本文主要是介绍如何利用request和正则表达式获取微博热搜榜,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
其实这个是很简单的,网上有很多教程,虽然说微博热搜榜是动态数据,但是数据存储确实可以通过HTML来获取
https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6
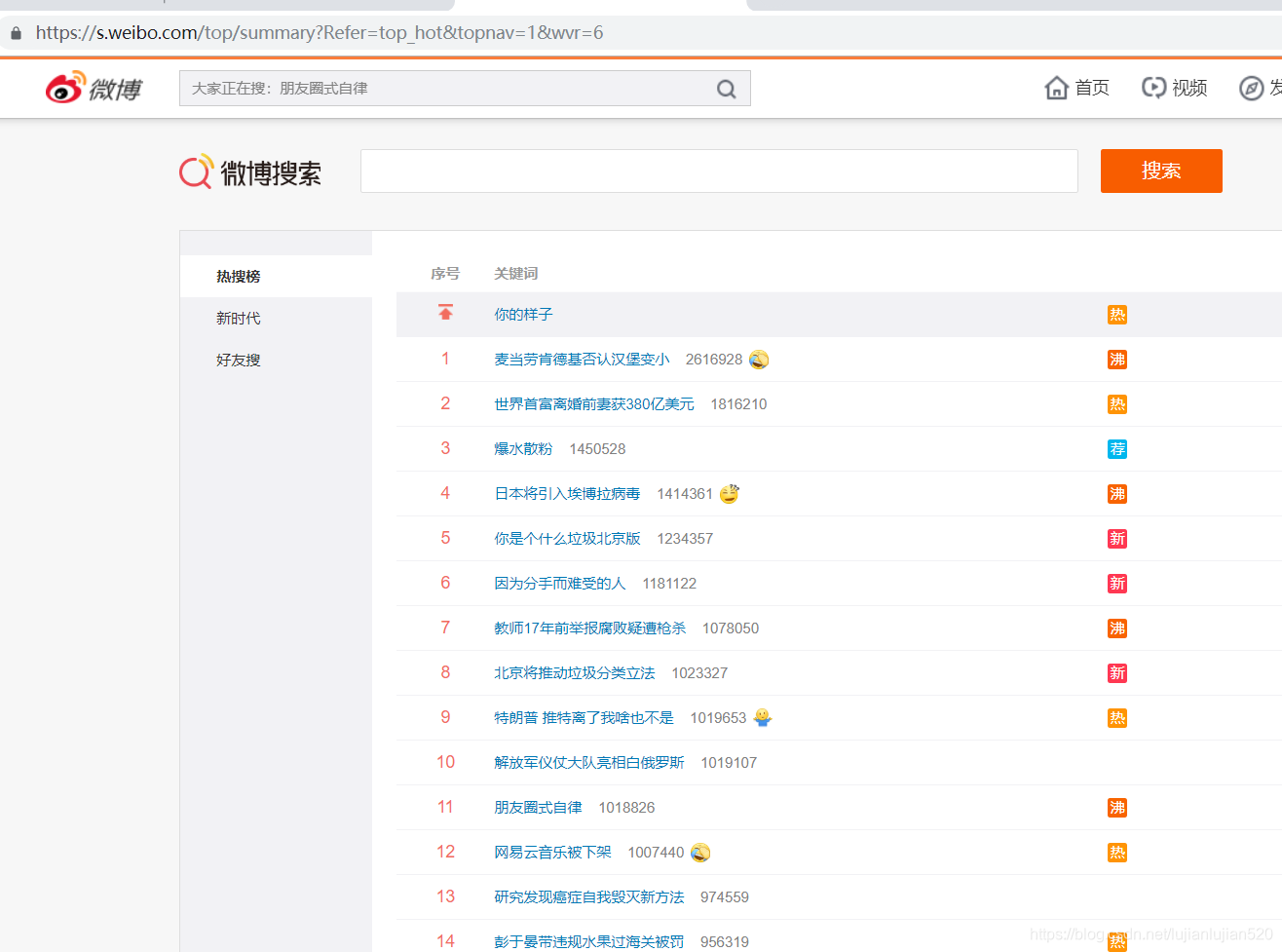
注意微博是每分钟都跟新的,因此上一分组和下一分钟数据可能不完全相同
import re
import requests
from requests.exceptions import RequestException
import json
headers={
‘User-Agent’:“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36”
}
def get_one_page(url):
try:
#之前我在公司,没有外网的情况下设置proxy,
#response=requests.get(url,proxy=proxy,headers=headers,verity=False),如果没有这个参数将报错,因为没有安全证书#问题在后面是如果遇到反爬虫建议设置爬去速度调慢一些time,sleep(3)
reponse=requests.get(url)
if reponse.status_code==200:
return reponse.text
return None
except RequestException:
return None
def parse_one_page(html):
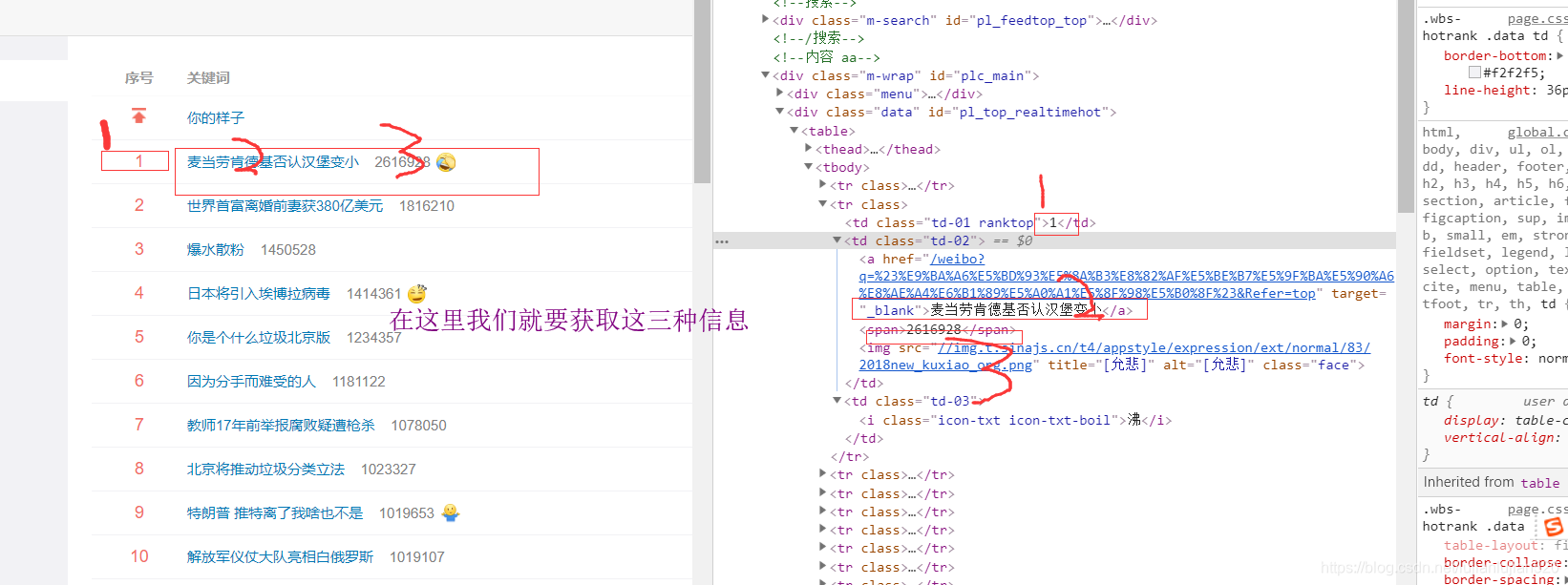
patterm=re.compile(’<tr.?<td.?ranktop">(\d+).?_blank">(.?).?(\d+).?’,re.S)
items=re.findall(patterm,html)
#return items
for item in items:
yield {
‘top’:item[0],
‘title’:item[1],
‘pop_nums’:item[2]
}
def write_to_file(conten):
path = ‘E:/test001/weibo%s.txt’ % time.strftime(’%Y_%m_%d’)
with open(path,‘w’,encoding=‘utf-8’) as f:
f.write(json.dumps(conten,ensure_ascii=False)+’\n’)
f.close()
def main():
url = ‘https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6’
html=get_one_page(url)
#print(html)
content=parse_one_page(html)
#print(content)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if name == ‘main’:
main()
这篇关于如何利用request和正则表达式获取微博热搜榜的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



