密度专题

振动分析-26-频域分析之深入理解功率谱和功率谱密度的计算过程
1 什么是PSD(功率谱密度) 功率谱密度(Power Spectral Density),以及其与Autopower(自功率谱)的区别。 1.1 PSD的定义 PSD——Power Spectral Density是表征信号的功率能量与频率的关系的物理量。 PSD经常用来研究随机振动信号。 PSD通常根据频率分辨率做归一化。 对于振动数据,PSD的单位通常是g^2/Hz。这个单位看起来不

【Python】数据可视化之核密度
KDEPlot(Kernel Density Estimate Plot,核密度估计图)是seaborn库中一个用于数据可视化的函数,它基于核密度估计(KDE)这一非参数统计方法来估计数据的概率密度函数。KDEPlot能够直观地展示数据的分布特征,对于单变量和双变量数据均适用。 目录 基本思想 主要参数 沿轴绘制 平滑调整 多类绘制 堆叠分布 二元分布 基本

android eclipse 根据屏幕密度自动生成不同分辨率的图片
android 提供了不同drawable资源包来进行适应不同的屏幕密度的android手机。 屏幕密度大设备的需要分辨率高的图片,屏幕密度小设备需要分辨率小的图片。他们也会根据自己的屏幕密度来相应读取不同drawable下的图片,以达到最佳的显示效果。 android的屏幕密度范围为:120(ldpi),160(mdpi),240(hdpi),,320(xhdpi)以及更高。现在

python可视化-密度图
1、加载数据 import pandas as pdimport numpy as npfrom sklearn.datasets import load_irisimport warnings# 禁用所有警告信息warnings.filterwarnings('ignore')# 加载数据iris = load_iris()iris iris.keys() df =

【机器学习】(5.4)聚类--密度聚类(DBSCAN、MDCA)
1. 密度聚类方法 2. DBSCAN DBSCAN(Density-Based Spatial Clustering of Applications with Noise)。一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为 密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有“噪声”的数据中发现任意形状的聚类。 2.1 DBSCAN算
poj3155--Hard Life(最大密度子图)
poj3155:题目链接 题目大意:给出了n个点,m条无向边,选一个集合M,要求集合中的边数/点数的最最大 参考:最小割模型在信息学竞赛中的应用 先做了0-1分数规划,然后最大权闭合图,然后是最大密度子图。最大密度子图要用到前两个知识点。 注意:精度问题,这个题的单调性会出现一段为0的值,所以要用二分逼近最左侧的那个,然后在二分完成后,要用low(左边界)再求一次,这样是最精确的 #

数据赋能((185)——开发:提高数据价值密度——实施过程、应用特点
实施过程 提高数据价值密度的实施过程通常包括以下几个步骤: 数据收集:根据业务需求,收集相关的数据资源。数据清洗:对收集到的数据进行清洗和预处理,去除重复、错误和无关的信息。数据分析:运用统计方法、机器学习等技术对数据进行深入分析,挖掘其中的有价值信息。价值评估:根据业务需求和数据分析结果,评估数据的价值密度,确定其潜在的经济价值和应用方向。应用实践:将高价值密度的数据应用于实际业务中,实现其
【屏幕参数】像素、分辨率、尺寸、像素密度
1. 像素 屏幕显示的最小单位,屏幕上的一个小亮点称为一个像素。 2. 分辨率 屏幕上横向和纵向的像素数量。 3. 尺寸 屏幕对角线的长度,以英寸(inches)为单位。 4. 像素密度 像素密度是每英寸屏幕上的像素数量,通常以 PPI(Pixels Per Inch)表示。较高的像素密度意味着在相同尺寸的屏幕上有更多的像素,从而提供更加清晰和细腻的图像。计算公式
数据赋能((184)——开发:提高数据价值密度——影响因素、直接作用、主要特征
影响因素 提高数据价值密度主要影响因素如下: 数据采集和处理: 数据采集的准确性、完整性和一致性是提升数据价值密度的基础。通过优化数据采集方法,确保数据来源的可靠性,并采用先进的数据处理技术,如数据清洗、去重和标准化,可以有效提升数据的准确性和一致性。数据分析和挖掘: 利用先进的数据分析和挖掘技术,如机器学习、深度学习等,可以深入探索数据中的隐藏模式和关联关系,发现数据背后的价值。通过提取有用

中国1KM网格灌丛土地密度数据集
灌木丛通过蒸腾作用释放水分到大气中,有助于调节局部气候,降低温度并增大湿度。灌木丛的根系能够固定土壤,防止风蚀和水蚀,从而保护土壤和地表水资源,不仅是自然景观的一部分,也是维护地球生态平衡和人类福祉的重要因素。 数据集收录了中国1KM网格灌丛土地密度数据,主要以tif的格式存储。
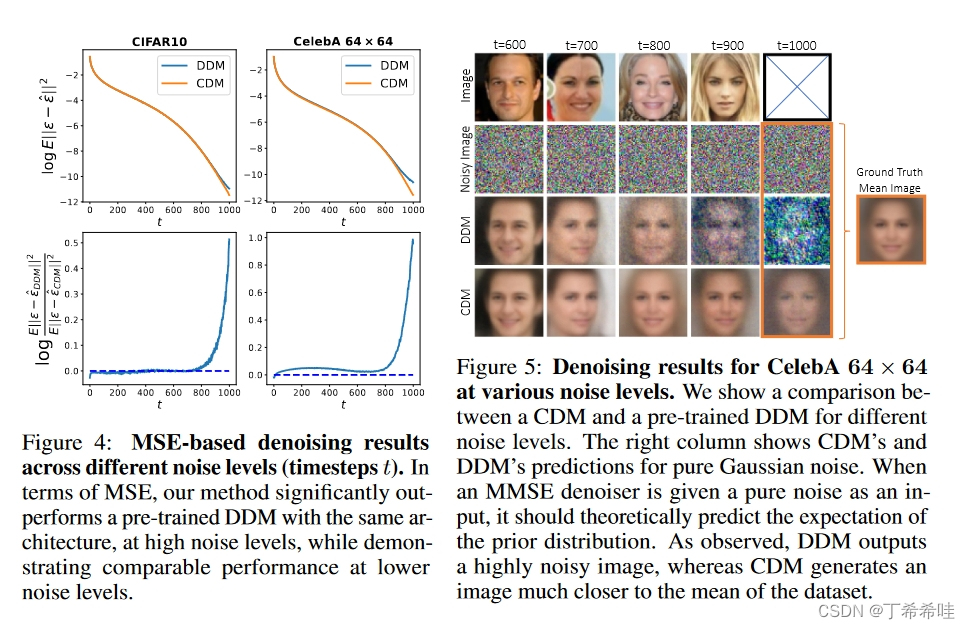
【论文精读】分类扩散模型:重振密度比估计(Revitalizing Density Ratio Estimation)
文章目录 一、文章概览(一)问题的提出(二)文章工作 二、理论背景(一)密度比估计DRE(二)去噪扩散模型 三、方法(一)推导分类和去噪之间的关系(二)组合训练方法(三)一步精确的似然计算 四、实验(一)使用两种损失对于实现最佳分类器的重要性(二)去噪结果、图像质量和负对数似然 论文:Classification Diffusion Models: Revitalizing

【阅读论文】-- SWS:时空核密度可视化的复杂性优化解决方案
SWS: A Complexity-Optimized Solution for Spatial-Temporal Kernel Density Visualization 摘要1 引言2 预备知识2.1 STKDV 问题陈述2.2 基于范围查询的解决方案(RQS) 3 基于滑动窗口的解决方案(SWS)3.1 时间维度的滑动窗口3.2 SWS:增量算法 4 SWS 用于其他时间内核4.1

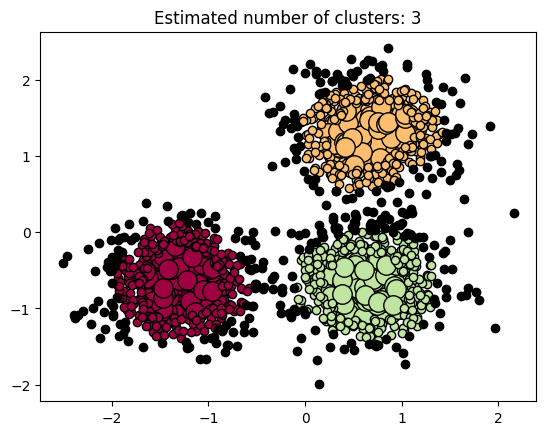
【聚类】基于位置(kmeans)层次(agglomerative\birch)基于密度(DBSCAN)基于模型(GMM)
原博文: 一、聚类算法简介 聚类是无监督学习的典型算法,不需要标记结果。试图探索和发现一定的模式,用于发现共同的群体,按照内在相似性将数据划分为多个类别使得内内相似性大,内间相似性小。有时候作为监督学习中稀疏特征的预处理(类似于降维,变成K类后,假设有6类,则每一行都可以表示为类似于000100、010000)。有时候可以作为异常值检测(反欺诈中有用)。 应用场景:新闻聚类、用户购买模式(交
基于密度的聚类算法DBSCAN详解!
公众号:尤而小屋编辑:Peter作者:Peter 大家好,我是Peter~ 今天给大家介绍基于密度的聚类算法DBSCAN,包含: DBSCAN算法定义sklearn.cluster.DBSCAN参数详解DBSCAN聚类实战DBSCAN聚类效果评估DBSCAN聚类可视化DBSCAN算法优缺点总结 https://scikit-learn.org/stable/auto_examp

分辨率,像素密度,Retina技术的理解与探讨!
http://bbs.feng.com/read-htm-tid-4016267.html 分辨率是我们最早接触到的名词,从早期的640*480到后来的1440*900等等,代表在屏幕的长和宽上所显示的像素点数。 像素密度是指在单位面积上所能显示的像素数量,密度越高,显示的像素就越多。 retina超高清技术就是在单位面积上增加像素的密度后,把原来一个像素显示的内容变成用4个
企业网络营销及网站关键词密度布局
企业网站营销能否达到成功的预定值,还要看如何营销和怎么排好关键词密度。 如何才能将企业的网络(营销)做到更好? 在从事网站建设和网络推广工作已经有将近5个年头了,而在合作过的客户之中有一部分客户经常会问道:“如何才能将企业的网络(营销)做到更好? 其是答案之一就是,企业和之间需要有完美的配合,就能将企业的网络发挥到极致。所谓配合有以下几方面;1、资料提供所谓"兵马未动粮草先行",欲做网

【氮化镓】高电容密度的p-GaN栅电容在高频功率集成中的应用
这篇文章是香港科技大学Kevin J. Chen等人与台积电M.-H. Kwan等人关于高电容密度的p-GaN栅电容在高频功率集成中的应用研究。 文章详细介绍了p-GaN栅电容的设计、特性和在高频功率集成中的应用。通过实验数据和理论分析,文章展示了p-GaN栅电容在实现高电容密度、低ESR和高Q因子方面的潜力。此外,文章还讨论了不同布局设计对电容器性能的影响,特别是多指交错布局在提高高频性能方面

数据可视化(十二):Pandas太阳黑子数据、图像处理——离散极值、核密度、拟合曲线、奇异值分解等高级操作
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊! 喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!数据源存放在我的资源下载区啦! 数据可视化(十二):Pandas太阳黑子数据、图像处理——离散极值、核密度、拟合曲线、奇异值分解等高级操作 目录 数据可视化(十二):Pandas太

Geotrellis学(踩)习(坑)笔记(一)——核密度分析
在geotrellis环境下成功运行了helloworld之后,我第一个尝试的核密度计算~整个过程还是挺艰难的。。。因为对scala非常地不熟,基本属于边写边学的状态T^T 嗯。。首先 核密度分析是什么??? 官方文档里对核密度分析有一段这样的介绍: Kernel density is one way to convert a set of points (an instance

中国GDP空间分布数据集、中国人口空间分布数据集、GDP密度分布、人口密度分布数据、夜间灯光分布数据、土地利用数据、道路网分布数据、乡镇边界分布
引言 GDP(国内生产总值)是指一个国家或地区所有常驻单位在一定时期内生产的所有最终产品和劳务的市场价值。GDP是表征宏观经济发展状况的基础性指标。GDP是社会经济发展、区域规划和资源环境保护的重要指标之一,通常以行政区为基本统计单元。GDP空间化以空间统计单元代替传统的行政统计单元,为多领域之间数据共享、进行空间统计分析带来极大便利。 正文 中国GDP空
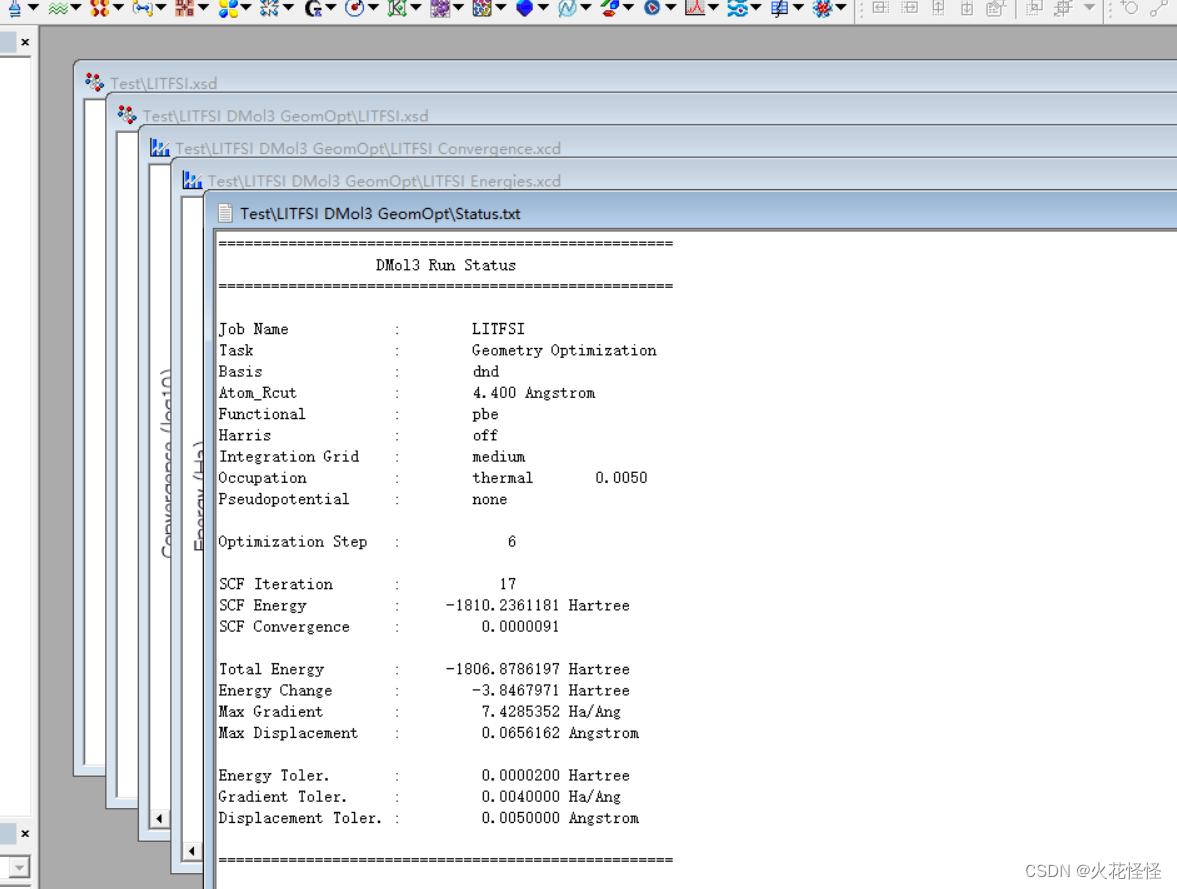
Material Studio 计算分子静电力、电荷密度以及差分电荷密度
1.先打开Material Studio导入要计算的分子cif文件或者mol文件,直接Flie-Import 2.高斯几何优化一下结构,参数按照我的设置就行,一般通用,后面出问题再调整 3.点完Run后会跳出很多计算过程,不用管,等他计算完就行
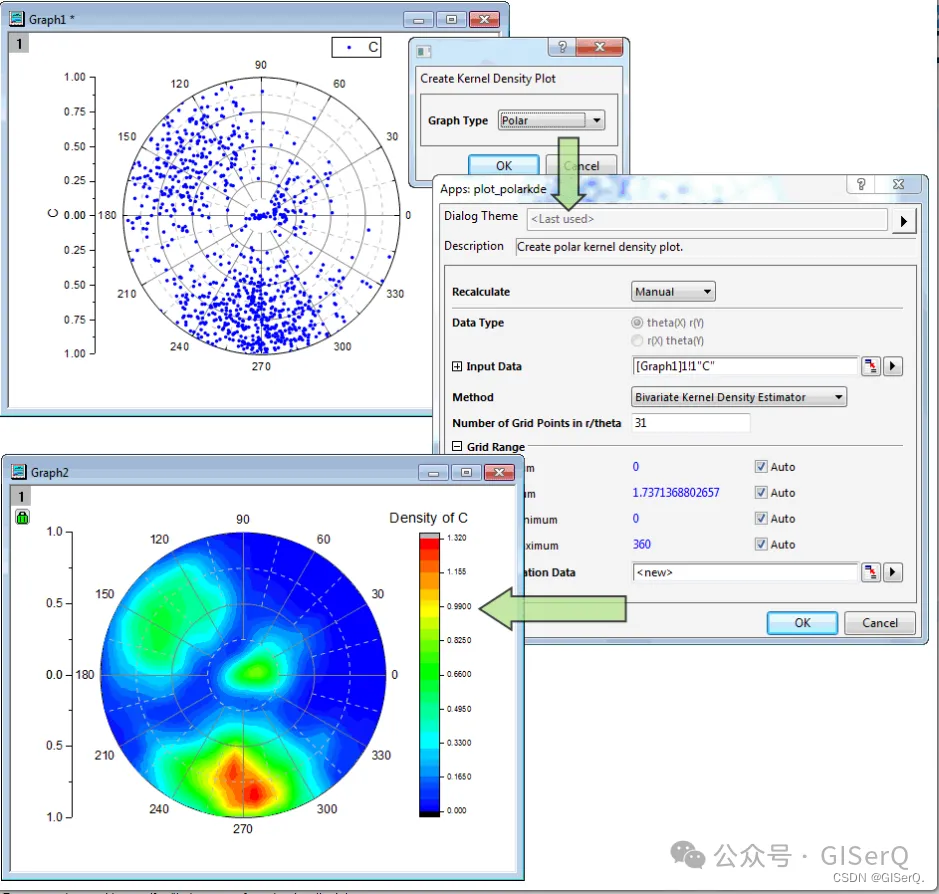
使用Origin绘制散点密度图
分享一下如何使用Origin绘制散点密度图。 1. 使用Origin绘制点密度图需要安装一个【Kernel Density Plot】插件,可以从官网下载,需要注册账号,填一些简单的个人信息。 网址: https://www.originlab.com/fileExchange/details.aspx?fid=408 如果不想注册账号,可以关注公众号 GISerQ 后在后台回复 Kerne
MATLAB中功率谱密度计算pwelch函数使用详解
MATLAB中功率谱密度计算pwelch函数使用详解 目录 前言 一、pwelch函数简介 二、pwelch函数参数说明 三、pxx = pwelch(x)示例 四、[pxx,f]=pwelch(x,window,noverlap,nfft,fs)示例 四、[pxx,f] = pwelch(x,window,noverlap,nfft,fs,freqrange,spectr