第十六章专题

第十六章_动态注册和Servlet容器初始化
16.1、动态注册 为了使动态注册成为可能,ServletContext接口中还添加了以下方法,用来动态地创建Web对象: <T extends Filter>createFilter(java.lang.Class<T> clazz) <T extends java.util.EventListener> createListener(java.lang.Class<T> clazz)
第十六章 非阻塞I/O
第十六章、非阻塞式I/O 什么是阻塞socket和非阻塞socket?两者的具体区别是什么? 读操作 对于阻塞的socket,当socket的接收缓冲区中没有数据时,read调用会一直阻塞住,直到有数据到来才返回。当socket缓冲区中的数据量小于期望读取的数据量时,返回实际读取的字节数。当sockt的接收缓冲区中的数据大于期望读取的字节数时,读取期望读取的

第十六章(二) 套接字初识
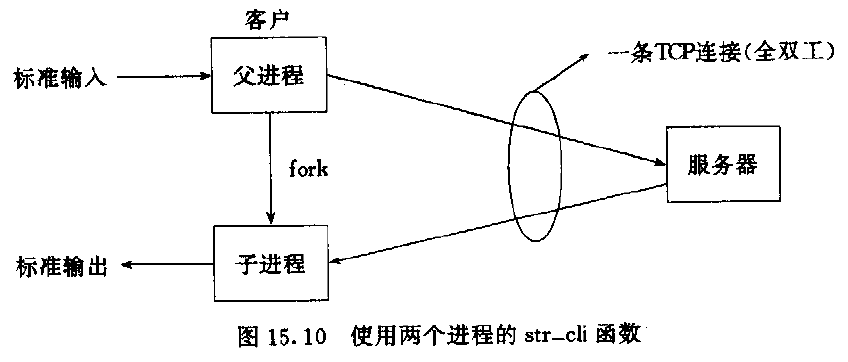
数据传输: 尽管可以通过 read 和 write 交换数据,但这就是这两个函数所能作的一切。但是如果想要指定选项,从多个客户端接收数据包,或者发送带外数据,就需要使用6个为数据传递而设计的套接字函数。 三个传送数据的套接字函数: <span style="color:#000000;">ssize_t send(int sockfd, void *buf, size_t n

第十六章(一) 套接字初识
地址格式 一个地址标识一个特定通信域的套接字端点,地址格式与这个特定的通信域相关。为使不同的格式地址能够传入到套接字函数,地址会被强制转化成一个通用的地址结构: struct sockaddr{sa_family_t sa_family; //address familychar sa_data[]; //variable-length address...};
2024.06.20【读书笔记】丨生物信息学与功能基因组学(第十六章 真核生物基因组 第三部分)【AI测试版】
了解到您的需求,现在我将为您撰写关于《生物信息学与功能基因组学》的第三部分读书笔记。 《生物信息学与功能基因组学》第十六章读书笔记(第三部分) 正文(续) 真核基因组的重复性DNA序列 真核基因组中的重复性DNA序列是其结构的重要组成部分。这些序列可以根据重复单元的大小和分布模式被分类为卫星DNA、微卫星DNA和矿物DNA等。它们在染色体的结构稳定性、基因表达调控以及物种进化中扮演着重要角
AWS无服务器 应用程序开发—第十六章 CI/CD CodeBuild
在 AWS CodeBuild 中进行单元测试需要配置构建规范文件 (buildspec.yml),该文件定义了 CodeBuild 在构建过程中需要执行的步骤。以下是如何使用 CodeBuild 进行单元测试的具体步骤: 准备项目结构 首先,确保你的项目具有适当的目录结构和测试文件。以下是一个示例项目结构: my-lambda-project/│├── lambda_function.

算法导论实战(三)(算法导论习题第十六章)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀算法启示录 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 前言 算法导论的知识点学习将持续性更新在算法启示录_十二月的猫的博客-CSDN博客,欢迎大家订阅呀(反正是免费的哦~~) 实战篇也将在专栏上持续更新,主要目的是强化对理论的学习(题目来源:山东大学孔凡玉老师推荐)

第十六章 创建Web客户端 - 修改生成的客户端类
文章目录 第十六章 创建Web客户端 - 修改生成的客户端类修改生成的客户端类调整生成的类以处理极长的字符串 第十六章 创建Web客户端 - 修改生成的客户端类 修改生成的客户端类 生成 Web 客户端类后,通常不需要编辑该类。相反,可以编写代码来创建 Web 客户端的实例并提供客户端错误处理。本节记录了修改生成的客户端类时的值得注意的例外情况。 注意:不要创建生成的 We

【UnityShader入门精要学习笔记】第十六章 Unity中的渲染优化技术 (上)
本系列为作者学习UnityShader入门精要而作的笔记,内容将包括: 书本中句子照抄 + 个人批注项目源码一堆新手会犯的错误潜在的太监断更,有始无终 我的GitHub仓库 总之适用于同样开始学习Shader的同学们进行有取舍的参考。 文章目录 移动平台上的优化影响性能的因素渲染统计窗口性能分析器帧调试器减少DrawCall的数量关于渲染相关数据结构的说明批处理动态批处理 静态
【信息系统项目管理师】复习~第十六章
16.采购管理 协议:可以很简单,如以特定人工单价购买所需的工时,也可以很复杂,如多年的国际施工合同。因应用领域不同,协议可以是合同、服务水平协议(SLA)、谅解备忘录、协议备忘录(MOA)或订购单。项目采购管理的发展趋势和新兴实践: ①工具的改进。②更先进的风险管理。③变化中的合同签署实践。④物流和供应链管理。⑤技术和干系人关系。⑥试用采购。 3. 项目采购管理三大过程: 4.裁剪考虑的
《21天学通C++》(第十六章)STL string类
为什么需要string类? 1.减少在创建和操作字符串方面的操作 2.在内部管理内存分配细节,提高程序稳定性 3.提供复制构造函数和赋值运算符 4.提供截短、查找、删除、比较等函数 1.实例化STL string #include <iostream>int main() {std::string strString;strString="hello STL";//动态分配std::co

React 第十六章 Ref转发
在 React 中,ref 是用来获取组件或者 DOM 元素的引用的一种机制。通过 ref ,你可以在函数组件中直接访问子组件的实例或者访问 DOM 元素。 然而,在某些情况下,你可能需要将 ref 传递给组件中的子组件,或者将 ref 传递到具有特定方法的 DOM 元素上。这就是 React ref 转发的作用。 React ref 转发允许某个组件接收一个 ref,并将其转发给其子组件中指
Linux 第十六章
🐶博主主页:@ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C++,linux 🔥座右铭:“不要等到什么都没有了,才下定决心去做” 🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 目录 环境变量 环境变量:PATH 查看环境变量PATH 将自己程序加入PATH 删除PATH里的路径
《C++Primer》第十六章 模板与泛型编程
第十六章 模板与泛型编程 定义模板 1. 函数模板 模板定义以关键字template关键字开始,后面跟着一个模板参数列表(不能为空): template <typename T>int compare(const T &v1, const T &v2){if (v1 < v2) return -1;if (v2 < v1) return 1;return 0;} 类型参数可以用来指定返回类

机器学习理论 | 周志华西瓜书 第十六章:强化学习
第十六章 强化学习 此系列文章旨在提炼周志华《机器学习》的核心要点,不断完善中… 16.1 任务与奖赏 通常使用马尔可夫决策过程(MDP)描述目的:找到能长期积累奖赏最大化策略长期奖赏方式 T步积累奖赏: E [ 1 T ∑ t = 1 T r t ] \mathbb{E}[\frac 1 T\sum_{t=1}^Tr_t] E[T1∑t=1Trt] γ折扣积累奖赏: E [ ∑
游戏感:虚拟感觉的游戏设计师指南——第十六章 Raptor Safari
这是一本游戏设计方面的好书 转自天:天之虹的博客:http://blog.sina.com.cn/jackiechueng 感谢天之虹的无私奉献 Word版可到本人的资源中下载 第十六章 Raptor Safari 玩家在玩赛车游戏时都有着头脑发热般的疯狂,这种疯狂程度是在其他类型的游戏中很难找到的。这或许也是很正常的。人们都爱车,喜欢一直开着车,在某些情况下对它还挺盲目崇拜的。

Scala第十六章节(泛型方法, 类, 特质的用法、泛型上下界、协变, 逆变, 非变的用法以及Scala列表去重排序案例)
Scala第十六章节 章节目标 掌握泛型方法, 类, 特质的用法了解泛型上下界相关内容了解协变, 逆变, 非变的用法掌握列表去重排序案例 1. 泛型 泛型的意思是泛指某种具体的数据类型, 在Scala中, 泛型用[数据类型]表示. 在实际开发中, 泛型一般是结合数组或者集合来使用的, 除此之外, 泛型的常见用法还有以下三种: 泛型方法泛型类泛型特质 1.1 泛型方法 泛型方法指的
C++ primer 第十六章
模板是C++中泛型编程的基础,一个模板就是一个创建类或函数的蓝图。 1.定义模板 模板适用于唯一的差异是参数的类型,函数体完全一致的情况。 1.1、函数模板 我们可以定义一个通用的函数模板用来生成针对特定类型的函数版本。 模板定义以关键字template开始,后跟模板参数列表。 template<typename T> int compare(const T& v1, const T&
数学分析教程 第十六章学习感受
这一章专门讲反常积分。主要分为两大类:无穷积分与瑕积分。 无穷积分的理论与级数是平行的,柯西收敛原理,比较判别法,dirichlet判别法和abel判别法,甚至连abel求和公式都有对应的第二积分平均值定理。 瑕积分的判别可以通过变量代换变为一个无穷积分,也有等价的比较判别法。这里还提了beta函数和gamma函数,算是为了给含参变量的积分打一点基础吧。这里还提了一下柯西主值。 本章还
疯狂JAVA讲义---第十六章:多线程(下)
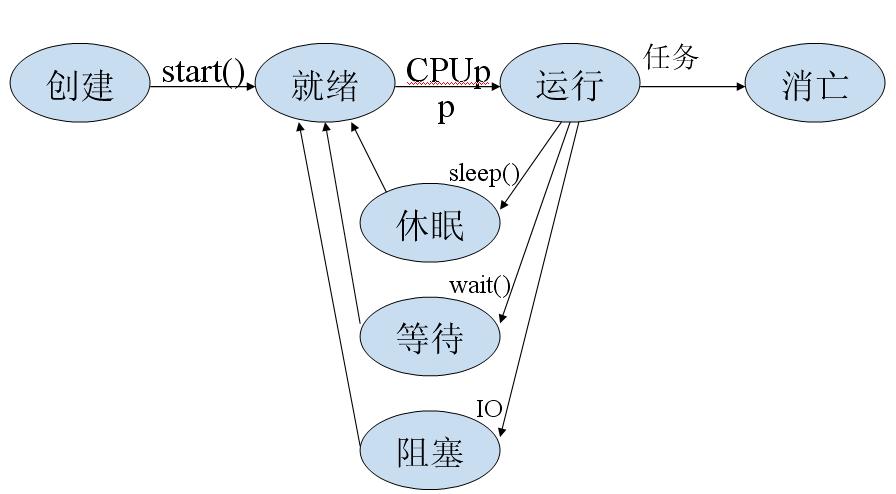
看过我昨天的博客,大家肯定对多线程有所了解,今天要讲多线程中比较高层次的东西。首先讲下JDK1.5新出来的线程同步机制---同步锁(Lock),其实和synhronized方法用法差不多,只是更灵活。同步锁有多种,其中一般为了线程安全都用ReentrantLock(可重入锁),eg public class Account{//定义锁对象private final ReentrantLoc
疯狂JAVA讲义---第十六章:多线程(上)
并发现象在现实生活中大量存在,人体(消化、运动),计算机(同时运行多种程序)。多线程—在一个程序中实现并发编程语言一般提供了串行程序设计的方法计算机的并发能力由操作系统提供,Java在语言级提供多线程并发的概念。 线程是比进程单位更小的执行单位,在形式上同进程十分相似——都是用一个顺序执行的语句序列来完成特定的功能。线程没有入口,也没有出口,因此其自身不能自动运行,而必须栖身于某一进程之中,由进
现实迷途 第十六章 有点无聊
第十六章 有点无聊 注:原创作品,请尊重原作者,未经同意,请勿转载,否则追究责任。 闲了下来后,江北每天一个人坐在办公室里无聊地打发时间,一时之间有点找不到方向的感觉。 虽然江北知道那笔尾款能拿到的希望不大,但毕竟是四万块钱,不是小数目,所以江北还是不放弃,不时跑到潘松单位去向潘松探听一下情况。 江北去多了,潘松也有点烦了,但又碍于同乡的情面,不好发作,于是有一次他主动把江北约了出来,请江

c++ primer plus 笔记 第十六章 string类和标准模板库
string类 string自动调整大小的功能: string字符串是怎么占用内存空间的? 前景: 如果只给string字符串分配string字符串大小的空间,当一个string字符串附加到另一个string字符串上,这个string字符串是以占用相邻内存的方式进行扩容的,相邻的内存不够存放这个附加的字符串的时候,就需要将拼接起来的这两个string字符串迁移
第十六章 构建和配置 Nginx 以与 Web 网关配合使用 (Windows) - 将 NSD 与 Nginx 结合使用
文章目录 第十六章 构建和配置 Nginx 以与 Web 网关配合使用 (Windows) - 将 NSD 与 Nginx 结合使用将 `NSD` 与 `Nginx` 结合使用`CSPNSD_pass hostname:portNum`;`CSP on; and CSP off`;`CSPFileTypes filetype1[ filetype2...];``CSPNSD_response
C++从入门到精通 第十六章(STL常用算法)
写在前面: 本系列专栏主要介绍C++的相关知识,思路以下面的参考链接教程为主,大部分笔记也出自该教程,笔者的原创部分主要在示例代码的注释部分。除了参考下面的链接教程以外,笔者还参考了其它的一些C++教材(比如计算机二级教材和C语言教材),笔者认为重要的部分大多都会用粗体标注(未被标注出的部分可能全是重点,可根据相关部分的示例代码量和注释量判断,或者根据实际经验判断)。如有错漏欢迎指出。 参考
Docker 第十六章 : Docker 三剑客之 Compose(二)
第十六章 : Docker 三剑客之 Compose(二) 本章知识点: Docker Compose YAML模板文件包含哪些顶层元素与用法、docker-compose常用命令22个。 Linux 内核:3.10.0-1062.el7.x86_64 Docker version 25.0.0 注意:docker-compose = docker compose Docker