本文主要是介绍Python 算法交易实验71 QTV200数据流设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
结构作为工程的基础,应该在最初的时候进行合理设计。这一次版本迭代,我希望最终实现的效果,除了在财务方法可以达到预期,在工程方面应该可以支持长期的维护、演进。
内容
1 财务表现期待
假设初始为60万资金作为主动资金(追求短期效益,交易频次为1天到7天),40万资金作为被动资金(追求长期利益,交易频次为周,月)。之前对qtv102的估计是月利率3%左右,翻倍期是24个月。
从风控考虑,一个月最多允许1/3的主动资金交易,因此可参与计算复利的资金是20万。在24个月之后,收益20万,对于主动资金来说,利润率大约是33%,年化利率大约15%。被动资金大约也可以参考这个水平。整体上可认为QTV102的获利水平大约处于勉强及格的状态。
QTV200在架构上、算法上会有较大的突破。架构上可以确保足够量的交易(以支持统计)以及足够方便的交易提示(手工交易)。算法上会将双刃剑升级到大砍刀,并开发风险模型:修正学习目标,提供多一个种类的策略模式。所以,月利润率有希望达到5%,当然,关于实测月利润率会在后续进行更多的实验修正估计。如果是5%的话,还是非常客观的。
24个月和72个的利润为40万和600万,年化利润率 29%, 49%。
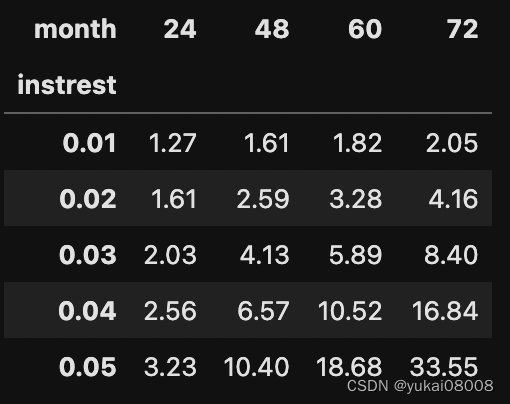
让后再放一张长点的图:我一直认为,一个大的目标如果可以分摊到很长的时间上,就会变得简单。难的是在于找到那个正确的规律,然后慢慢坚持下来。

2 数据流
要能做的足够长久,或者换一个角度,确保这事能够搞成,首先是在架构上。架构的作用是保持整个项目在长期运转的过程中保持清晰:这样在任何时候想要增加内容都不会乱。而且由于某些流转过程的标准化,会使得整体运行效率更高,也更简单(在配置新的流时)。
今年和去年比起来,工具更完善了。去年做的时候还是ADBS,采用APS方式,在一个周期内把多个流程运行一遍:数据获取、数据入Stream、到Mongo,中间还使用了APIFunc。虽然后面对ADBS项目的快速初始化做了改进,但一个个的ADBS之前还是独立的。总之,上一版做的较为零散,手工。
现在增加了新的数据库(ClickHouse、Milvus),特别是前者,在进行数据读取的时候比Mongo要快很多,几乎可以等于内存;然后(再次)搭好了Flask-APS-Celery。过去存在一些误解,想使用Celery来执行所有任务,然而这是不太可能的。但是执行通用任务,例如数据流转,这完全是可行的。而复杂的任务会被抽象到API里,celery只要发起API调用就好了,这恰恰也是celery擅长的(异步调用)。未来,在各种数据库Agent中,在读取方面应该都改为异步会更合理。(写入方面我觉得阻塞就阻塞,问题不大)。无论如何,我觉得这些改进会使得这个版本的调度和吞吐能力大幅增强。
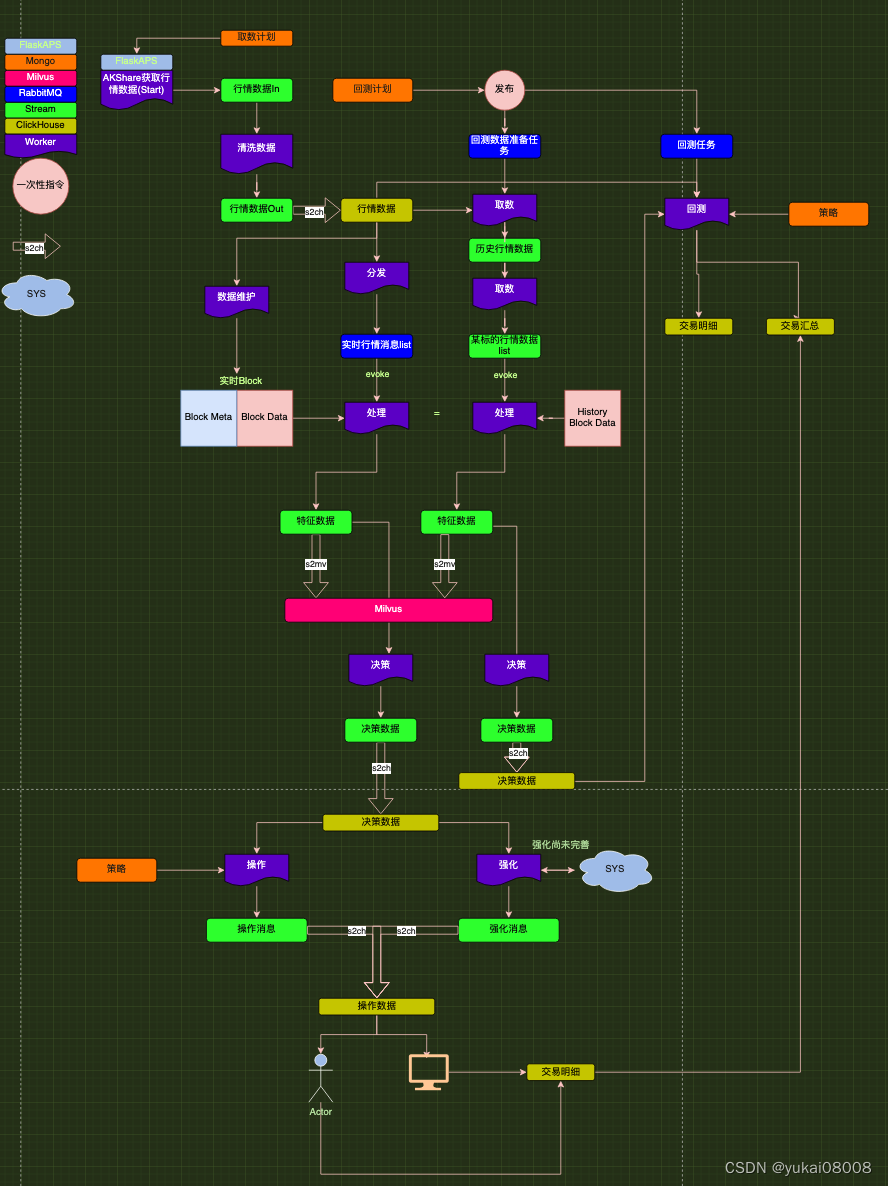
对下图的解释如下:
- 1 首先在Mongo里设定好计划,这个目前用IPython+ MongoEngine操作,之后可以很容易拓展为前端
- 2 这些计划将会通过FlaskAPS进行定时执行,然后调用Celery Worker。
- 3 行情数据会随着Worker的执行,被写入Stream In。
- 4 另一个负责清洗的Worker会把Stream In中的数据处理完放到Stream Out。【这里有一个新约定,worker只和stream或RabbitMQ挂钩,一个入,一个出。】
- 5 行情数据将会通过固定的任务流,类型为s2ch(Stream To ClickHouse)自动同步。到这里,原始数据的获取完成。
- 6 接下来,如果是在生产状态下,一个特定的Worker将会定时将行情数据的Block数据取出,存在Redis中。
- 7 另一个worker,会将新的行情数据取出,放到RabbitMQ中。
- 8 负责处理特征的worker将会因此触发处理,读取最新的Block数据,调用特征处理接口,和计算评分,结果存于Stream
- 9 Steram中的向量通过固定s2mv(Stream To Milvus)保存于Milvus。
- 10 Stream中的评分将会通过另一负责决策的worker,通过调用模型参数给出。结果放在决策数据Stream中。
- 11 决策数据Stream将通过s2ch,自动同步到ClickHouse中。
- 12 负责操作的worker将从决策数据中提取数据,结果送到操作消息Stream中。
- 13 负责实时强化的worker将提取决策数据,在另一个体系中进行模拟计算,返回强化消息。
- 14 操作消息和强化消息将同时存在操作数据中,有些操作在过一段时间后可能会被强化消息中的控制字段阻断。
- 15 前端通过操作数据 ,将信息反馈给人操作,或未来交给交易接口。
在训练/回测过程中,将会有回测计划,目前也是通过手工发送一次性指令。这个过程分为两个阶段:数据准备和运行回测。
在数据准备阶段,取数Worker将会遍历执行到最新 ,每次将数据写入历史行情数据Stream。然后某个标的的取数worker将会再次取出,结果送到某个标的的stream out(里面的行情数据只是起到元数据作用).特定的worker将会拉取(pull)相关的历史块数据,然后进行批量的特征成成和决策数据生成。结构上,开发和实时worker都是采用相同的接口,所以数据是高度一致的。
决策数据全部写完后,回测开始启动,在过程中将会按照回测时段和策略,将模拟交易写到交易明细表中,在回测结束时,会进行相应的汇总,写入交易汇总表中。
实操时,这个体系自然会横向扩充为对个标的的计算,多策略的实施,以及结果的汇聚统计。从而使得一个技术栈,最终表现为对业务的支持:我们可以关注在不同分支下,各策略的动态表现,从而形成一个认知:当前系统可达到的水平(1~5%的月利率)。
这篇关于Python 算法交易实验71 QTV200数据流设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





