本文主要是介绍Flink 2.0 状态管理存算分离架构演进,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flink 2.0 状态管理存算分离架构演进
- flink 现有状态访问线程模型

首先简单来说一下,flink2.0做存算分离,最最主要的一点是解决,大状态的问题,例如一个超过50T的物流数据,大状态恢复可能就要1天,所以才有存算分离这么一个设计初衷。
下面先来看一下 任务是怎么执行提交的,看一下state在整个流程里 处于一个什么位置
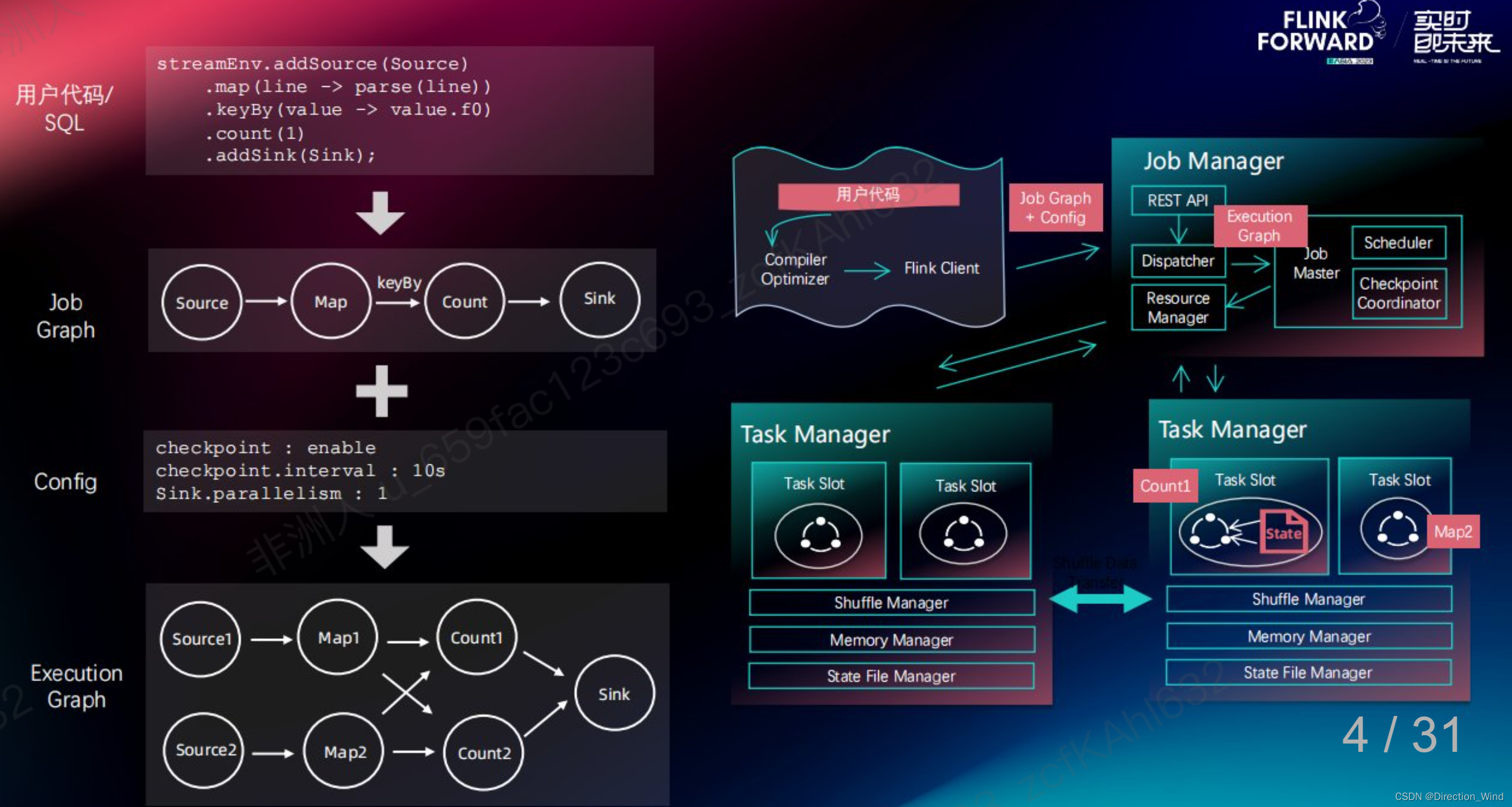


在当前容器化的常见用法,任务在启动起来以后,本地盘的大小已经固定了,现在如果用单pod跑,如果本地盘满了,基本只有扩并发一个办法。
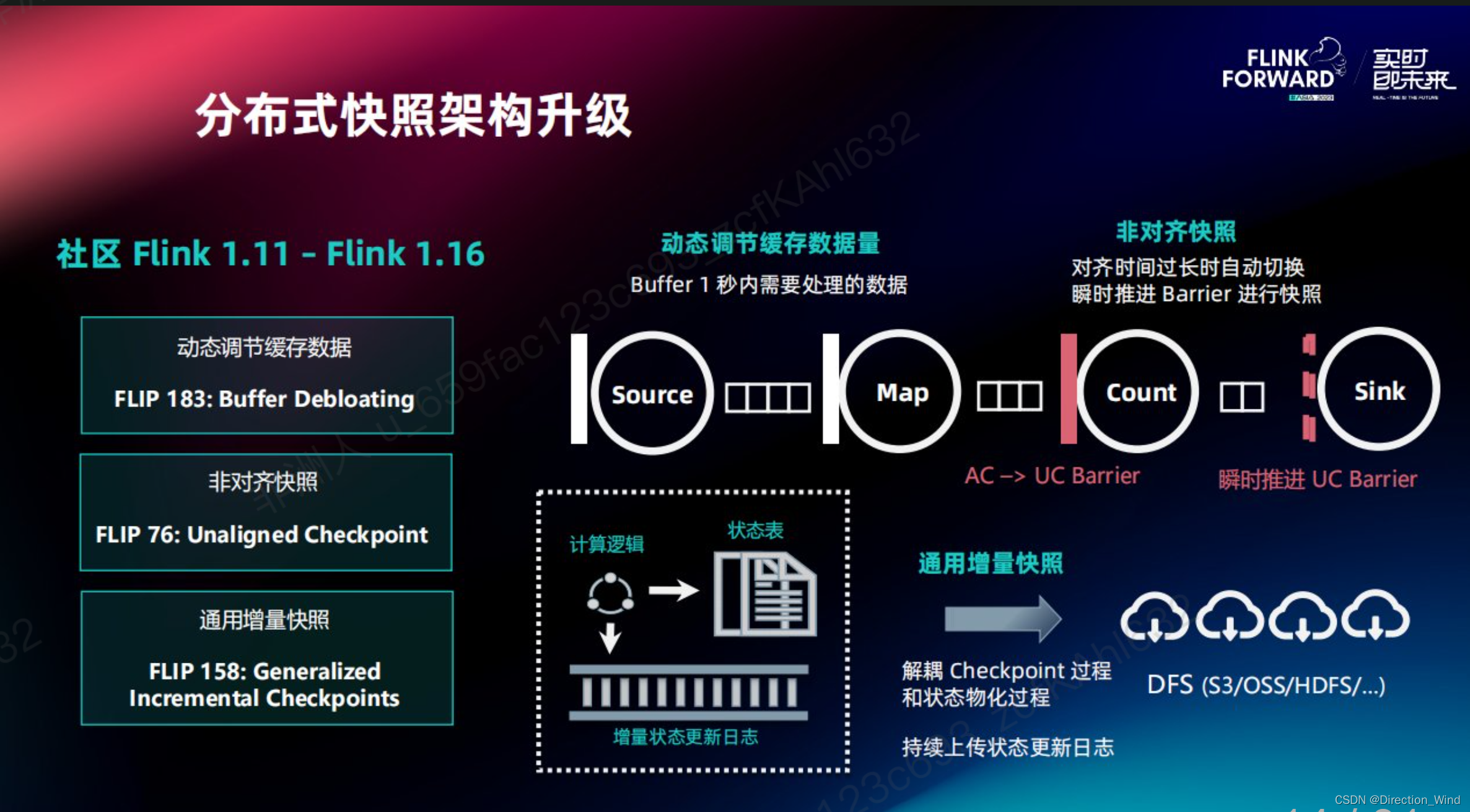
这篇关于Flink 2.0 状态管理存算分离架构演进的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






