方根专题

【办公软件】Excel如何开n次方根
在文章:【分立元件】电阻的基础知识中我们学习电阻值、电阻值容差标注相关标准。知道了标准将电阻值标准数列化。因此电阻值并非1Ω、2Ω、3Ω那样的整数,而是2.2Ω、4.7Ω那样的小数。 这是因为电阻值以标准数(E系列)为准。系列的“E”是Exponent(指数)的E,后面的数字,譬如24是分割数。即E24是从1到10用等比级数(10的24次方根)分割。
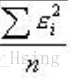
方差、标准差、均方误差和均方根误差
最近在整机器学习的内容,这个概念稍微有点乱,百度一下,里清楚了,做个记录: 一、白话描述 1、方差的二次开方等于标准差 2、均方误差的二次开方等于均方根误差。 3、方差是每个样本减去总样本的平均值去计算的,而均方误差是每个样本减去该样本的真实值来计算的 所以,方差、标准差是数学上的概念,而均方误差是在机器学习中用的比较多的概念,计算loss的时候会用,实际上原理是类似的,但是具体计算上稍

残差平方和(RSS)、均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)
残差平方和(RSS) 等同于SSE(误差项平方和) 实际值与预测值之间差的平方之和。 MSE: Mean Squared Error 均方误差是RSS的期望值(或均值); MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。 RMSE 均方根误差:均方根误差是均方误差的算术平方根 MAE :Mean Absolute Error 平均绝对误差是绝对
Llama改进之——均方根层归一化RMSNorm
引言 在学习完GPT2之后,从本文开始进入Llama模型系列。 本文介绍Llama模型的改进之RMSNorm(均方根层归一化)。它是由Root Mean Square Layer Normalization论文提出来的,可以参阅其论文笔记1。 LayerNorm 层归一化(LayerNorm)对Transformer等模型来说非常重要,它可以帮助稳定训练并提升模型收敛性。LayerNorm
【机器学习300问】43、回归模型预测效果明明很好,为什么均方根误差很大?
一、案例描述 假设我们正在构建一个房地产价格预测模型,目标是预测某个城市各类住宅的售价。模型基于大量房屋的各种特征(如面积、地段、房龄、楼层等)进行训练。 回归模型在大部分情况下对于住宅价格预测非常精准,用户反馈也非常好,模型的实际预测能力在业界得到了认可。但RMSE指标却依旧很高这是为什么? 二、原因分析 均方根误差(Root Mean
【No.13】蓝桥杯二分查找|整数二分|实数二分|跳石头|M次方根|分巧克力(C++)
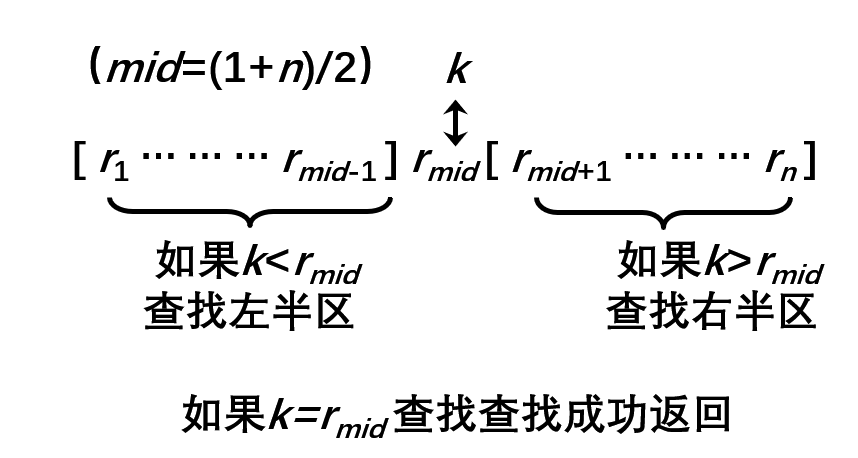
二分查找算法 知识点 二分查找原理讲解在单调递增序列 a 中查找 x 或 x 的后继在单调递增序列 a 中查找 x 或 x 的前驱 二分查找算法讲解 枚举查找即顺序查找, 实现原理是逐个比较数组 a[0:n-1] 中的元素,直到找到元素 x 或搜索整个数组后确定 x 不在其中。最坏情况下需要比较 N 次,时间复杂度是 O(n),属于线性阶算法。 而二分查找是一种折半查找方法。 该方法将 N
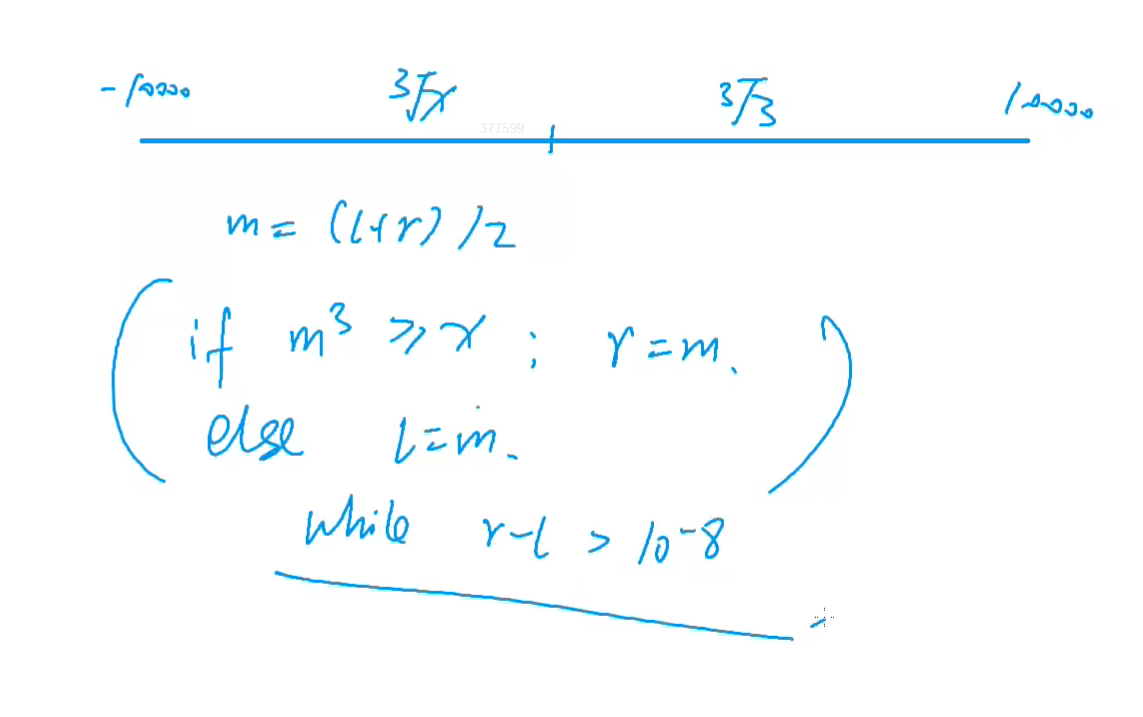
C++ 浮点数二分 数的三次方根
给定一个浮点数 n ,求它的三次方根。 输入格式 共一行,包含一个浮点数 n 。 输出格式 共一行,包含一个浮点数,表示问题的解。 注意,结果保留 6 位小数。 数据范围 −10000≤n≤10000 输入样例: 1000.00 输出样例: 10.000000 #include <iostream>using namespace std;double n;int main (){sc
深度学习记录--RMSprop均方根
RMSprop(root mean square prop) 减缓纵轴方向学习速度,加快横轴方向学习速度,从而加速梯度下降 方法: 原理: 不妨以b为纵轴,w为横轴(横纵轴可能会不同,因为是多维量) 为了让w梯度下降更快,则要使S_dw尽量小,即w每次减去一个大数字,所以w梯度下降更快 为了让b梯度下降更慢,则要使S_db尽量大,即b每次减去一个小数字,所以b梯

nb -- 法国男子77.99秒心算出200位数13次方根
// from http://bbs.chinaunix.net/viewthread.php?tid=970166&extra=page%3D1 http://www.sina.com.cn 2007年08月01日 07:16 新闻晨报 作者:兰西 现年26岁的法国男子亚历克西斯·勒迈尔曾在9分钟内心算出了一个200位数的13次方根。上个礼拜,亚历克西斯在英国牛津科学
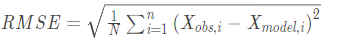
如何计算置信区间,RMSE均方根误差/标准误差:误差平方和的平均数开方
如何通过部分样本来计算总体的一个置信区间呢?主要有下面几个步骤: step1:首先明确要求解的问题。就是你要预估什么?不管是全校学生身高还是学生成绩。 step2:求抽样样本的平均值与标准误差(standard error,RMSE,均方根误差)。注意标准误差与标准差(standard deviation)不一样(标准差反映了整个样本对样本平均数的离散程度,标准误差反映样本平均数对总体平均

matlab 计算图像的峰值信噪比PSNR以及均方根误差MSE
简介 PSNR 是最普遍,最广泛使用的评鉴画质的客观量测法,不过许多实验结果都显示,PSNR 的分数无法和人眼看到的视觉品质完全一致,有可能 PSNR 较高者看起来反而比PSNR 较低者差。 这是因为人眼的视觉对于误差的敏感度并不是绝对的,其感知结果会受到许多因素的影响而产生变化(例如:人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围

K近邻KNeighborsRegressor--StandardScaler标准化--mean_squared_error均方根误差 学习笔记
目录 np.abs()函数pd.sample()参数含义pd.str同时去掉分隔符和货币符号standarscaler注意点scipy.spatial中distance距离工具两点之间的距离两个数据之间的距离 使用Sklearn计算距离sklearn 计算均方根误差sklearn标准化 K近邻模型多变量knn模型测试K近邻 np.abs()函数 np.abs() : 计算数值各

算法基础7 —— 二分算法 (二分模板 + 洛谷-A-B数对 + 蓝桥杯-分巧克力) + 浮点二分(求一个数的三次方根 + 剪绳子)
闲聊 在经典的软件开发过程中,编写程序所需要的工作量只占软件开发全部工作量的10%~20%。 《软件工程导论》—— 张海藩 总结 二分查找 问题引入:在如下数组中,查找数字4的下标 —— 3。为了方便起见,数组0元素的位置不存储数据。 考虑两种查找方法: 线性查找:从前往后遍历数组,找到第一个元素为4的位置,记录并输出即可(假设数组中的所有元素并不相同)。时间复杂度为O(n)二分
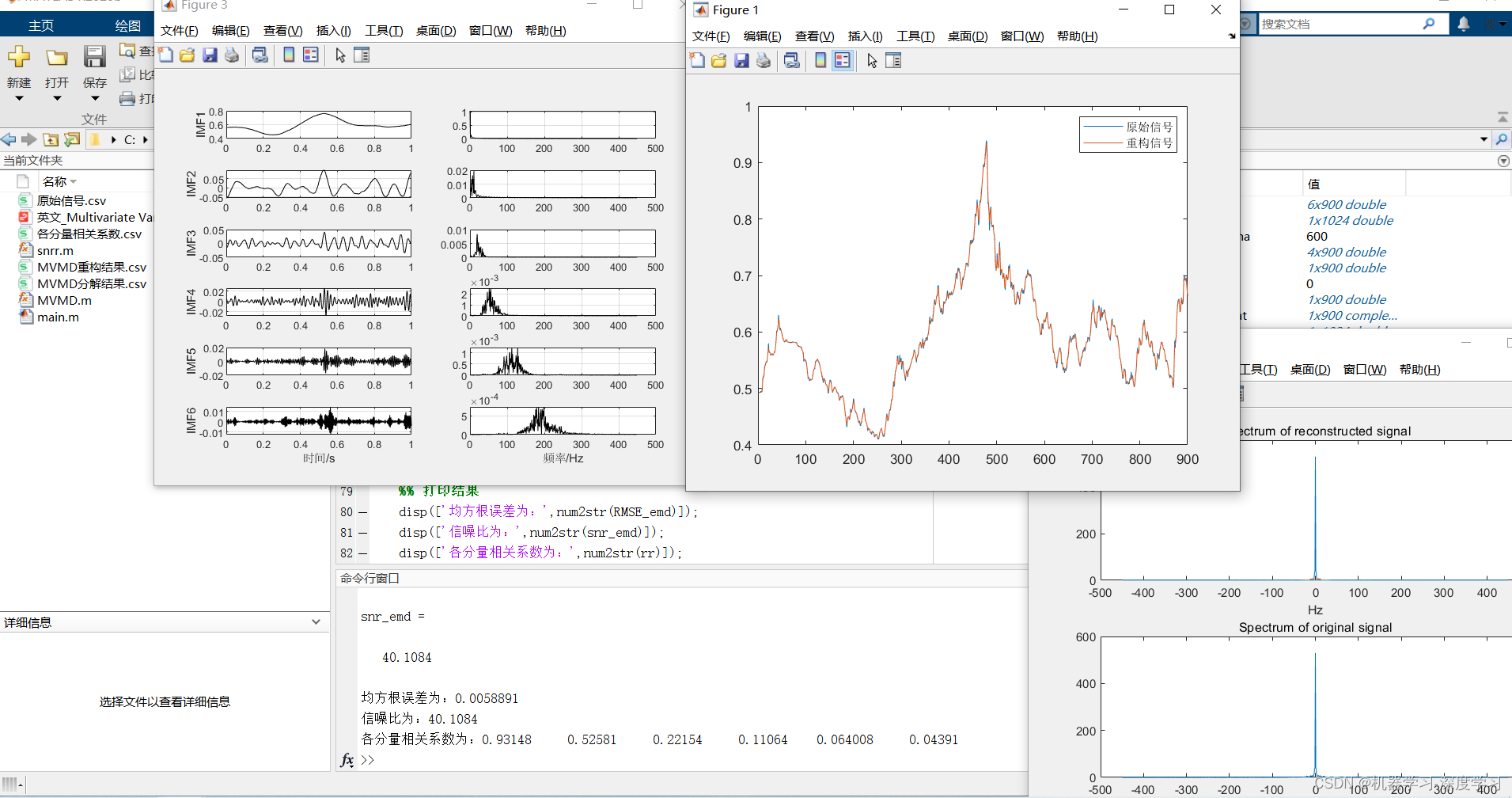
多元变分模态分解MVMD数据重构可输出均方根误差,信噪比,各分解分量的相关系数指标。附案例数据 可直接运行
close all clear all clc warning off %% 导入数据 signal=xlsread('原始信号.csv'); signal=signal(1:900)'; %% 参数设置 %----------------- 一些参数 ----------------- alpha=600; %惩罚因子 tau=0; init=1; K=6; DC=0; tol=1e-6;

基于C++/Java实现一个数的 N 次方根算法完整源码实现
原理介绍 给定两个数 N 和 A,求 A 的 N 次方根。在数学中,数 A 的 N 次方根是一个实数,当我们将 A 的整数次幂 N 求出时,它给出 A。这些根用于数论和其他领域数学的高级分支。 例子: Input : A = 81N = 4Output : 3 3^4 = 81 由于这个问题涉及一个实值函数 A^(1/N),我们可以使用牛顿法来解决这个问题,该方法从初始猜测开始,然
Acwing.790 数的三次方根
题目 给定一个浮点数n,求它的三次方根。 输入格式 共一行,包含一个浮点数n。 输出格式 共—行,包含一个浮点数,表示问题的解。注意,结果保留6位小数。 数据范围 -10000 ≤n ≤10000 输入样例: 1000.00 输出样例: 10.000000 题解 #include <iostream>using namespace std;int main(){d