微博热专题
王菲k歌又上微博热搜,Python分析下微博网友评论
苏生不惑第174篇原创文章,将本公众号设为星标,第一时间看最新文章。 最近王菲状态话题上了微博热搜 https://weibo.com/1266269835/JjRLJ4Ygi 还和马云合唱了 如果云知道 5年不更新的微博下评论开始求开演唱会 https://weibo.com/1629810574/C8FqitZ9X 于是用Python抓取了下这条微博下的评论(前几十页评论

4年微博热搜数据,一次拿走
又是新的一年了,从2020年开始,就养成了定时备份各大平台热搜数据的习惯,微博,知乎都在备份,今天给大家看一下从2020年到2023年的微博热搜数据情况 这是2022年的备份数据,每天的热搜数据一个文件,数据绝对全 文件内部数据如上图,包括微博标题,当时的热度,热搜时间以及微博的URL地址 对于需要分析微博热搜数据的朋友来说,这份数据还是很值得分析的 当然了,由于本人也是花费了一定

逆向微博热搜时光机(js逆向)
直接分析,我们需要先查询一下网络请求的方式,通过使用反页请求,我们可以知道这个时光机的本质上是通过ajax请求进行的数据传输,所以这里我们可以减少查询的范围,可以直接调试查找XHR类型的数据传输内容,这里我推荐大家使用翻页后的数据查询,主要是为了鉴定一下该参数的携带加密位置(timeid) 直接使用浏览器抓包,我们会发现这里出现了一个无限debugger,直接找的这行使用右键直接一律不在此执行,

简单使用selenium抓取微博热搜话题存储进Excel表格中
#test.pyimport requestsfrom selenium import webdriverimport timefrom write import write#首先打开浏览器drive = webdriver.Chrome()#设置隐式等待:等待元素找到,如果找到元素则马上继续执行语句,如果找不到元素,会在设定时间内不断请求寻找元素,当超过设定时间还未找到,则抛出异常

访问微博热搜榜,获取微博热搜榜前50条热搜名称、链接及其实时热度,并将获取到的数据以邮件的形式发送,每20秒一次发送到个人邮箱中。
一、需求 访问微博热搜榜(Sina Visitor System),获取微博热搜榜前50条热搜名称、链接及其实时热度,并将获取到的数据通过邮件的形式,每20秒发送到个人邮箱中。 注意事项: 定义请求头 本实验需要获取User-Agent、Accept、Accept-Language、Cookie四个字段,前三个字段可能都是相同的,主要是Cookie不同。具体获取流程如下: 打开目标网页
Vue3项目创建+组合式API使用+组件通信+渲染微博热搜+打包上线
摘要 Vue3的组合式API大大减少了代码量,以及使用也方便了很多,本案例使用Vite创建一个Vue3示例,简单介绍Vue3的组合式API使用以及父传子组件传参示例。 创建Vue3项目 1、首先要安装 Node.js 下载地址:https://nodejs.org/en/download 2、安装完成后,创建一个文件夹,用于创建 Vue 项目,我是在桌面创建的 3、在你创建的文件夹内的路径这

Python 分析样例|数据采集案例:微博热搜榜采集
实现目标 本案例通过图文详细介绍网络请求和解析的方法,其目标实现的需求为:通过网络请求,获取微博热搜榜中的前50条热搜的关键词,并将结果打印到控制台中。 实现过程 总体来说,数据采集爬虫的实现过程包括如下步骤: 确定数据所在的Url执行网页请求并解决请求中出现的问题解析网页,获取格式化数据存储数据(当前案例中不需要) 下面我们按着以上步骤来依次完成。 确定数据所在Url 打开微博热搜
如何利用request和正则表达式获取微博热搜榜
其实这个是很简单的,网上有很多教程,虽然说微博热搜榜是动态数据,但是数据存储确实可以通过HTML来获取 https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6 注意微博是每分钟都跟新的,因此上一分组和下一分钟数据可能不完全相同 import re import requests from requests.exceptions
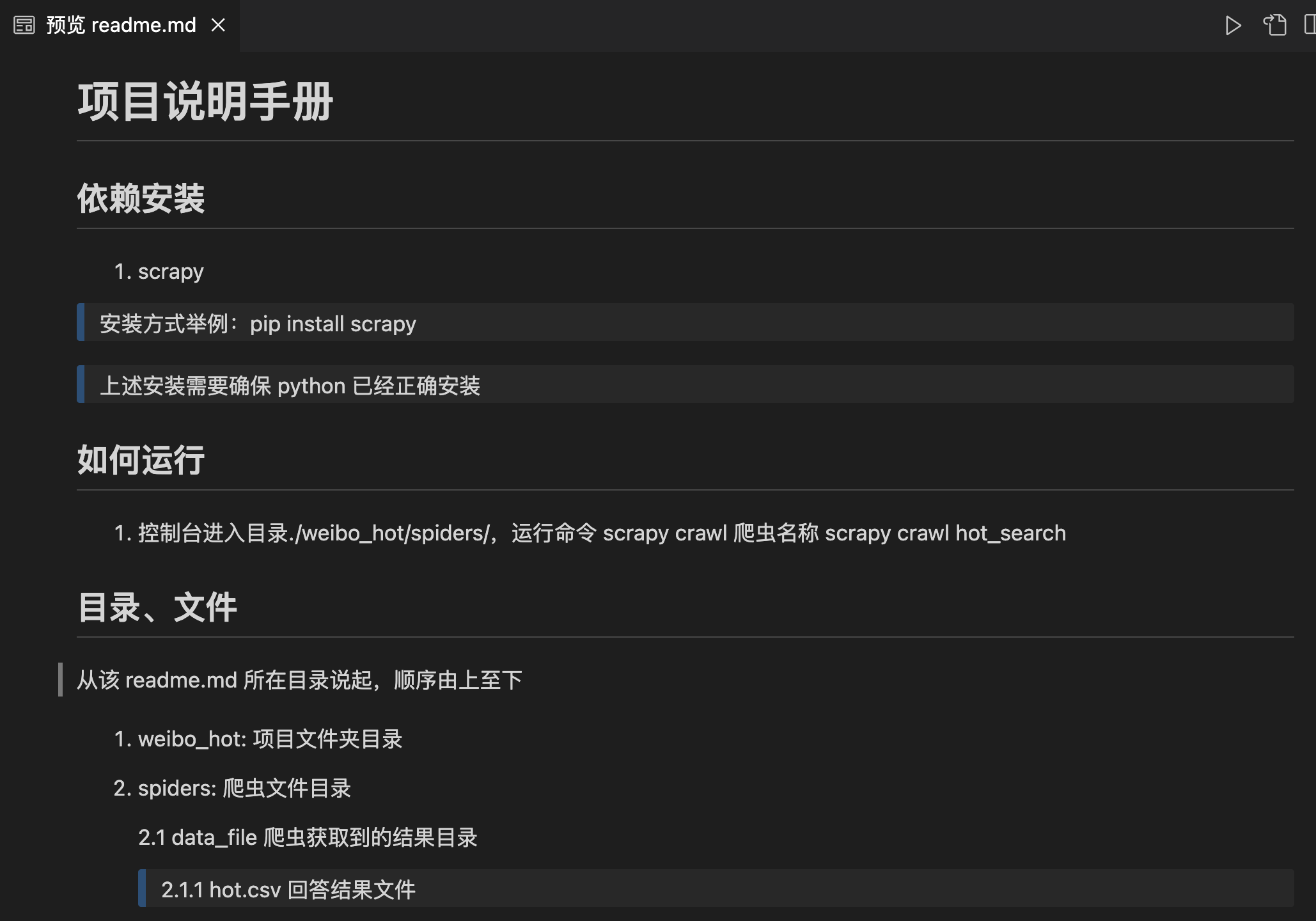
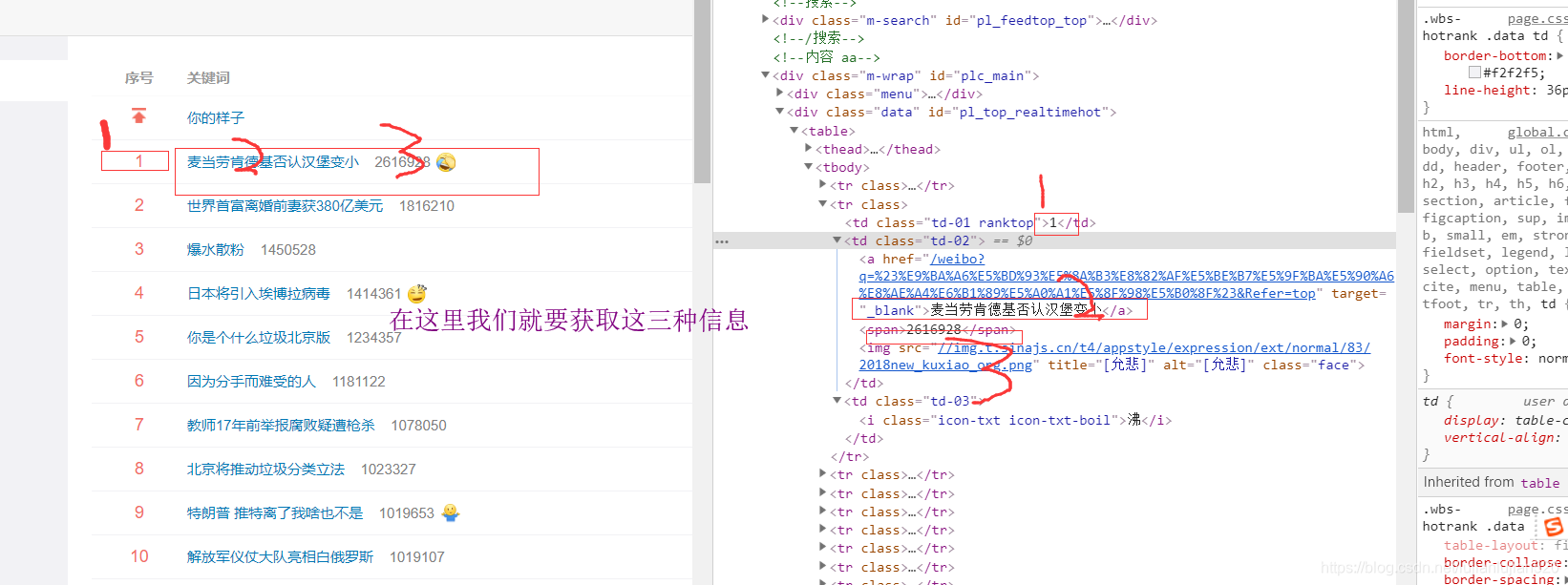
【爬虫实战】python微博热搜榜Top50
一.最终效果 二.项目代码 2.1 新建项目 本文使用scrapy分布式、多线程爬虫框架编写的高性能爬虫,因此新建、运行scrapy项目3步骤: 1.新建项目: scrapy startproject weibo_hot 2.新建 spider: scrapy genspider hot_search "weibo.com" 3.运行 spider: scrapy crawl

国内程序员这次牛逼了,「微博热搜」「GitHub 」双双霸榜了
这两天 996.ICU 突然霸榜 GitHub 日和周排行榜,昨天一天有近 2 万的 star 数,而就在今天 star 数已经高达 6 万 3 千多,不到一天的时间,竟然增加了近 4 万的 star 数。 996.ICU,旨在反抗国内互联网公司形成的每周工作 6 天、每天工作时间早 9 点到晚 9 点的不良加班风气。 这个旨在反抗互联网不良加班风气的开源项目到底有多可怕呢?我们看看下面这几个数

爬取微博热榜并将其存储为csv文件
🙌秋名山码民的主页 😂oi退役选手,Java、大数据、单片机、IoT均有所涉猎,热爱技术,技术无罪 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 获取源码,添加WX 目录 前言1. 热榜前50爬虫最后 前言 基于大数据技术的社交媒体文本情绪分析系统设计与实现,首先需要解决的就是数据的问题,我打算利用Python 语言的Scrapy、Beautiful Soup等工具抓