存算专题
StarRocks 存算分离成本优化最佳实践
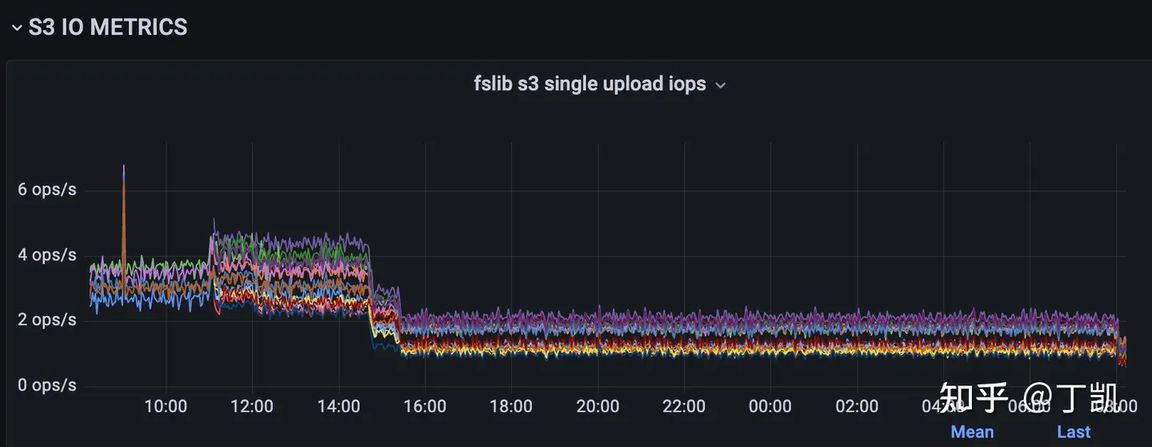
序言 StarRocks 存算分离借助对象存储来实现计算和存储能力分离,而存算分离版本 StarRocks 一般来说有以下三方面成本: 计算成本,也即机器使用成本,尤其是运行在公有云上时存储成本,该部分与对象存储上存储的数据量相关API 访问成本,这部分与访问对象存储各种 API 的频率相关 优化数据导入模式 在存算分离中,我们推荐积攒更大批量的数据,使用低频大批量写入来代替高频微批写

【学术前沿】基于非易失性存储器硬件特性的存算一体神经网络设计方法
【学术前沿】基于非易失性存储器硬件特性的存算一体神经网络设计方法 Lixia HAN, Peng HUANG, Yijiao WANG, Zheng ZHOU, Haozhang YANG, Yiyang CHEN, Xiaoyan LIU & Jinfeng KANG, Mitigating Methodology of Hardware Non-ideal Characteristics f
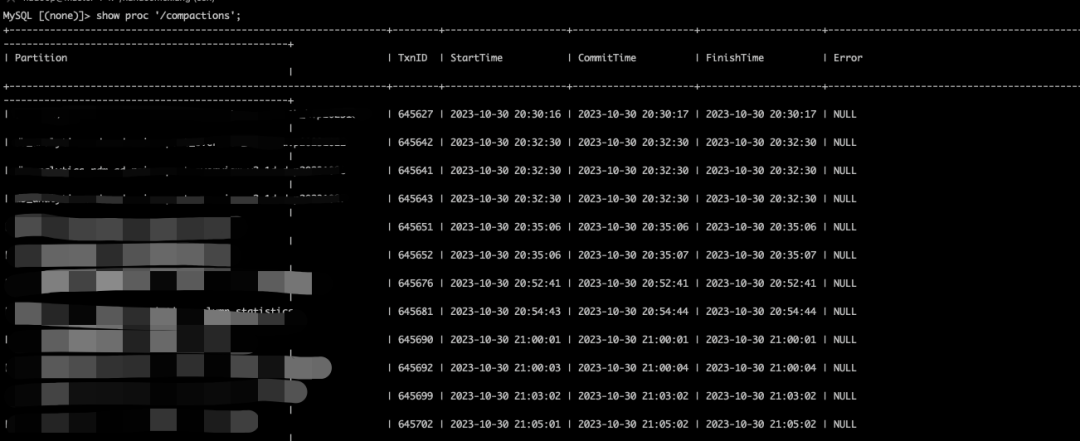
StarRocks 存算分离数据回收原理
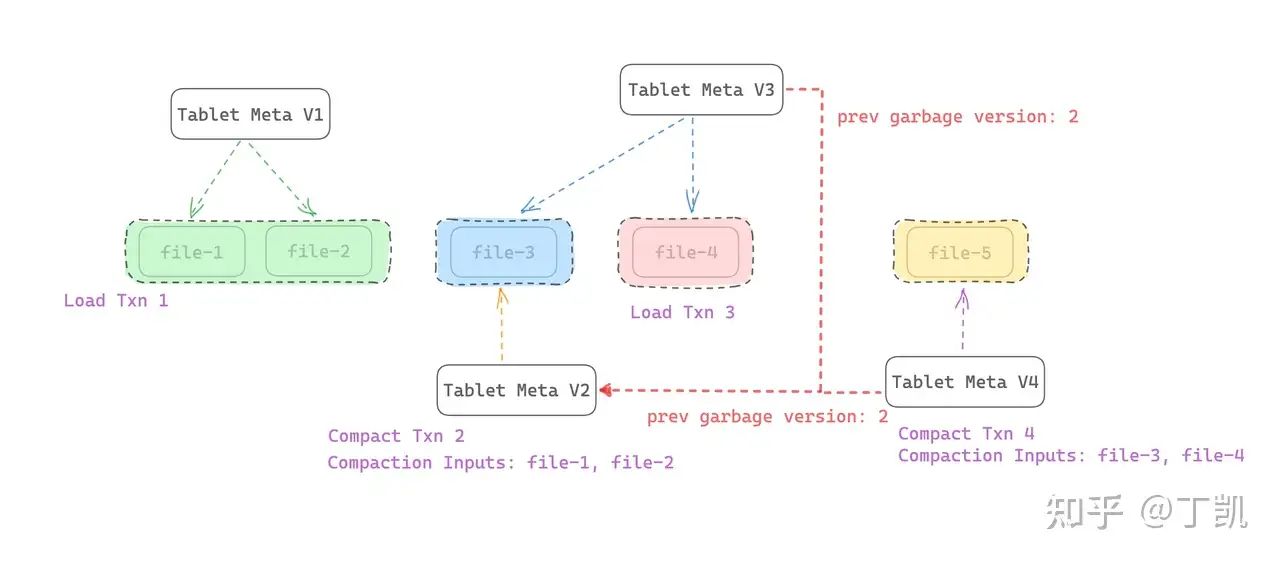
前言 StarRocks存算分离表中,垃圾回收是为了删除那些无用的历史版本数据,从而节约存储空间。考虑到对象存储按照存储容量收费,因此,节约存储空间对于降本增效尤为必要。 在系统运行过程中,有以下几种情况可能会需要删除对象存储上的数据: 用户手动执行了删除库、表、分区等命令,如执行了 drop table、drop database 以及 drop partition 等命令随着系统内 Co
存算架构优化:为大模型算力提升铺平道路
随着人工智能技术的飞速发展,大模型已经成为了推动各行各业进步的关键力量。从自然语言处理到图像识别,再到复杂的数据分析,大模型以其卓越的性能和广泛的应用前景,正逐渐成为AI领域的焦点。然而,大模型的高效运行离不开强大的算力支持,而存算架构的优化则是提升算力的关键所在。本文将探讨现有大模型对算力的需求以及RRAM架构优化如何为大模型的算力提升提供动力,为开发者提供一些实用的指导。 1、大模型涌现,C
兼顾降本与增效,我们对存算分离的设计与思考
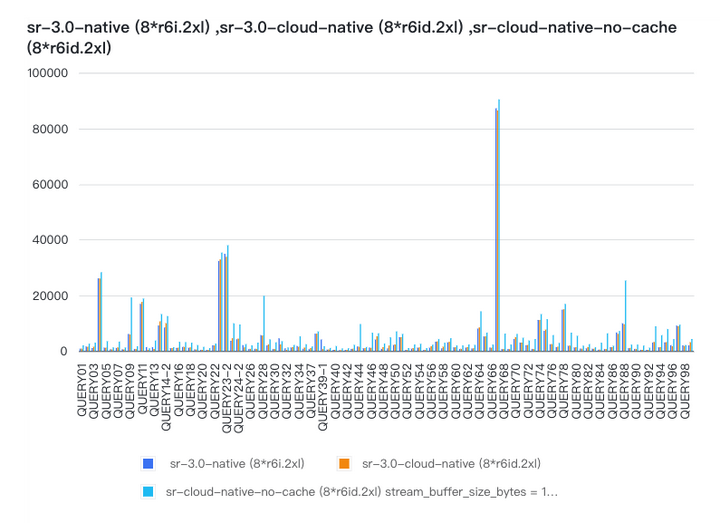
“降本增效”是最近企业常被提及的关键字,作为新时代企业发展的数据大脑,企业大数据团队需要持续探索如何在有限资源下创造更多价值。本文将以场景为"引",技术为"核",介绍如何基于 StarRocks 全新的存算分离架构实现数据分析的“降本”和“增效”。 降本 在冷热数据混合分析场景下,采用存算分离架构能够显著降低存储成本。 以日志分析场景为例,用户的 APP 和业务系统都会生成大量的埋点日志或应
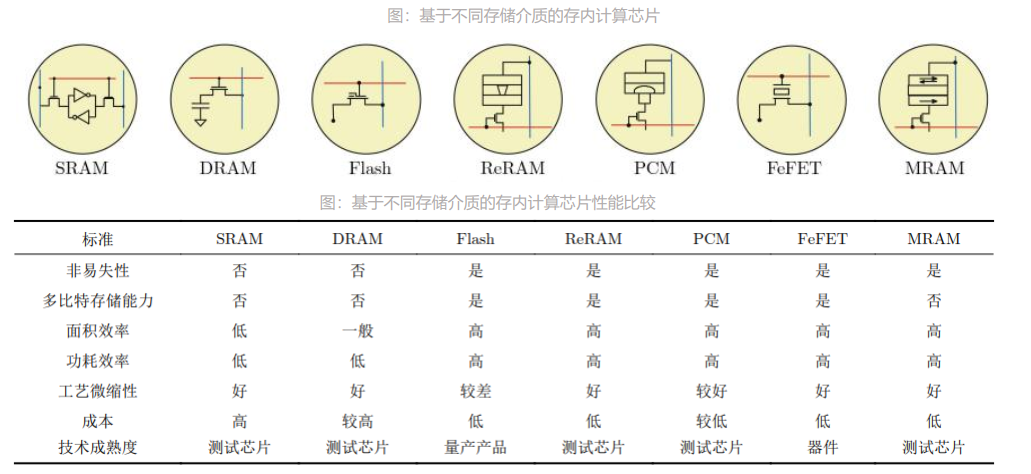
Sora爆火,多模态大模型背后的存算思考
近日,随着OpenAI推出Sora,人工智能从文本到文本、文本到图片的生成模式,进阶到文生视频。其文本到视频的模型能够生成长达一分钟的视频,在保持视觉质量的同时并严格遵循用户的提示,使得“扔进一本小说,生成一部电影”的想法成为现实。OpenAI将这一创新描述为构建“物理世界的通用模拟器”,这不仅是一项技术突破,也是人工智能领域探索的又一里程碑。 1、Sora展示 本页所
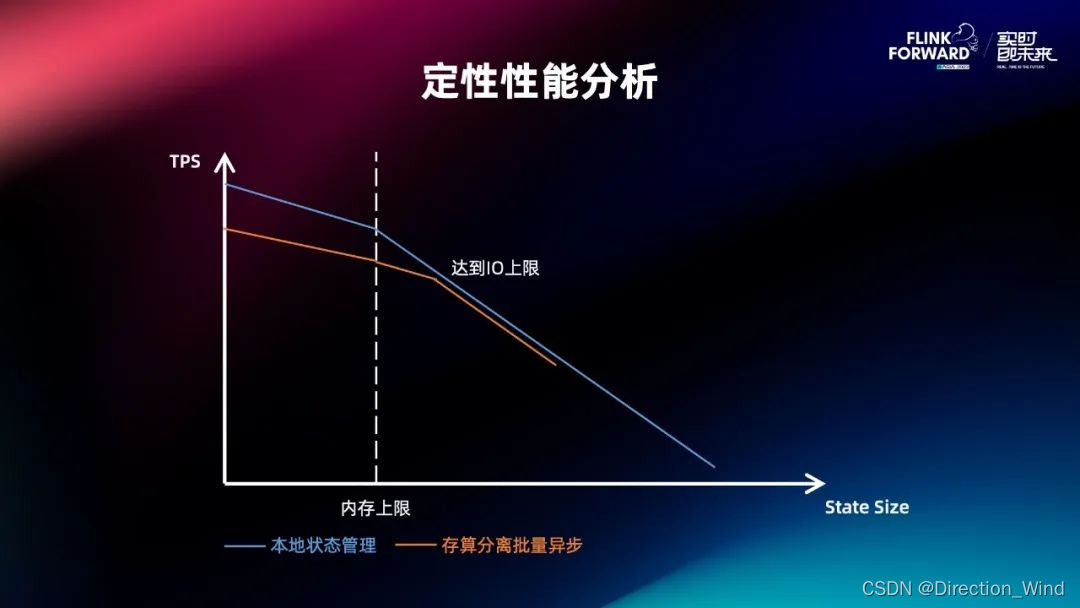
Flink 2.0 状态管理存算分离架构演进与分离改造实践
Flink 2.0 状态管理存算分离架构演进与分离改造实践 1 引言2 为什么状态对 Flink 如此重要2.1 状态的角色2.2 Flink状态管理的需求以及现存的问题 3 状态存储提升 —— 社区和商业版状态存储3.1 分布式快照架构升级3.2 面向云原生:高效弹性扩缩容3.3 Gemini:面向流计算场景的分层状态存储 4 状态管理存算分离架构 —— 架构演进和挑战4.1 云原生架构演

数据平台:湖仓一体、流批一体、存算分离的核心问题
一、为什么出现湖仓一体的技术架构 目前数据仓库存储的数据结构单一,只能存储结构化的数据,对于非结构化数据的存储需求,以及存储成本是数据仓库的主要问题,而非结构化数据存储在业务库,也造成数据不能相融和利用,为了解决非结构化数据的低成本的存储诞生了湖仓一体的技术架构。 湖仓一体的技术架构是指将数据湖(Data Lake)和数据仓库(Data Warehouse)结合在一起,实现对各
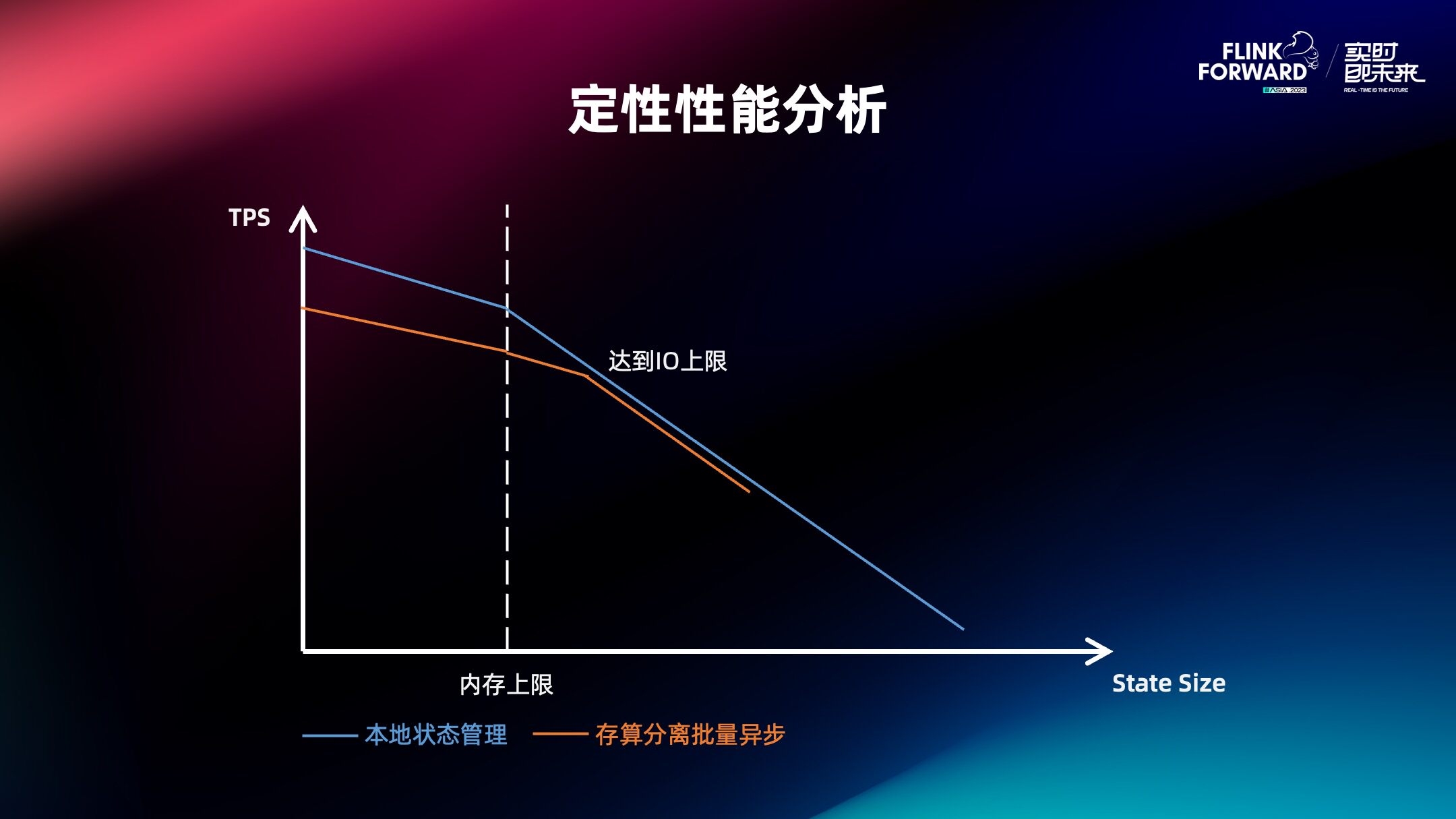
Flink 2.0 状态存算分离改造实践
本文整理自阿里云智能 Flink 存储引擎团队兰兆千在 FFA 2023 核心技术(一)中 的分享,内容关于 Flink 2.0 状态存算分离改造实践的研究,主要分为以下四部分: Flink 大状态管理痛点 阿里云自研状态存储后端 Gemini 的存算分离实践 存算分离的进一步探索 批量化存算分离适用场景 一、Flink 大状态管理痛点 1.1 Flink 状态管理 状态

存算一体:架构创新,打破算力极限
1 需求背景 在全球数据量呈指数级暴涨,算力相对于AI运算供不应求的现状下,存算一体技术主要解决了高算力带来的高能耗成本矛盾问题,有望实现降低一个数量级的单位算力能耗,在功耗敏感的百亿级AIoT设备上、高能耗的数据中心、自动驾驶等领域有望发挥其低功耗、低时延、高算力密度等优势。 在现有的成熟架构及工艺下,当前依靠制程技术进步,增加晶体管密度提升算力、降低功耗已逐步趋于物
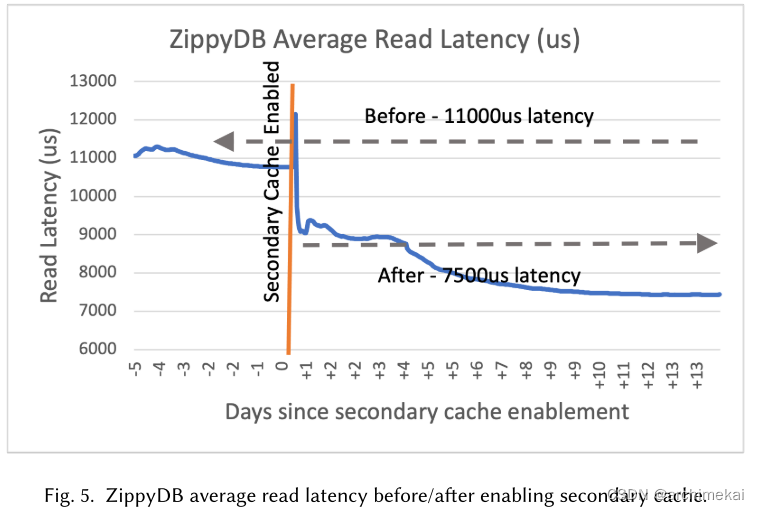
RocksDB是如何实现存算分离的
核心参考文献: Dong, S., P, S. S., Pan, S., Ananthabhotla, A., Ekambaram, D., Sharma, A., Dayal, S., Parikh, N. V., Jin, Y., Kim, A., Patil, S., Zhuang, J., Dunster, S., Mahajan, A., Chelluri, A., Datye, C.,
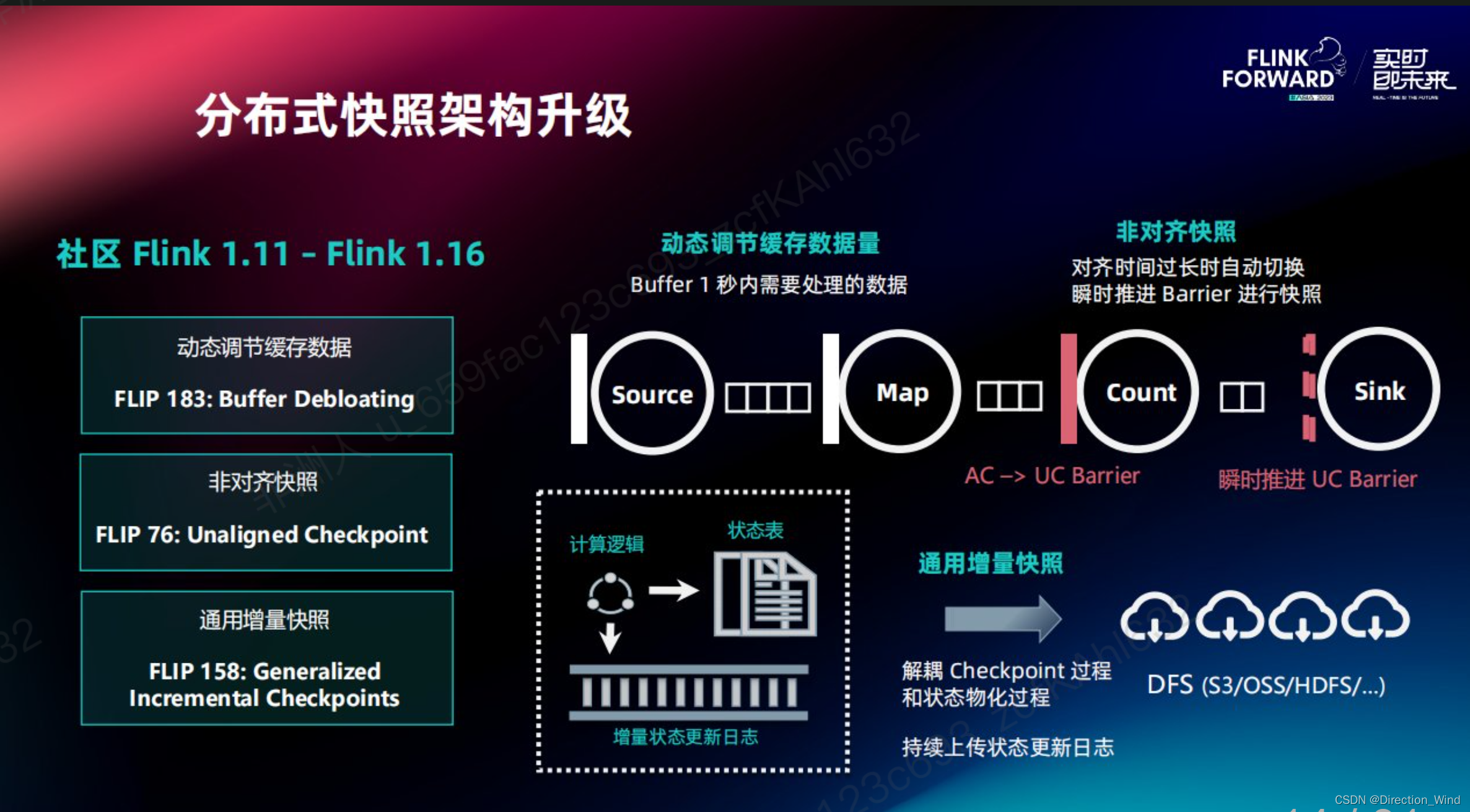
Flink 2.0 状态管理存算分离架构演进
Flink 2.0 状态管理存算分离架构演进 flink 现有状态访问线程模型 首先简单来说一下,flink2.0做存算分离,最最主要的一点是解决,大状态的问题,例如一个超过50T的物流数据,大状态恢复可能就要1天,所以才有存算分离这么一个设计初衷。 下面先来看一下 任务是怎么执行提交的,看一下state在整个流程里 处于一个什么位置 在当前容器化的常见用法,任
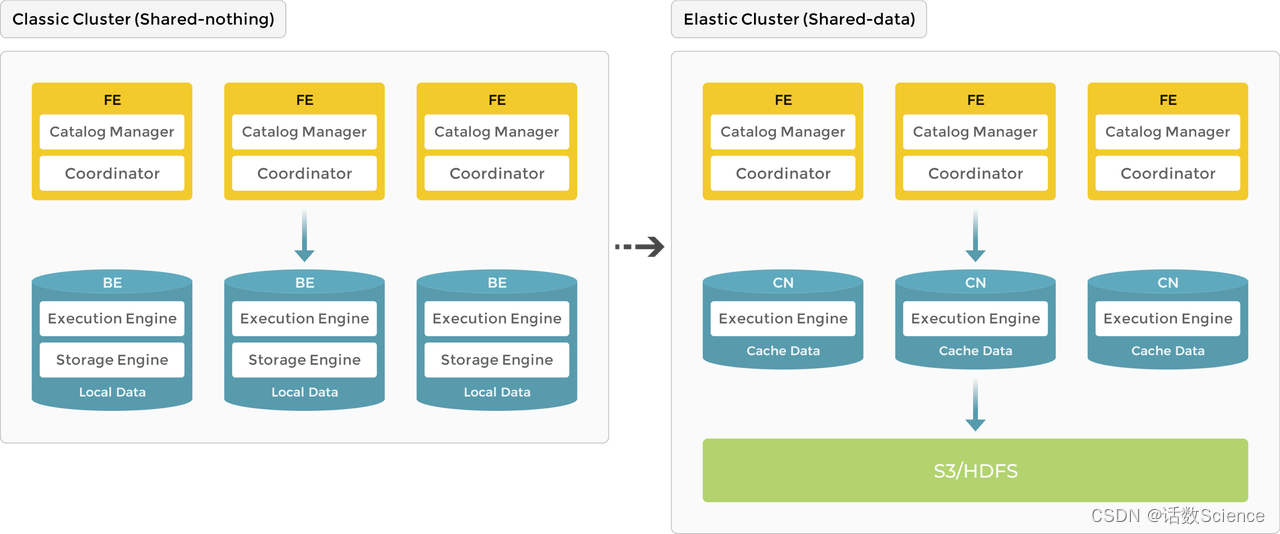
【大数据OLAP引擎】StartRocks存算分离
存算分离的原因 降低存储成本:同样的存储大小对象存储价格只有SSD的1/10,所以号称存储成本降低80%不是吹的。 存算一体到存算分离 存算一体 作为 MPP 数据库的典型代表,StarRocks 3.0 版本之前使用存算一体 (shared-nothing) 架构,BE 同时负责数据存储和计算,在查询时可以直接访问 BE 本地数据,进行本地计算,避免数据传输与拷贝,从而能够得到极速的
存算分离降本增效,StarRocks 助力聚水潭 SaaS 业务服务化升级
作者:聚水潭数据研发负责人 溪竹 聚水潭是中国领先的 SaaS 软件服务商,核心产品是电商 ERP,协同350余家电商平台,为商家提供综合的信息化、数字化解决方案。公司是偏线下商家侧的 toB 服务商,员工人数超过3500,线下网点超过100个,每天要承载大概2亿包裹量的 ERP 发货流程,产生的数据量超过10TP。 公司数据智能产品的定位是将数据融入到服务流程中,在 ERP 这个大的体系里,帮

StarRocks 存算分离最佳实践,让降本增效更简单
StarRocks 存算分离自版本 3.0.0 开放使用,已经历过多个大版本迭代,在众多客户生产环境中得到验证。但在用户使用过程中也反馈了一些问题,大多源自对新能力不够熟悉导致无法达到最佳效果。因而,本文提供 StarRocks 存算分离最佳实践,建议测试前仔细阅读,并按照最佳实践的指导来实施,以达到事半功倍的效果。 部署 用户在部署时需要在部署模式上二选一,存算一体或者存算分离,目前尚不支持在
数仓成本下降近一半,StarRocks 存算分离助力云览科技业务出海
成都云览科技有限公司倾力打造了凤凰浏览器,专注于为海外用户提供服务,公司致力于构建一个全球性的数字内容连接入口,为用户带来更为优质、高效、个性化的浏览体验。 作为数据驱动的高科技公司,从数据中挖掘价值一直是公司核心任务,公司以前选用了众多组件来提升内部大数据分析效率,如 Trino 作为即席查询的工具、用 ClickHouse 和 StarRocks 来加速报表业务查询,但经过长期实践,最终决定

极智芯 | 存算一体 弯道超车的希望
欢迎关注我的公众号 [极智视界],获取我的更多经验分享 大家好,我是极智视界,本文分享一下 存算一体 弯道超车的希望。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq "话说芯片架构,分久必合,合久必分”。这句话先留着,下面越说应该越有概念。先拿一张清华大学高滨老师的图开个场, 存算

存算一体芯片技术国际领航者,期待你的加入!
存算一体技术 相信很多嵌友都听说过 是不是也想进入此技术领域大显身手 正好 机会来了 存算一体芯片技术国际领航者—知存科技 等你来加入! 北京知存科技有限公司(以下简称“知存科技”)是国际领先的存算一体芯片公司,始创于2017年10月23日。2016年,创始团队完成国际第一块模拟存算一体深度学习芯片的研发设计,至今研发存算一体芯片已达9年。 知存科技的存算一体技术创新使用Flash存储器完成神