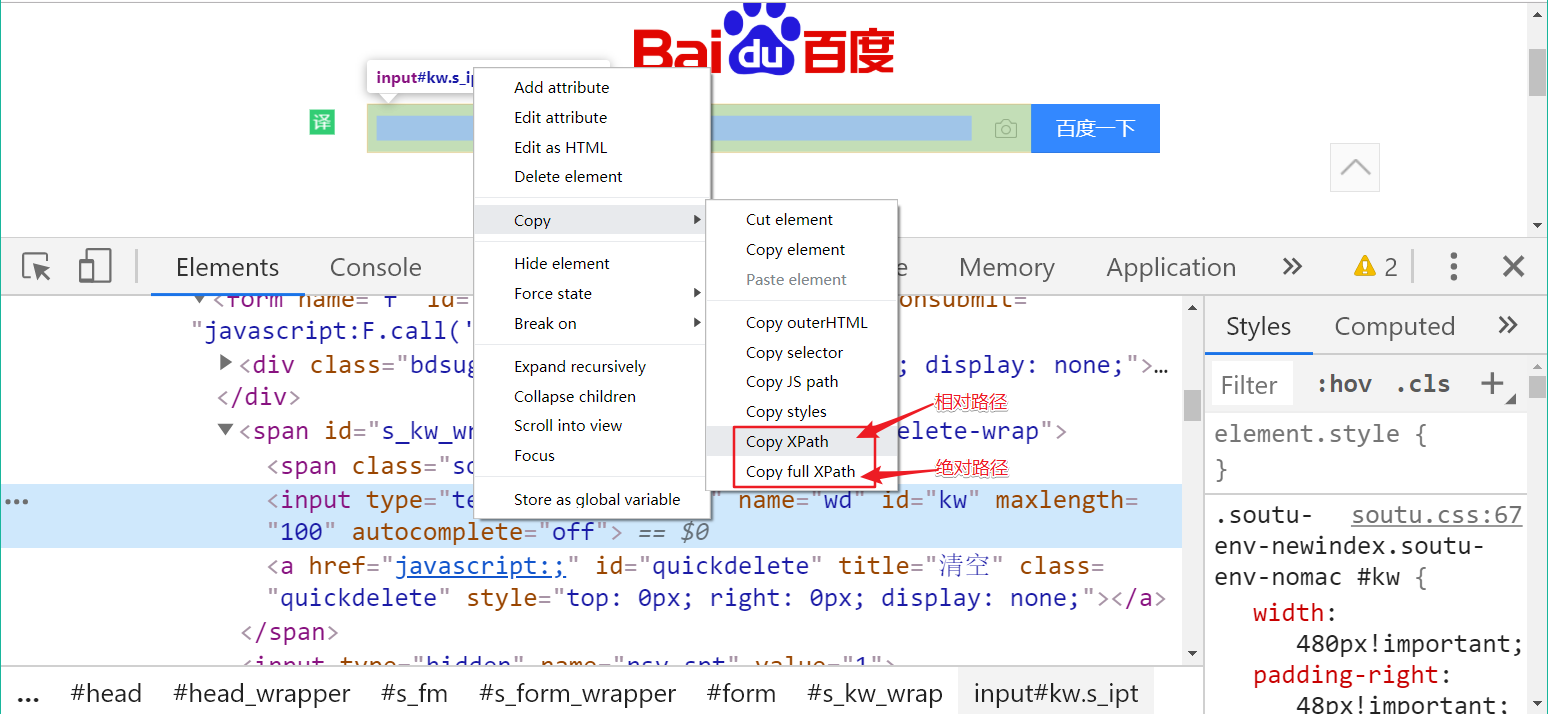
但是由于拷贝出来的代码缺乏灵活性,也不全然准确。大部分情况下,都需要自己定义 Xpath 语句,因此 Xpath 语法还是有必要学习。
绝对路径
Xpath 中最直观的定位策略就是绝对路径。 以百度中的输入框和按钮为例,通过拷贝出来的 full Xpath:
/html/body/div[2]/div/div/div/div/form/span/input
这就是一个绝对路径我们可以看出,绝对路径是从根节点/html开始往下,一层层的表示 出来直到需要的节点为止。这明显不是理智的选项,因此了解以下即可,不用往心里去。
相对路径
除了绝对路径,Xpath 中更常用的方式是相对路径定位方法,以“//”开头。 相对路径可以从任意节点开始,一般我们会选取一个可以唯一定位到的元素开始写,可以 增加查找的准确性。
相对路径定位语法
基本定位语法
| 表达式 | 说明 | 举例 |
|---|---|---|
| / | 从根节点开始选取 | /html/div/span |
| // | 从任意节点开始选取 | //input |
| . | 选取当前节点 | |
| .. | 选取当前节点的父节点 | //input/.. 会选取 input 的父节点 |
| @ | 选取属性或者根据属性选取 | //input[@data] 选取具备 data 属性的 input 元素 //@data 选取所有 data 属性 |
| * | 通配符,表示任意节点或任意属性 |
元素属性定位
属性定位是通过 @ 符号指定需要使用的属性。

层级属性结合定位
遇到某些元素无法精确定位的时候,可以查找其父级及其祖先节点,找到有确定的祖先节点后通过层级依次向下定位。 以下面的结构为例:

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="search" id="form" method="post">
<span class="bg">
<span class="soutu">搜索</span>
</span>
<span class="soutu">
<input type="text" name="key" id="su">
</span>
<div></div>
</form>
</body>
</html>
1、根据层级向下找,从 form 找到绿色的span:
//form[@id="form"]/span/span
2、查找某元素内部的所有元素,选取 form元素内部的所有span:
//form[@id="form"]//span (第二个双斜杠,表示选取内部所有的 span,不管层级关系)
使用谓语定位
谓语是 Xpath 中用于描述元素位置。主要有数字下标、最后一个子元素last()、元素下标函数position()。注意点:Xpath 中的下标从 1 开始。
1、使用下标的方式,从form找到input:
//form[@id="form"]/span[2]/input2、查找最后一个子元素,选取form下的最后一个span:
//form[@id="form"]/span[last()]3、查找倒数第几个子元素,选取 form下的倒数第二个span:
//form[@id="form"]/span[last()-1]4、使用 position() 函数,选取 from 下第二个span:
//form[@id="form"]/span[position()=2]5、使用 position() 函数,选取下标大于 2 的span:
//form[@id="form"]/span[position()>2]
使用逻辑运算符定位
如果元素的某个属性无法精确定位到这个元素,我们还可以用逻辑运算符 and 连接多个属性进行定位,以百度输入框为例。
使用and:
//*[@name='wd' and @class='s_ipt']
查找 name 属性为 wd 并且 class 属性为 s_ipt 的任意元素使用or:
//*[@name='wd' or @class='s_ipt']
查找 name 属性为 wd 或者 class 属性为 s_ipt 的任意元素,取其中之一满足即可。使用|同时查找多个路径,取或:
//form[@id="form"]//span | //form[@id="form"]//input
使用文本定位
我们在爬取网站使用Xpath提取数据的时候,最常使用的就是Xpath的text()方法,该方法可以提取当前元素的信息,但是某些元素下包含很多嵌套元素, 我们想一并的提取出来,这时候就用到了string(.)方法,但是该方法使用的时候跟text()不太一样,下面就举实例来讲解一下具体的区别。
import requests
from lxml import etreeurl = 'https://www.biedoul.com/article/180839'
headers= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}response = requests.get(url,headers=headers)
html = etree.HTML(response.text)
data = html.xpath('//div[@class="cc2"]//text()')
print(data)
data1 = html.xpath('//div[@class="cc2"]')[0].xpath('string(.)')
print(data1)
使用部分匹配函数
| 函数 | 说明 | 举例 |
|---|---|---|
| contains | 选取属性或者文本包含某些字符 | //div[contains(@id, 'data')] 选取 id 属性包含 data 的 div 元素 |
| starts-with | 选取属性或者文本以某些字符开头 | //div[starts-with(@id, 'data')] 选取 id 属性以 data 开头的 div 元素
| | ends-with | 选取属性或者文本以某些字符结尾 | //div[ends-with(@id, 'require')] 选取 id 属性以 require 结尾的 div 元素
|
验证Xpath定位语法
方法一:在开发者工具的 Elements 中按Ctrl + F,在搜索框中输入 Xpath
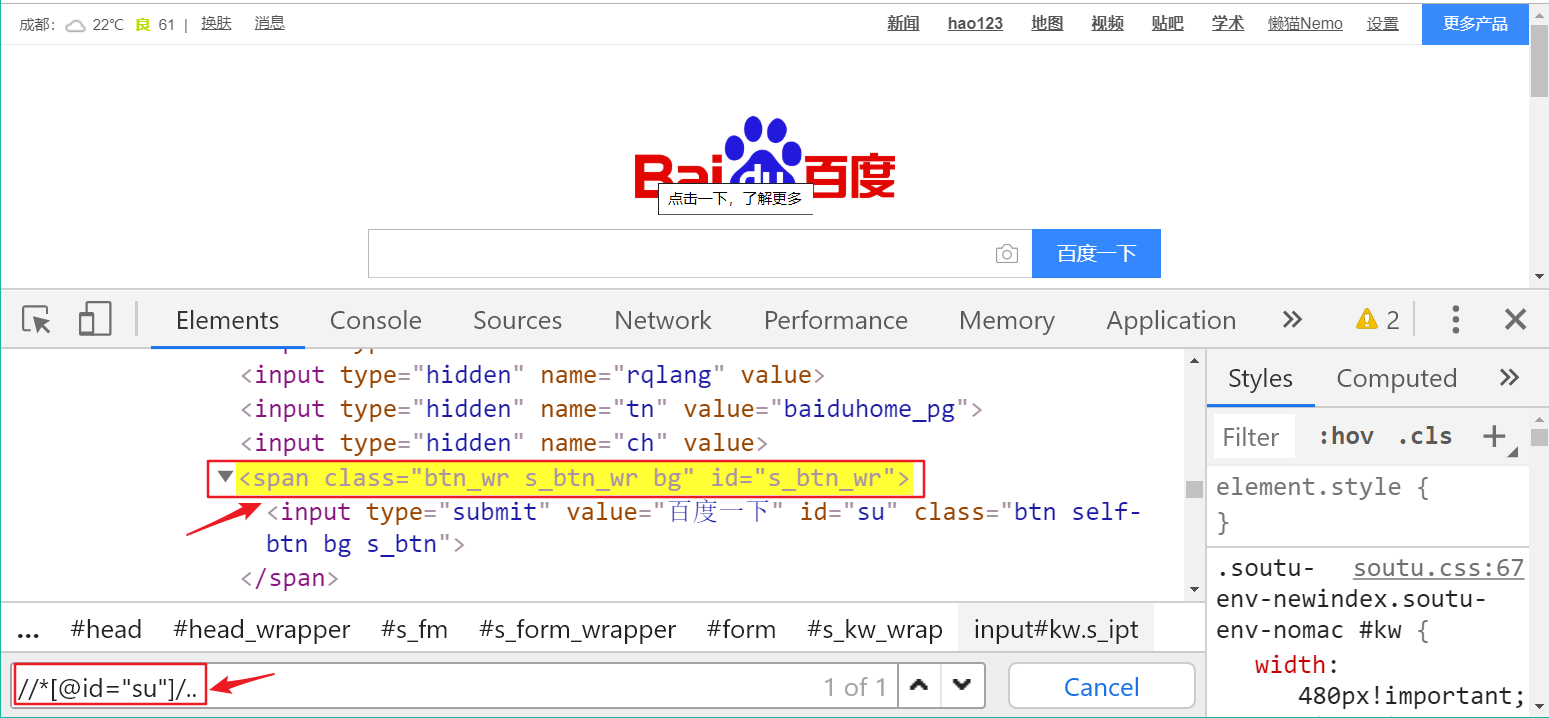
方法二:使用Xpath Helper定位工具验证
不是万能的
1 chrome插件 xpath helper
2 firefox插件 xpath checker
安装流程
1 双击解压包 解压出来的文件夹建议单独放在一个盘符中 最好不要放在桌面
2 打开谷歌浏览器------点击右上角三个点选择更多工具----点击扩展程序
3 打开开发者模式
4 点击加载已解压扩展程序文件 找到你的插件目录将插件加载即可
5 开启插件方式 alt+shift+x (注意你自己的电脑和其他快捷软件的冲突和Fn)
lxml的基本使用
# 导入模块
from lxml import etree
# html源代码
web_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
# 将html转成xml文件
element = etree.HTML(web_data)
# print(element)
# 获取li标签下面的a标签的href
links = element.xpath('//ul/li/a/@href')
print(links)
# 获取li标签下面的a标签的文本数据
result = element.xpath('//ul/li/a/text()')
print(result)
xpath实战
import requests
from lxml import etree
'''
目标:熟悉xpath解析数的方式
需求:爬取电影的名称 评分 引言 详情页的url 翻页爬取1-10页 保存到列表中如何实现?
设计技术与需要的库 requests lxml(etree)实现步骤
1 页面分析(一般讲数据解析模块 都是静态页面)
1.1 通过观察看网页源代码中是否有我们想要的数据 如果有就分析这个url
如果没有再通过ajax寻找接口 通过分析数据在网页源代码中1.2 确定目标url
https://movie.douban.com/top250?start=0&filter= 第一页
通过页面分析发现所有我们想要的数据都在一个div[class="info"]里面具体实现步骤
1 获取整个网页的源码 html
2 将获取的数据源码转成一个element对象(xml)
3 通过element对象实现xpath语法 对数据进行爬取(标题 评分 引言 详情页的url)
4 保存数据 先保存到字典中-->列表中'''
# 定义一个函数用来获取网页源代码
def getsource(pagelink):
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# 获取源码
response = requests.get(pagelink, headers=headers)
response.encoding = 'utf-8'
html = response.text
return html# 定义一个函数用于解析我们的网页源代码并获取我们想要的数据
def geteveryitem(html):
element = etree.HTML(html)
# 拿到[class="info"]的所有div
movieitemlist = element.xpath('//li//div[@class="info"]')
# print(movieitemlist,len(movieitemlist))
# 定义一个列表
itemlist = []
for item in movieitemlist:
# 定义一个字典
itemdict = {}
# 标题
title = item.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')
title = "".join(title).replace("\xa0", "")
# print(title)
# 副标题
othertitle = item.xpath('./div[@class="hd"]/a/span[@class="other"]/text()')[0].replace("\xa0", "")
# print(othertitle)
# 评分
grade = item.xpath('./div[@class="bd"]/div[@class="star"]/span[2]/text()')[0]
# print(grade)
# 详情页的url
link = item.xpath('div[@class="hd"]/a/@href')[0]
# print(link)
# 引言
quote = item.xpath('div[@class="bd"]/p[@class="quote"]/span/text()')
# print(quote)
# list index out of range
# 处理方式1 非空处理
if quote:
quote = quote[0]
else:
quote = ""
# 将数据存放到字典中
itemdict['title'] = ''.join(title + othertitle)
itemdict['grade'] = grade
itemdict['link'] = link
itemdict['quote'] = quote
# print(itemdict)
itemlist.append(itemdict)
# print(itemlist)
return itemlist
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start=0&filter='
html = getsource(url)
itemlist = geteveryitem(html)print(itemlist)
这篇关于爬虫学习--5.xpath数据解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





