数据流专题

数据流与Bitmap之间相互转换
把获得的数据流转换成一副图片(Bitmap) 其原理就是把获得倒的数据流序列化到内存中,然后经过加工,在把数据从内存中反序列化出来就行了。 难点就是在如何实现加工。因为Bitmap有一个专有的格式,我们常称这个格式为数据头。加工的过程就是要把这个数据头与我们之前获得的数据流合并起来。(也就是要把这个头加入到我们之前获得的数据流的前面) 那么这个头是

微信小程序(一)数据流与数据绑定
一、单向数据流和双向数据流 1、单项数据流:指的是我们先把模板写好,然后把模板和数据(数据可能来自后台)整合到一起形成HTML代码,然后把这段HTML代码插入到文档流里面 优点:数据跟踪方便,流向单一,追寻问题比较方便【主要体现:微信小程序】。 缺点:就是写起来不太方便,如果修改UI界面数据需要维护对应的model对象 2、双向数据流:值和UI是双向绑定的,大家都知道,只要UI里面的值发生

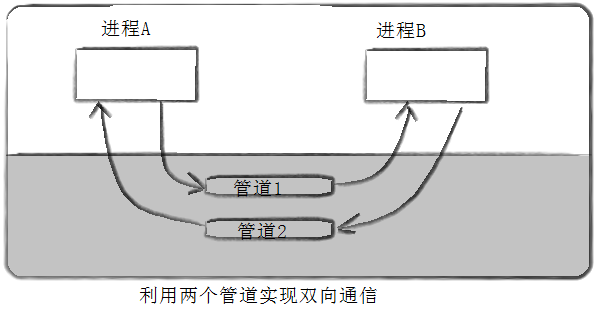
Linux | 匿名管道和命名管道:进程间通信数据流的桥梁
目录 1、进程间通信目的 2、管道——匿名管道和命名管道 匿名管道 匿名管道的示例代码:将数据写入管道、子进程从管道读取数据并将其输出到bash中 父子进程通过匿名管道建立通信 重点:管道的五个特点 命名管道(也称为FIFO) a. 创建命名管道 - mkfifo() b. 使用open函数打开命名管道文件 c. 读写命名管道- read() 和 write() d. 关闭和

vue学习十一(全局局部组件、prop传不同值、 v-bind 动态赋值、单向数据流、prop校验)
文章目录 全局注册局部注册dom模板解析注意事项用 Prop 传递不同值类型用 Prop通过 v-bind 动态赋值用 Prop传递对象的所有属性用 Prop传递对象数组用 Prop传入一个数字单向数据流Prop 验证 全局注册 我们只用过 Vue.component 来创建组件 这些组件是全局注册的。也就是说它们在注册之后可以用在任何新创建的 Vue 根实例 (new Vu
软件设计文档绘图:流程图、数据流图、UML
摘要: 在软件设计过程中,编写详尽的文档是不可或缺的一环,而图形化表达则是这些文档中至关重要的组成部分。为了清晰、直观地展示系统结构、数据处理流程以及设计思想,设计师们常常运用多种图表来辅助说明。其中,最为常用且高效的图形包括流程图、数据流图以及统一建模语言(UML)图。 流程图:流程图是描述一系列顺序性操作步骤的经典工具,它通过图形化的方式展示了从起点到终点的流程逻辑。在软件设计中,流程图

【软考】——数据流图
在软考学习中,下午题的前三道:数据流图,ER模型,UML图是基本上不能失分的,这几个题是最基本的题,出题的形式都是固定的,而数据流图这道题拿满分最重要的是耐心和细心的分析试题。 考点突破 ①补充数据流图的缺失部分,包括补充数据流、补充外部实体及补充数据存储。——实体出现的频率比较多 ②数据流图的改错,包括改正数据流名称,数据流的起始点与终点及删除多余数据流——通过仔细

力扣第71题:简化路径 放弃栈模拟,选择数据流√(C++)
目录 题目 思路 解题过程 复杂度 Code 题目 给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。 在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'/

软工总结(7—9)——数据流图
在总结需求分析的时候说道,需求分析过程中分析与综合的常用分析方法是SA,上次总结的时候总感觉有点模糊这次在总结一下。 在这里先介绍下SA数据那个部门。 结构是指系统内各个组成要素之间的相互联系、相互作用的框架。结构化开发方法提出了一组提高 软件结构 合理性的准则,如分解与抽象、 模块独立性 、 信息隐蔽 等。针对 软件生存周期 各个不同的阶段,它有

C语言 | Leetcode C语言题解之第352题将数据流变为多个不想交区间
题目: 题解: typedef struct SummaryRanges{int left,right;struct SummaryRanges *pre,*next;} SummaryRanges;/** Initialize your data structure here. */SummaryRanges* summaryRangesCreate() {SummaryRanges
leetcode刷题(42)——703. 数据流中的第K大元素
设计一个找到数据流中第K大元素的类(class)。注意是排序后的第K大元素,不是第K个不同的元素。 你的 KthLargest 类需要一个同时接收整数 k 和整数数组nums 的构造器,它包含数据流中的初始元素。每次调用 KthLargest.add,返回当前数据流中第K大的元素。 示例: int k = 3;int[] arr = [4,5,8,2];KthLargest kthLar

序列化和传输大型数据流
1.前言 理解WCF的序列化形式 掌握DataContractSerializer序列化对象 比较性能 比较xmlSerializer序列化对象 大数据量传输设置 修改配置文件 设置编码 设置流模式 [DataContract] 数据契约则是定义服务端和客户端之间要传送的自定义数据类型。 那么该类型就可以

前端 JS 经典:单向数据流
前言:Vue 的父子组件通信就遵循单向数据流的原则,父组件传给子组件的参数,子组件只能使用,不能修改。 1. 核心概念 数据的拥有者才能修改数据。因为当数据出了问题后只需要去找数据的拥有者就可以了。如果在其他地方也修改这个数据,将来这个数据出了问题,我们要到处去找,不便于维护。 当需要在子组件中修改父组件中的数据时,不能直接修改,我们需要触发父组件的事件,让父组件去修改数据。保持数据单向原则

Apache Flink数据流的Fault Tolerance机制
简介 Apache Flink提供了一个失败恢复机制来使得数据流应用可以持续得恢复状态。这个机制可以保证即使线上环境的失败,程序的状态也将能保证数据流达到exactly once的一致性。注意这里也可以选择降级到保证at least once的一致性级别。 失败恢复机制持续地构建分布式流式数据的快照。对于那些只有少量状态的流处理应用,这些快照都是非常轻量级的并且可以以非常频繁的频率来构建快照而
【Kafka专栏 14】Kafka如何维护消费状态跟踪:数据流界的“GPS”
作者名称:夏之以寒 作者简介:专注于Java和大数据领域,致力于探索技术的边界,分享前沿的实践和洞见 文章专栏:夏之以寒-kafka专栏 专栏介绍:本专栏旨在以浅显易懂的方式介绍Kafka的基本概念、核心组件和使用场景,一步步构建起消息队列和流处理的知识体系,无论是对分布式系统感兴趣,还是准备在大数据领域迈出第一步,本专栏都提供所需的一切资源、指导,以及相关面试题,立刻免费订阅,开启Kafka学
Qt | QDataStream 类(数据流)
01、读/写对象原理 1、QDataStream 类负责以二进制方式读/写程序中的对象,输入源和输出目样标可以是QIODevice、QByteArray 对象。 2、字节序:即多字节数据(即大于一个字节的数据)在内存中的存储顺序,有如下两种方式 Little-Endian(LE,小端):即低位字节存储在低地址端,高位字节存储在高地址端 Big-Endian(BE,大端):即高位
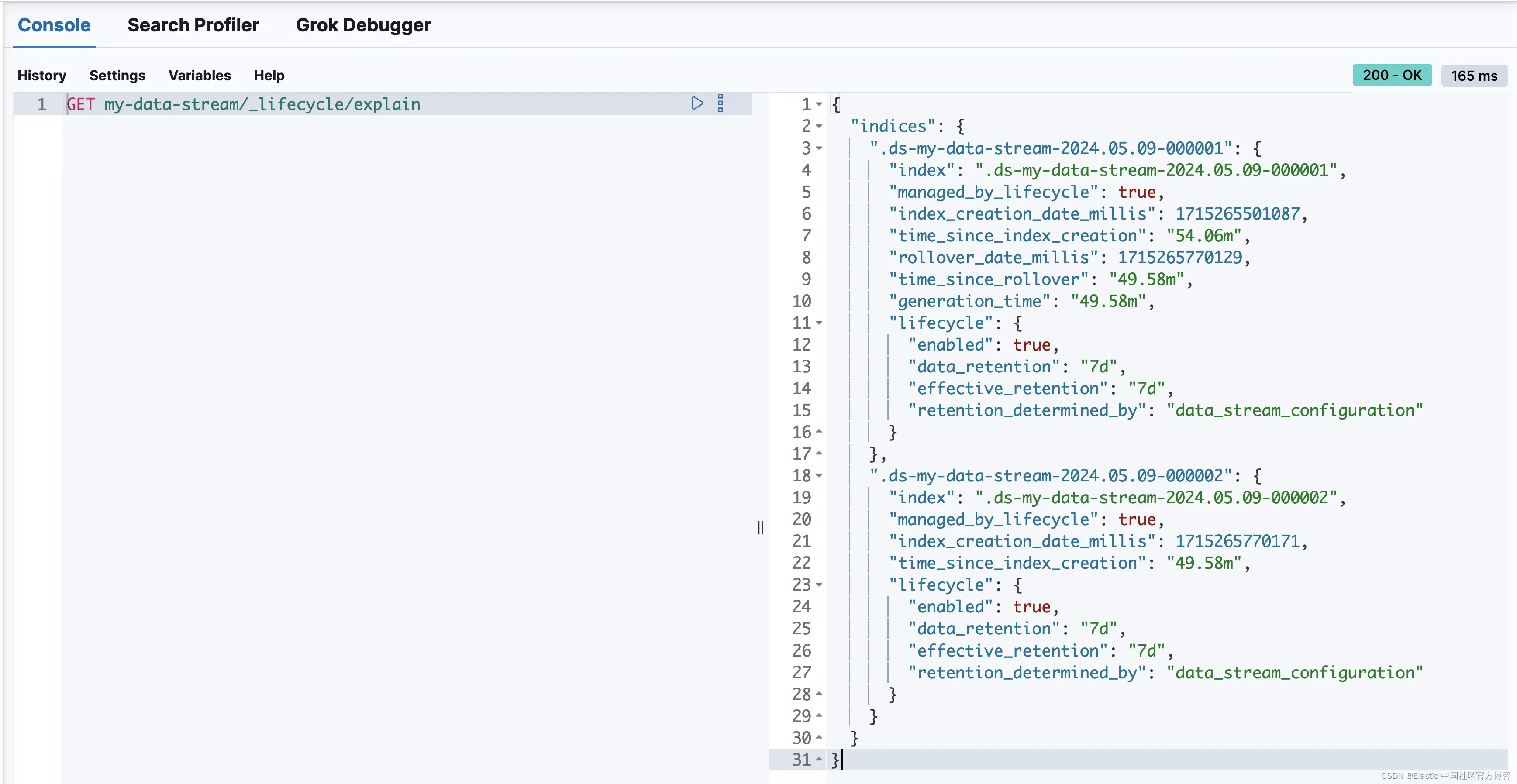
Elasticsearch:简化数据流的数据生命周期管理
作者:来自 Elastic Andrei Dan 今天,我们将探索 Elasticsearch 针对数据流的新数据管理系统:数据流生命周期,从版本 8.14 开始提供。凭借其简单而强大的执行模型,数据流生命周期可让n 你专注于数据生命周期的业务相关方面,例如降采样和保留。在后台,它会自动确保存储数据的 Elasticsearch 结构得到有效管理。 Elasticsearch 中的数据
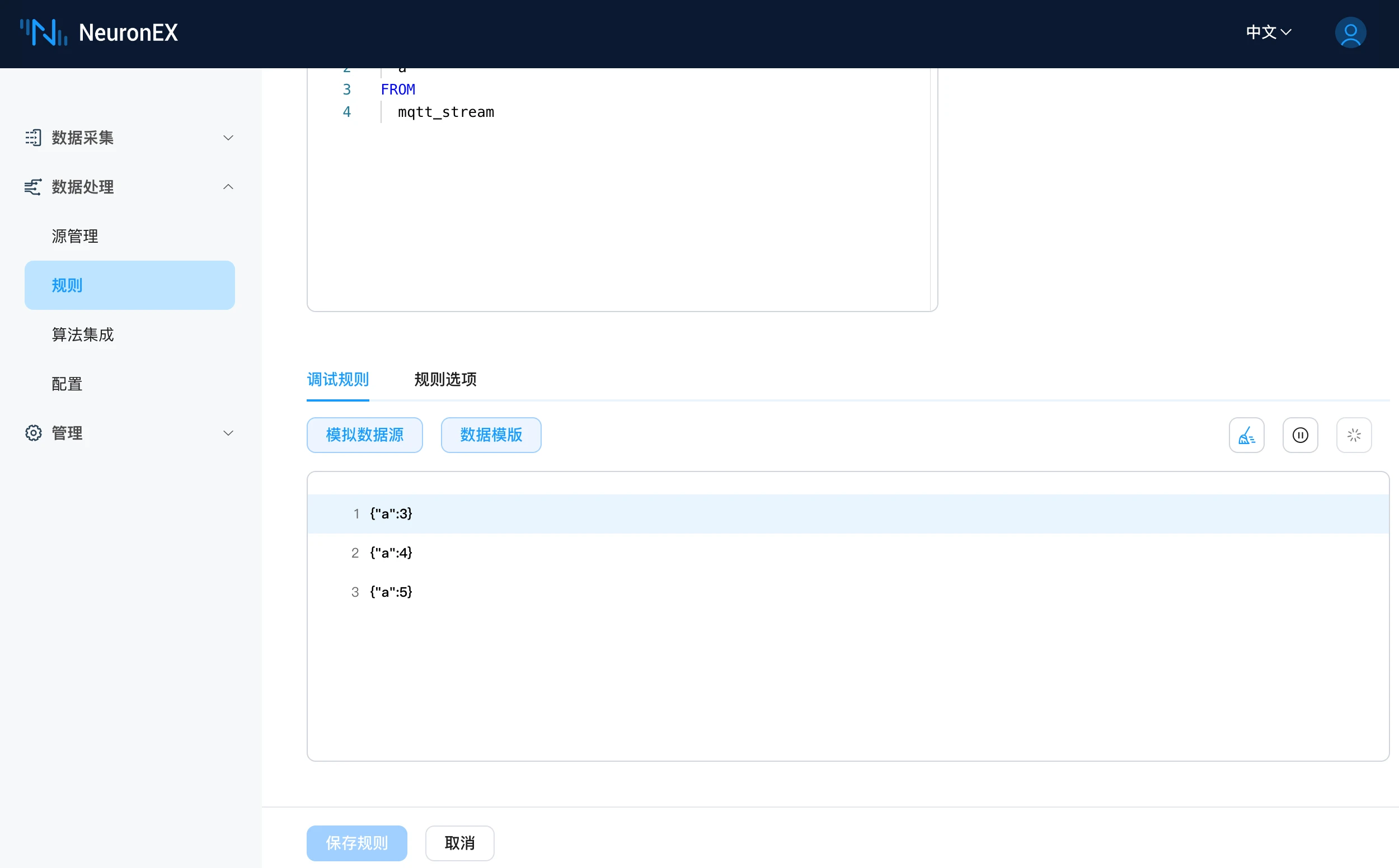
解锁工业数据流:NeuronEX 规则调试功能实操指南
工业企业要实现数据驱动的新质生产力升级,一个重要的环节便是如何准确、可靠地收集并利用生产过程中的数据流。 NeuronEX 工业边缘软件中的规则调试功能,可帮助用户在安全的环境中模拟数据输入,测试和优化数据处理规则,从而提前发现并解决潜在问题。规则调试功能对于实现智能制造、远程监控和预防性维护等应用尤为关键,能够有效提升生产效率,降低运营成本,同时保障系统的稳定性和安全性。 作为一款专为工业场
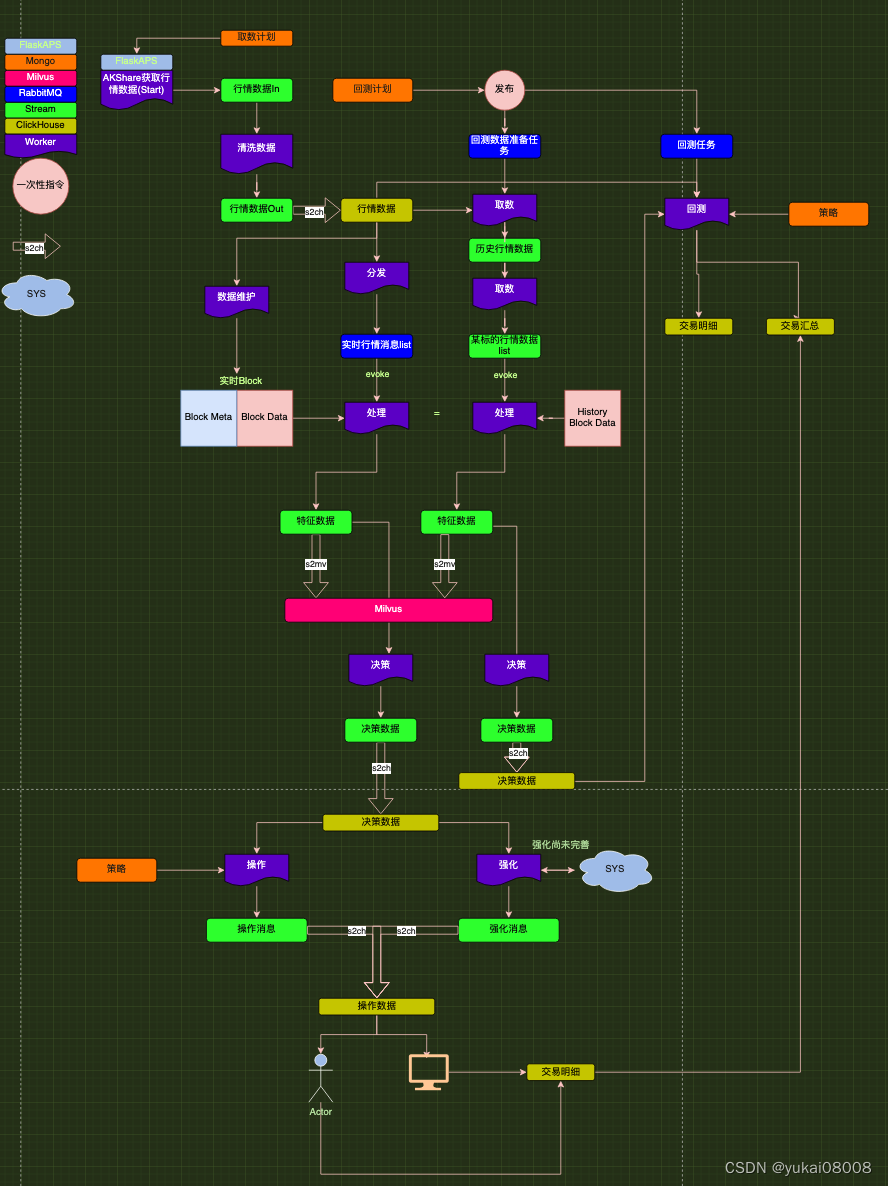
Python 算法交易实验71 QTV200数据流设计
说明 结构作为工程的基础,应该在最初的时候进行合理设计。这一次版本迭代,我希望最终实现的效果,除了在财务方法可以达到预期,在工程方面应该可以支持长期的维护、演进。 内容 1 财务表现期待 假设初始为60万资金作为主动资金(追求短期效益,交易频次为1天到7天),40万资金作为被动资金(追求长期利益,交易频次为周,月)。之前对qtv102的估计是月利率3%左右,翻倍期是24个月。 从风控考虑

《剑指offer》刷题笔记(树):数据流中的中位数
《剑指offer》刷题笔记(树):数据流中的中位数 转载请注明作者和出处:http://blog.csdn.net/u011475210代码地址:https://github.com/WordZzzz/Note/tree/master/AtOffer刷题平台:https://www.nowcoder.com/题 库:剑指offer编 者:WordZzzz 剑指offer刷题

【Vue】开启严格模式及Vuex的单项数据流
文章目录 一、引出问题二、开启严格模式 一、引出问题 目标 明确 vuex 同样遵循单向数据流,组件中不能直接修改仓库的数据 这样数据的流向才会更加清晰,将来对数据的修改,都在仓库内部实现的,更易于维护 直接在组件中修改Vuex中state的值 Son1.vue button @click="handleAdd">值 + 1</button>methods:{

力扣hot100:295. 数据流的中位数(两个优先队列维护中位数)
LeetCode:295. 数据流的中位数 这个题目最快的解法应该是维护中位数,每插入一个数都能快速得到一个中位数。 根据数据范围,我们应当实现一个 O ( n l o g n ) O(nlogn) O(nlogn)的算法。 1、超时—插入排序 使用数组存储,维持数组有序,当插入一个元素时使用插入排序维持数组有序,这种方式无异于使用插入排序,时间复杂度不达标。 时间复杂度: O ( n 2
数据流图要点和难点实际应用
数据流图(Data Flow Diagram,DFD)是一种图形化表示信息系统中数据流动和处理的方式。它主要用于描述系统如何接收输入数据,经过一系列的处理步骤,然后产生输出数据。数据流图在系统设计阶段特别有用,因为它可以帮助开发人员、业务分析师和其他利益相关者更好地理解系统的功能和数据需求。 数据流图主要由四种元素组成: 外部实体(External Entity):也称为数据源或数据宿
通过PPP连接GSM的一个数据流实例
接收:7E FF 7D 23 C0 21 7D 21 7D 21 7D 20 7D 32 7D 22 7D 26 7D 20 7D 2A 7D 20 7D 20 7D 23 7D 24 C0 23 7D 27 7D 22 7D 28 7D 22 55 83 7E 发送:7E FF 7D 23 C0 21 7D 21 7D 21 7D 20 7D 34 7D 22 7D 26 7D 20 7D 2

【优选算法】优先级队列 {经验总结:优先级队列解决TopK问题,利用大小堆维护数据流中的中位数;相关编程题解析}
一、经验总结 优先级队列(堆),常用于在集合中筛选最值或解决TopK问题。 提示:对于固定序列的TopK问题,最优解决方案是快速选择算法,时间复杂度为O(N)比堆算法O(NlogK)更优;而对于动态维护数据流中的TopK,最优解决方案是堆算法,每次添加数据后筛选,时间复杂度为O(logK)比快速选择算法O(N)更优; 优先级队列如何解决TopK问题? 创建一个大小为K的堆循环 将数组
Vue3实战笔记(55)—Vue3.4新特性揭秘:defineModel重塑v-model,拥抱高效双向数据流!
文章目录 前言defineModel() 基本用法总结 前言 v-model 可以在组件上使用以实现双向绑定。 从 Vue 3.4 开始,推荐的实现方式是使用 defineModel() 宏 defineModel() 基本用法 定义defineModel(): <!-- Child.vue --><script setup>const model = de