本文主要是介绍【大数据OLAP引擎】StartRocks存算分离,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
存算分离的原因
降低存储成本:同样的存储大小对象存储价格只有SSD的1/10,所以号称存储成本降低80%不是吹的。
存算一体到存算分离
存算一体
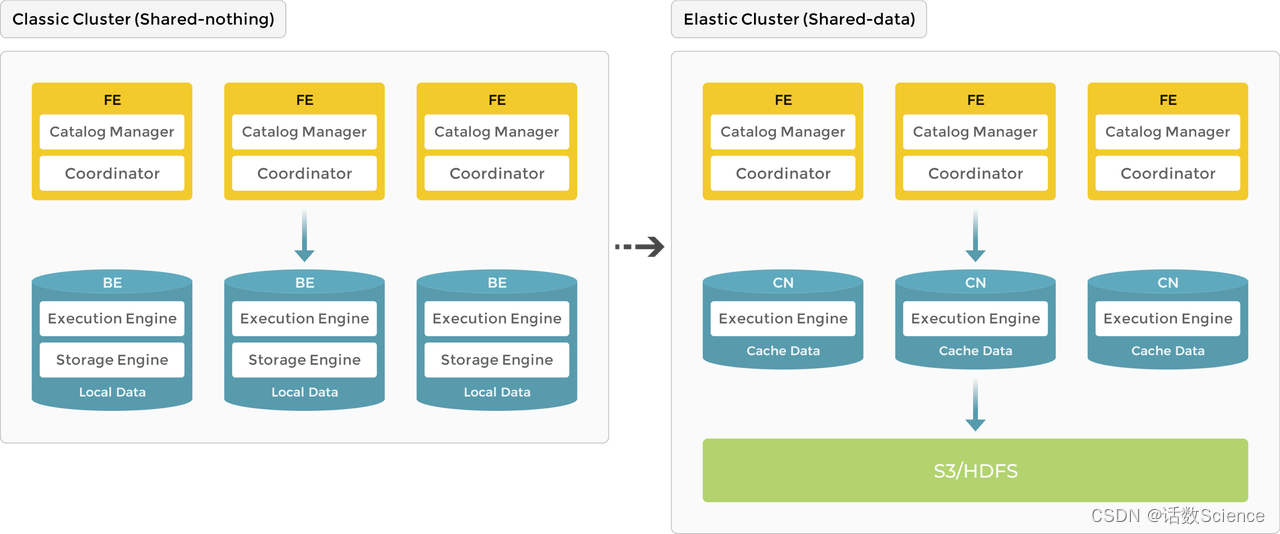
作为 MPP 数据库的典型代表,StarRocks 3.0 版本之前使用存算一体 (shared-nothing) 架构,BE 同时负责数据存储和计算,在查询时可以直接访问 BE 本地数据,进行本地计算,避免数据传输与拷贝,从而能够得到极速的查询分析性能。存算一体架构支持数据的多副本存储,提升了集群的高并发查询能力和数据可靠性。存算一体适用于追求极致查询性能的场景。
存算一体架构下,StarRocks 由 FE 和 BE 组成:FE 负责元数据管理和构建执行计划;BE 负责实际执行以及数据存储管理,BE 采用本地存储,通过多副本的机制保证高可用。
存算分离
StarRocks 存算分离技术在现有存算一体架构的基础上,将计算和存储进行解耦。在存算分离新架构中,数据持久化存储在更为可靠和廉价的远程对象存储(比如 S3)或 HDFS 上。CN 本地磁盘只用于缓存热数据来加速查询。在本地缓存命中的情况下,存算分离可以获得与存算一体架构相同的查询性能。存算分离架构下,用户可以动态增删计算节点,实现秒级的扩缩容。存算分离大大降低了数据存储成本和扩容成本,有助于实现资源隔离和计算资源的弹性伸缩。
与存算一体架构类似,存算分离版本拥有同样简洁的架构,整个系统依然只有 FE 和 CN 两种服务进程,用户唯一需要额外提供的是后端对象存储。
这篇关于【大数据OLAP引擎】StartRocks存算分离的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






