概率模型专题

(感知机-Perceptron)—有监督学习方法、非概率模型、判别模型、线性模型、参数化模型、批量学习、核方法
定义 假设输入空间(特征空间)是 χ \chi χ ⊆ R n \subseteq R^n ⊆Rn,输出空间是y = { + 1 , − 1 } =\{+1,-1 \} ={+1,−1} 。输入 x ∈ χ x \in \chi x∈χ表示实例的特征向量,对应于输入空间(特征空间)的点;输出 y ∈ y \in y∈y表示实例的类别。由输入空间到输出空间的如下函数: f ( x ) = s

去噪扩散概率模型在现代技术中的应用:图像生成、音频处理到药物发现
去噪扩散概率模型(DDPMs)是一种先进的生成模型,它通过模拟数据的噪声化和去噪过程,展现出多方面的优势。DDPMs能够生成高质量的数据样本,这在图像合成、音频生成等领域尤为重要。它们在数据去噪方面表现出色,能够有效地从噪声数据中恢复出原始信号,这对于信号处理和数据分析尤其有用。DDPMs通过数据增强,可以提高机器学习模型的泛化能力,减少过拟合。在异常检测方面,DDPMs能够识别数据中的异常值,有
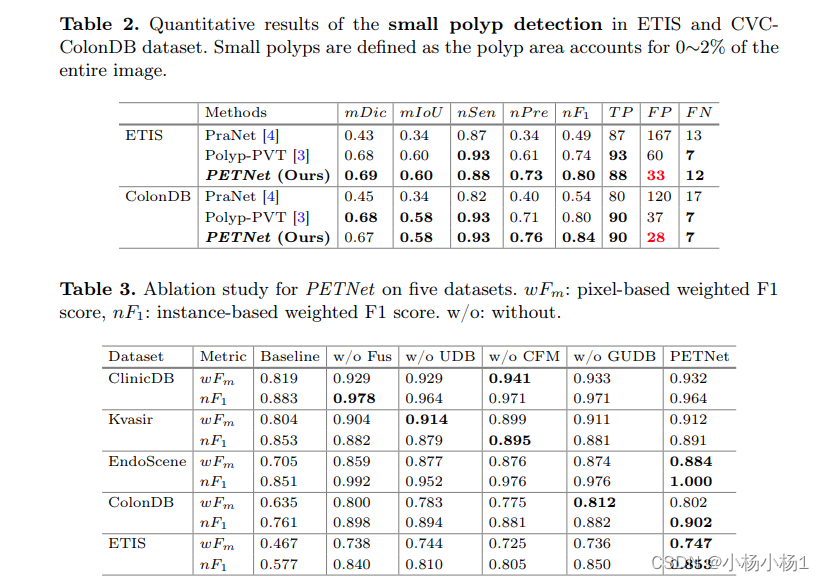
集成Vision Transformer 的概率模型改进了复杂的息肉分割
文章目录 标题摘要方法实验结果 标题 摘要 结直肠息肉在结肠镜检查中被发现,与结直肠癌密切相关,因此息肉分割是诊断和治疗计划的重要临床决策工具。然而,准确的息肉分割仍然是一个具有挑战性的任务,尤其是在涉及微小息肉和其他肠道物质导致高假阳性率的情况下。以往基于监督二值掩码的息肉分割网络可能缺乏对息肉的全局语义感知,导致在复杂场景中对息肉的捕捉和区分能力不足。 本文提出了一种新
从概率模型到逻辑分类
数组的基本使用一、数组的定义 概念: 数组就是存储数据长度固定的容器,保证多个数据的数据类型要一致。 格式一:数组存储的数据类型[] 数组名字; 举例:int[] arr; 格式二:数组存储的数据类型 数组名字[]; 举例:int arr[];二、数组动态初始化 格式:数组存储的数据类型[]
【机器学习】概率模型在机器学习中的应用:以朴素贝叶斯分类去为例
概率模型在机器学习中的应用:以朴素贝叶斯分类器为例 一、概率模型的基本原理二、朴素贝叶斯分类器的原理与实现三、朴素贝叶斯分类器的应用与挑战四、结论与展望 在大数据与人工智能时代,概率模型在各个领域发挥着至关重要的作用。概率模型以概率论和统计学为基础,通过数学模型描述随机现象或事件的分布、发生概率以及它们之间的概率关系,为复杂世界的分析与预测提供了有力的工具。尤其在机器学习

第3章-从线性概率模型到广义线性模型(2)
简介 回顾上节文章中提到的logistic和probit模型: 我们假定了潜变量模型 y*=xβ+u (y=1,when y*>0; y=0,when y*<=0) 中的残差变量服从对应的是logistic分布或正态分布,并且我们假定 P ( y = 1 ∣ x ) = G ( β 0 + β 1 x 1 + β 2 x 2 + … + β n x n ) = G ( β 0 + x β )
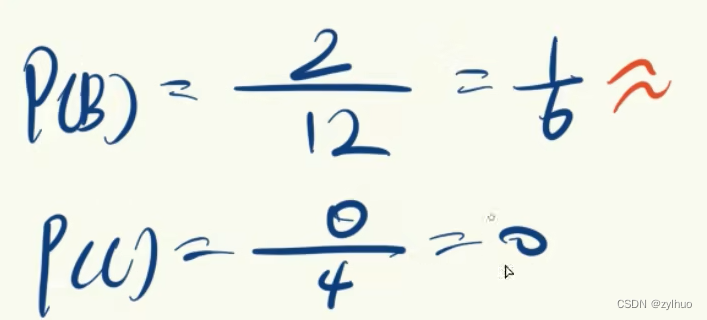
AI-数学-高中-34概率-古典概率模型
原作者视频:【概率】【一数辞典】3古典概型_哔哩哔哩_bilibili 等可能性:每个样本点出现的可能性是相同的。 随机事件A的发生=事件A的样本点数k / 样板空间总样本点数n。 示例1: 示例2:

【扩散模型】2、DDPM | 去噪扩散概率模型开山之作
文章目录 数学基础知识一、背景二、DDPM 主要过程2.1 前向扩散过程2.2 逆向去噪过程2.3 训练和推理 论文:Denoising Diffusion Probabilistic Models 代码:https://github.com/hojonathanho/diffusion stable diffusion 代码实现:https://github.com/C

机器学习:李宏毅:概率分布生成概率模型
1.概率分布 由于前面学习的是回归,因此我们通过回归的方法来查看概率分布 分类是class 1 的时候结果是1 分类为class 2的时候结果是-1; 测试时,如果结果接近1的是class1 ,如果结果接近-1的是class2。 但是呢,这只是看起来很美丽,但是如果当结果远远大于1的时候,他的分类应该是class1还是class2呢? 我们为了降低整体误差,需要调整已经找到的分类函数,这样会导
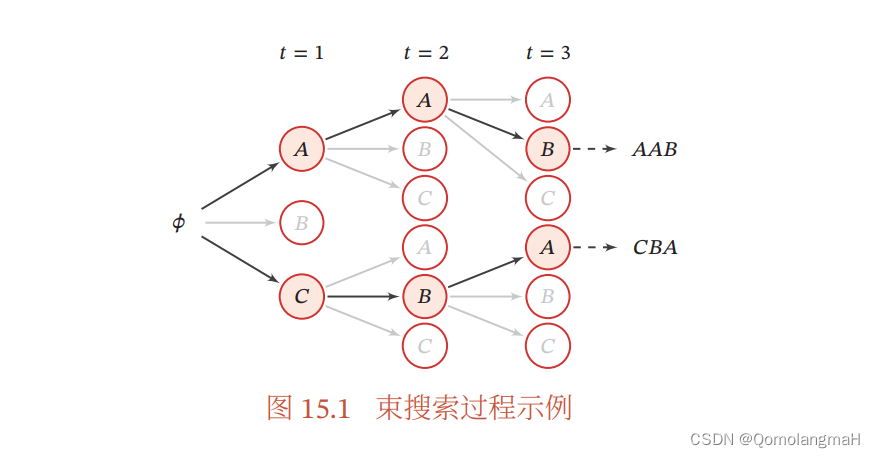
序列生成模型(一):序列概率模型
文章目录 前言1. 序列数据2. 序列数据的潜在规律3. 序列概率模型的两个基本问题 一、序列概率模型1. 理论基础序列的概率分解自回归生成模型 2. 序列生成 前言 深度学习在处理序列数据方面取得了巨大的成功,尤其是在自然语言处理领域。序列数据可以是文本、声音、视频、DNA序列等,在深度学习中,我们可以将它们看作是符合一定规则的序列。 1. 序列数据 序列数

如何理解概率模型和非概率模型
之前一直很纠结什么是概率模型,什么是非概率模型,最近终于理解了,分享给大家 通过举一个小例子,比如我们现在有一个分类任务,通过重量、体积、甜度、颜色将西瓜分为好、中、差三类。 对于概率模型来说: 通过给定的特征X=(x1重量=a,x2体积=b,x3甜度=c,x4颜色=d),计算出该西瓜属于每一类的概率P。即: P(好瓜 | X) P(中瓜 | X) P(差瓜 | X) 将最大概率的类别赋给该西
deepar,传统概率模型如何和深度学习结合的?
由于是在不会打公式,所以只能白话说下自己的认识. 深度学习和统计领域一些知识的结合,比如条件随机场crf,再比如这个deepar,都是在损失函数上做文章. deepar预测的不是数据本身,而是数据分布的参数.比如模型预测出价格时间序列的均值和方差,假设分布是正态分布,那么损失函数怎么构造了? deepar预测的不是一个时间点,比如预测7天,那么每天都会预测出一个均值和方差, 这一共就是7组模型参
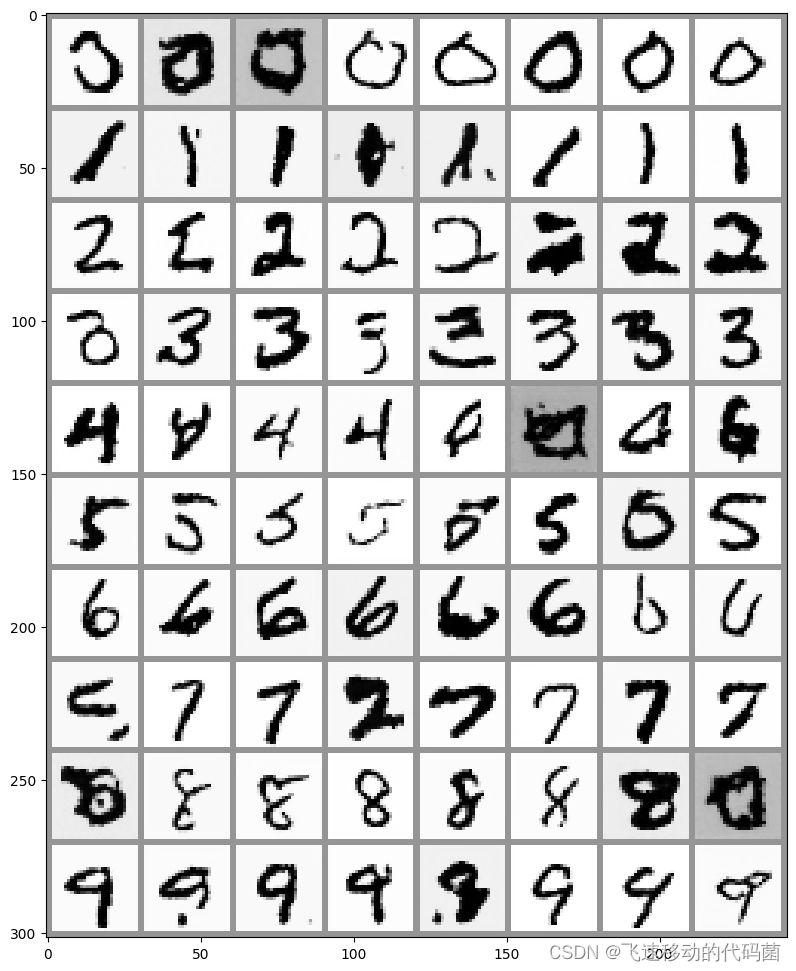
【扩散模型】本质是数学概率模型
课程地址:https://github.com/huggingface/diffusion-models-class/blob/main/unit2/ 今天跟随DataWhale的直播课程,进一步认识到模型的本质都是概率模型。扩散模型中通过在 UNet 下采样增加噪声,训练拟合噪声,在推理时从tn逐步预测t0的图像。 ControlNet 和 CLIP 等本质是在操控 UNet 的部分,同时

浅谈机器学习中的概率模型
浅谈机器学习中的概率模型 其实,当牵扯到概率的时候,一切问题都会变的及其复杂,比如我们监督学习任务中,对于一个分类任务,我们经常是在解决这样一个问题,比如对于一个n维的样本 X = [ x 1 , x 2 , . . . . . x n ] X=[x_1,x_2,.....x_n] X=[x1,x2,.....xn],我们想知道它的类别,这个时候我们可以采用概率模型,比如贝叶斯模型,但是,