算能专题

Banana Pi BPI-SM9 AI 计算模组采用算能科技BM1688芯片方案设计
产品概述 香蕉派 Banana Pi BPI-SM9 16-ENC-A3 深度学习计算模组搭载算能科技高集成度处理器 BM1688,功耗低、算力强、接口丰富、兼容性好。支持INT4/INT8/FP16/BF16/FP32混合精度计算,可支持 16 路高清视频实时分析,灵活应对图像、语音、自然语言等场景,可集成于智算服务器、边缘智算盒、工控机、无人机、AIOT等多种类型产品。 Banana

适配算能BM1684开发板,bmodel推理模型转换
通过mlir转bmodel 一、文件转移 从算能官网technical center (sophgo.com)下载最新的版本,下载下来之后解压出来,再Ubuntu系统中创建一个sophon文件夹存放后续用到的文件,将tpu-mlir_v1.2.8-g32d7b3ec-20230802.tar.gz文件放入Ubuntu系统中的sophon文件夹。 二、配置docker环境 1、docke

【RK3588/算能/Nvidia智能盒子】挑战「无电无网」部署AI算法,守护大亚湾荃美石化码头工地安全
“万顷碧波之上,一座千米钢栈桥如蛟龙出水,向大海蜿蜒。钢栈桥上的项目建设者正在加紧作业,为助推惠州大亚湾加快建设成为世界级绿色石化基地全力奋战。”这是不久前北京日报对大亚湾惠州港荃湾港区荃美石化码头工地的描述。 △ 图片来源于北京日报 荃美石化是世界最大的石油天然气生产商埃克森美孚的全资子公司。据报道,该码头项目将服务于大亚湾石化区油品、化学品等大宗商品和原材料大进大出需求。 作

Nvidia/算能 +FPGA+AI大算力边缘计算盒子:大疆RoboMaster AI挑战赛
NVIDIA Jetson TX2助力机器人战队斩获RoboMaster AI挑战赛冠亚军 一个汇聚数百万机器人专家与研究人员的赛场,一场兼具工程、策略和团队挑战的较量,说的正是近日刚刚在澳大利亚布里斯本ICRA大会上闭幕的大疆RoboMaster AI挑战赛今年的冠军I Hiter以及亚军Critical HIT团队均基于模块化的NVIDIA Jetson TX2超级计算机创建其机器人战队。

Nvidia/算能 +FPGA+AI大算力边缘计算盒子:中国舰船研究院
中国舰船研究院又称中国船舶重工集团公司第七研究院,隶属于中国船舶重工集团公司,是专门从事舰船研究、设计、开发的科学技术研究机构,是中国船舶重工集团公司的军品技术研究中心、科技开发中心;主要从事舰船武器装备发展战略研究、舰船系统顶层技术研究、系统集成及系统工程管理、军民两用技术的开发研究。中国舰船研究院前身为1961年6月成立的国防部第七研究院,先后隶属于国防科委、第六机械工业部、中国人民解放军、中

Nvidia/算能 +FPGA+AI大算力边缘计算盒子:
中国石油大学(华东)是教育部直属全国重点大学,是国家“211工程”重点建设和开展“985工程优势学科创新平台”建设并建有研究生院的高校之一。学校是教育部和五大能源企业集团公司、教育部和山东省人民政府共建的高校,是石油石化高层次人才培养的重要基地,被誉为“石油科技、管理人才的摇篮”,现已成为一所以工为主、石油石化特色鲜明、多学科协调发展的大学。2017年、2022年均进入国家“双一流”建设高校行列。

算能盒子SE5初始配置
算能盒子初始配置 一、卸载qt5.12 sudo dpkg -l | grep qt | grep "5.12.8" | awk '{print $2}' | xargs -I {} sudo dpkg -r --force-all {}sudo dpkg -l | grep qt | grep "5.12.8" | awk '{print $2}' | xargs -I {} sudo d
算能RISC-V通用云开发空间openKylin编译pytorch留档
终于可以体验下risc-v了! 操作系统是openKylin,算能的云空间 尝试编译安装pytorch 首先安装git apt install git 然后下载pytorch和算能cpu的库: git clone https://github.com/sophgo/cpuinfo.git git clone https://github.com/pytorch/pytorch

python+opencv+yolov5+算能 中的一些疑问
Q1:拉流、推流怎么理解 在图像处理中,拉流和推流是与图像获取和传递相关的两个关键概念。 1. 拉流(Pull Streaming): 定义: 拉流是指从数据源主动获取数据的过程。在图像处理领域,这通常指的是从相机、视频文件或网络摄像头等数据源中获取图像数据。 示例: 例如,从一个网络摄像头中获取图像帧,你的图像处理应用程序会通过某种协议(如RTSP、HTTP)主动向摄像头请求
算能SE5-16跑通PP-OCR实例
一、前言 1.1、硬件设备及平台 我使用的虚拟机是Ubuntu20.04 海康摄像头的型号是:MV-CS050-10GMGC 算能平台是: SE5-16 算能的SDK版本是SDK-23.07.01 1.2、相关资料 算能官网:算能 (sophgo.com) 算能教学视频:教学视频 SE5-15手册: SE5-16使用手册 PP-OCR例程:sophon-demo/sampl

TPU编程竞赛系列|第九届 “互联网+”大学生创新创业大赛产业命题赛道,算能6项命题入选!
近日,第九届中国国际“ 互联a网 +” 大学生创新创业大赛产业命题正式公布,算能提交的六 项企业命题成功入选正式赛题。算能六项赛题主要围绕国产 TPU 芯片的边缘计算系统和 RISC-V 架构处理器来设计,且为参赛选手提供了超强算力开发板等硬件资源,欢迎各大 高校学生 们积极报名参与! 赛事介绍 “ 第九届中国国际“ 互联网+” 大学生创新创业大赛” 是由教育部等12 个中央部

基于算能的国产AI边缘计算盒子8核心A53丨17.6Tops算力
边缘计算盒子 8核心A53丨17.6Tops算力 ● 可提供17.6TOPS(INT8)的峰值计算能力、2.2TFLOPS(FP32)的高精度算力,单芯片最高支持32路H.264 & H.265的实时解码能力。 ● 适配Caffe/TensorFlow/MxNet/PyTorch/ ONNX/PaddlePaddle等主流深度学习框架,是行业内少数能同时兼容国内外深度学习框架的边缘计算设
基于算能的国产AI边缘计算盒子8核心A53丨17.6Tops算力
边缘计算盒子 8核心A53丨17.6Tops算力 ● 可提供17.6TOPS(INT8)的峰值计算能力、2.2TFLOPS(FP32)的高精度算力,单芯片最高支持32路H.264 & H.265的实时解码能力。 ● 适配Caffe/TensorFlow/MxNet/PyTorch/ ONNX/PaddlePaddle等主流深度学习框架,是行业内少数能同时兼容国内外深度学习框架的边缘计算设

基于算能的国产AI边缘计算盒子,8核心A53丨10.6Tops算力
边缘计算盒子 8核心A53丨10.6Tops算力 ● 算力高达10.6TOPS,单芯片最高支持8路H.264 & H.265的实时解码能力。 ● 可扩展4G/5G/WIFI无线网络方式,为边缘化业务部署提供便利。 ● 支持RS232/RS485/USB2.0/USB3.0/HDMI OUT/双千兆以太网等。 ● 低功耗设计,结合外壳散热。 ● 支持-20℃~+60℃宽温工作环境。

基于算能的国产AI边缘计算盒子,内置强悍TPU | 32TOPS INT8算力
边缘计算盒子 内置强悍TPU | 32TOPS INT8算力 ● 支持浮点运算的TPU平台盒子,支持32TOPS@INT8,16TFLOPS@FP16,2TFLOPS@FP32高算力 ● 单芯片最高支持32路H.264 & H.265的实时解码能力 ● 支持国产算法框架Paddle飞桨,适配Caffe/TensorFlow/MxNet/PyTorch/ONNX等主流深度学习框架 ● 支持
基于算能的国产AI边缘计算盒子8核心A53丨17.6Tops算力
边缘计算盒子 8核心A53丨17.6Tops算力 ● 可提供17.6TOPS(INT8)的峰值计算能力、2.2TFLOPS(FP32)的高精度算力,单芯片最高支持32路H.264 & H.265的实时解码能力。 ● 适配Caffe/TensorFlow/MxNet/PyTorch/ ONNX/PaddlePaddle等主流深度学习框架,是行业内少数能同时兼容国内外深度学习框架的边缘计算设

极智芯 | 解读国产AI算力算能产品矩阵
欢迎关注我的公众号 [极智视界],获取我的更多经验分享 大家好,我是极智视界,本文分享一下 解读国产AI算力 华为昇腾产品矩阵。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 算能属于自研 TPU 阵营,算能,有时候又叫比特大陆,有时候又叫算丰,我没有研究过他们公司的具体发展情况,所以关于称呼

CCF BDCI|算能赛题决赛选手说明论文-05
基于TPU平台实现人群密度估计 队伍:SO-FAST 宋礼 算法工程师 京东科技 中国-北京 song200626@163.com柯嵩宇计算机科学与技术专业 博士 上海交通大学 中国-上海 songyuke@sjtu.edu.cn包锴楠计算机科学与技术 硕士 西南交通大学 中国-成都 baokainan123@gmail.com 团队简介 SO-FAST的团队
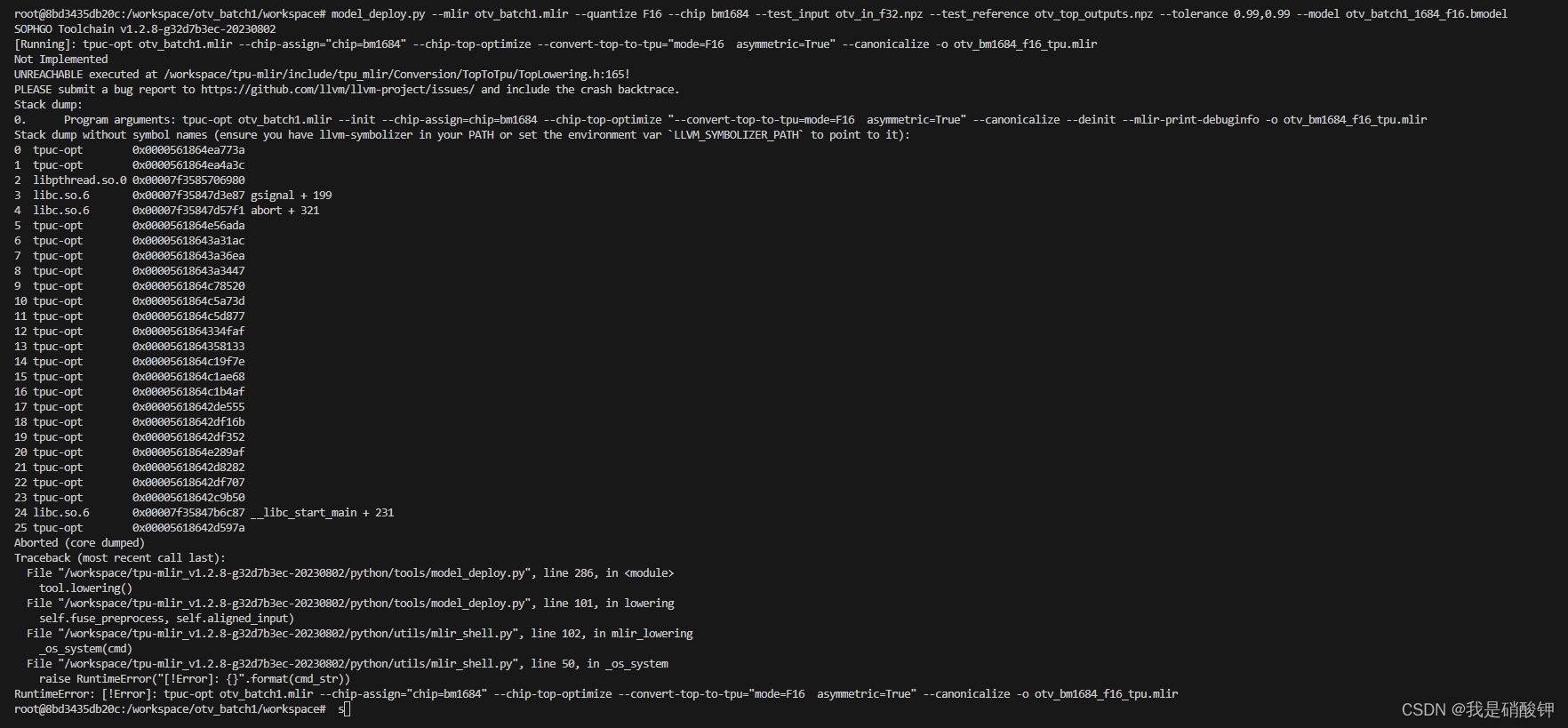
【算能】模型转换过程报错
报错信息: RuntimeError: [!Error]: tpuc-opt otv_batch1.mlir --chip-assign="chip=bm1684" --chip-top-optimize --convert-top-to-tpu="mode=F16 asymmetric=True" --canonicalize -o otv_bm1684_f16_tpu.mlir 报

【算能】在Docker中调用PCIe卡
开发需求,需要在centos下开发对应的内容 首先拉取docker 镜像 docker pull centos:centos7 然后在空白的centos容器下使用PCIe卡,这个部分特别提醒,需要挂载/dev的这个目录,才能读到内容,故而创建docker的命令 docker run --restart always --privileged -v /dev:/dev -td -v

英码边缘计算盒子IVP03X——32T超强算力,搭载BM1684X算能TPU处理器
产品8大优势: 高效节能:相较异构产品,IVP03X数据调配效率更高,资源利用率更高,平均功耗更低;升级换代:相较算能BM1684平台,IVP03X算力、编码,模型转换性能均翻倍提升,且不用改底板,仅需替换核心模组即可快速、低成本实现平台升级;全国产化:适配国产化麒麟系统; 散热性能:被动散热设计,0噪音,运行更稳定可靠;接口连接:采用凤凰端子接口,适配性更强;开发环境:相比同行提供的深度学习开