本文主要是介绍【爬虫实战】python微博热搜榜Top50,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
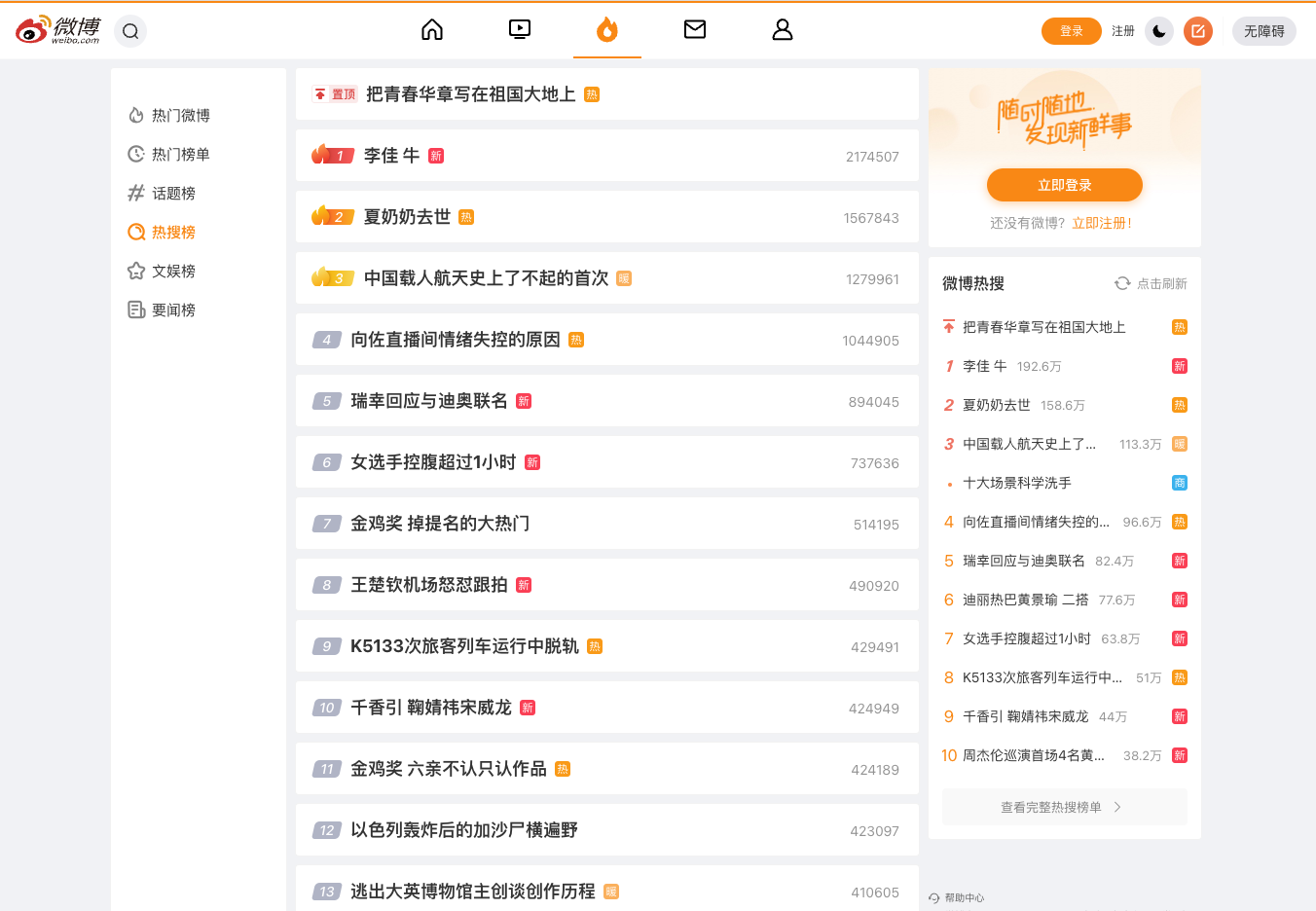
一.最终效果

二.项目代码
2.1 新建项目
本文使用scrapy分布式、多线程爬虫框架编写的高性能爬虫,因此新建、运行scrapy项目3步骤:
1.新建项目:
scrapy startproject weibo_hot
2.新建 spider:
scrapy genspider hot_search "weibo.com"
3.运行 spider:
scrapy crawl hot_search
注意:hot_search 是spider中的name
4.编写item:
class WeiboHotItem(scrapy.Item):index = scrapy.Field()topic_flag = scrapy.Field()icon_desc_color = scrapy.Field()small_icon_desc = scrapy.Field()small_icon_desc_color = scrapy.Field()is_hot = scrapy.Field()is_gov = scrapy.Field()note = scrapy.Field()mid = scrapy.Field()url = scrapy.Field()flag = scrapy.Field()name = scrapy.Field()word = scrapy.Field()pos = scrapy.Field()icon_desc = scrapy.Field()5.编写爬虫解析代码:
import os
from itemadapter import ItemAdapter
from .settings import DATA_URI
from .Utils import Tooltool = Tool()class WeiboHotPipeline:def open_spider(self, spider):self.hot_line = "index,mid,word,label_name,raw_hot,category,onboard_time\n"data_dir = os.path.join(DATA_URI)file_path = data_dir + '/hot.csv'#判断文件夹存放的位置是否存在,不存在则新建文件夹if os.path.isfile(file_path):self.data_file = open(file_path, 'a', encoding='utf-8')else:if not os.path.exists(data_dir):os.makedirs(data_dir)self.data_file = open(file_path, 'a', encoding='utf-8')self.data_file.write(self.hot_line)def close_spider(self, spider): # 在关闭一个spider的时候自动运行self.data_file.close()def process_item(self, item, spider):try:hot_line = '{},{},{},{},{},{},{}\n'.format(item.get('index', ''),item.get('mid', ''),item.get('word', ''),item.get('label_name', ''),item.get('raw_hot', ''),tool.translate_chars(item.get('category', '')),tool.get_format_time(item.get('onboard_time', '')),)self.data_file.write(hot_line)except BaseException as e:print("hot错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<错误在这里")return item三.注意事项
settings.py配置项修改
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # 关闭,否则根据weibo的爬虫策略爬虫无法获取数据如果
四.运行过程

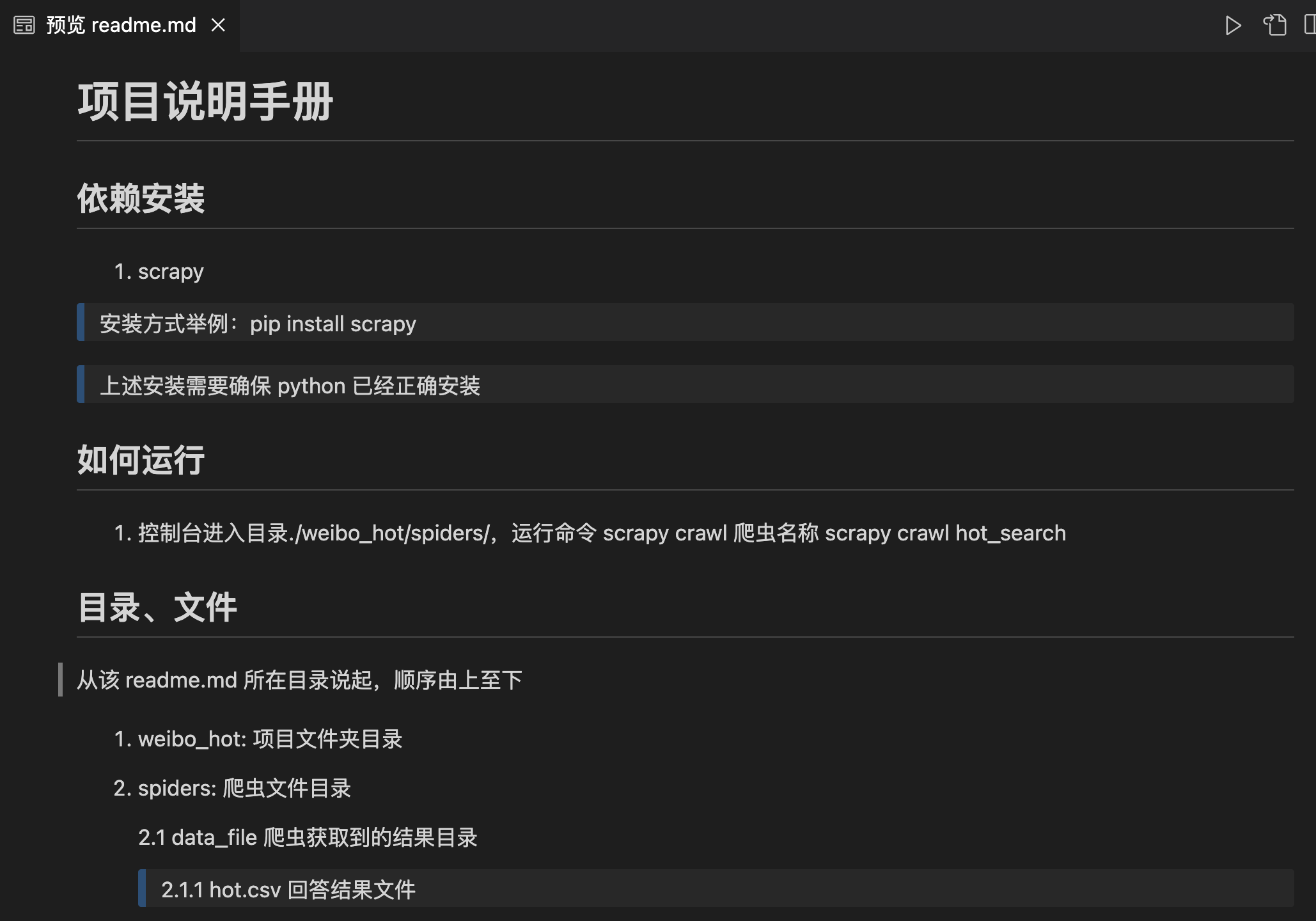
五.项目说明文档
六.获取完整源码
爱学习的小伙伴,本次案例的完整源码,已上传微信公众号“一个努力奔跑的snail”,后台回复 热搜榜 即可获取。
这篇关于【爬虫实战】python微博热搜榜Top50的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





