本文主要是介绍极智芯 | 存算一体 弯道超车的希望,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文分享一下 存算一体 弯道超车的希望。
邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq
"话说芯片架构,分久必合,合久必分”。这句话先留着,下面越说应该越有概念。先拿一张清华大学高滨老师的图开个场,
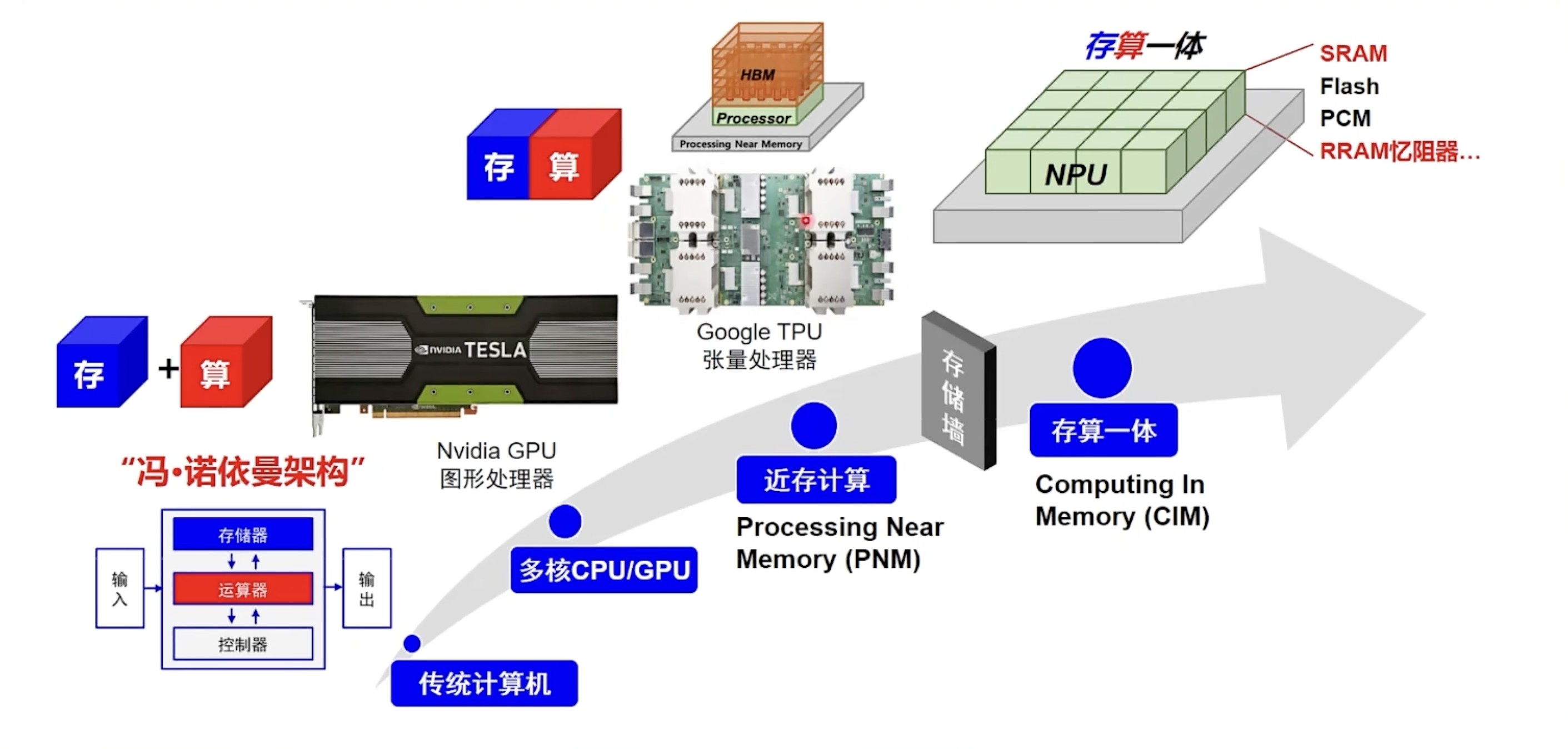
存算一体是什么呢,所谓的存算一体,用狭义的定义就是说存储和计算都同时在一个芯片上,用同一套电路来完成。而广义上的存算一体,还包括了 "近存计算",也就是尽可能地拉近运算器和存储器的距离。比较有代表性的就是 Google 的 TPU。
这一切要从冯诺依曼瓶颈说起,随着摩尔定律的推进,一颗晶粒上能够集成的晶体管的数量已经达到了空前的水平,特别是配合 "众核" 的堆叠,计算力不断升级,这个时候 "两堵墙" 越来越明显,一个是存储墙一个是功耗墙。
- 存储墙;=> 在冯诺依曼架构下,CPU 和内存之间 或者 GPU 和内存之间要频繁地进行数据读写,而内存的带宽远远跟不上 CPU 性能的提升。拿英伟达 H100 来说,H100 的 FP32 Tensor Core 算力是 1000 TFLOPS (而 FP8 Tensor Core 的算力甚至达到 4000 TFLOPS),但其显存带宽只有 3TB/s (已经是目前顶尖带宽,片外更低),这样导致算力和带宽之间差距巨大,表现往往是算的很快但传输很慢,真实能发挥出的算力有限,往往需要通过并行计算的 Pipeline 优化来将拷贝延迟隐藏掉;
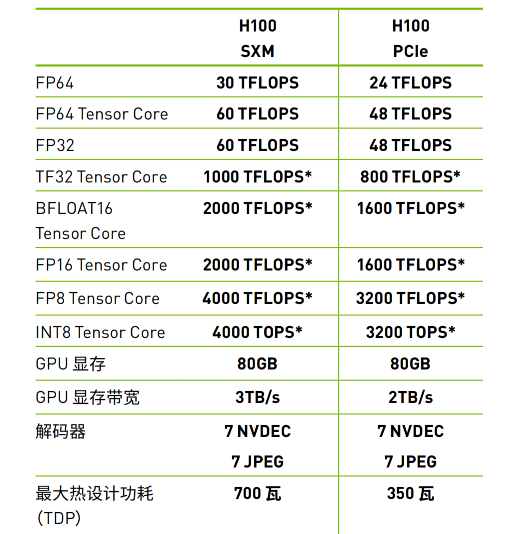
- 功耗墙;=> 在冯诺依曼架构下,超过 60% 以上的能耗被用来做了数据搬运,而非数据运算,这很明显非常不划算;
所以首先能想到的就是拉近 CPU/GPU 和内存之间的距离,或者说拉近计算单元和存储单元之间的距离。比如增加多级缓存来作为一个中间过渡地带,一层层把数据传递下去。但是这也不够用,那怎么办呢?想到的办法是通过先进封装来把内存尽可能靠近计算单元以缩短搬运路径,尽可能地增加带宽。然后通过 TSV 通孔把内存堆叠起来增加容量,这个呢就叫做 HBM 技术,而 H100 中 3TB/s 高带宽的带来者就是这个(HBM3),全称是 High Bandwith Memory。但是这些技术也都还是计算和存储分离的,这样永远也绕不开冯诺依曼瓶颈,说到底只有摆脱了冯诺依曼架构,才能真正的破除这个瓶颈,才能真正的破局。
这个时候存算一体就登场了,直接让存储器来计算数据,"没有任何的数据搬运" (这是相对的)。其实早在上个世纪 70 年代,存算一体的概念就已经诞生了,但是为什么这么先进的架构没有得到普及呢?一方面是没有大规模的应用需求,另一方面是芯片的制造工艺在当时还不太行。现在在这两个问题都得到了解决的前提下,还有个重要的推力是美国的芯片技术封锁,这让咱们对于芯片架构的 "破局",到了 "天时地利人和" 的阶段。
现在是大模型时代,随着 AI 对算力需求的增长,咱们的数据中心不可能是无止境扩大,这其中会有计算速度和成本的考量。深度学习 AI 中的计算基本都可以表达为 "乘、加" 计算,而存算一体芯片恰好擅长这个 (所以说到底,存算一体芯片应该是属于专用芯片,而非通用芯片,它更加适合于 AI 计算)。我们常见的 CPU、GPU 都是由晶体管来运行的,虽然说晶体管可以表示 0 和 1,但它无法存储 0 和 1。这应该比较好理解,一个晶体管的状态无非是 开 和 关,它无法维持在一个唯一的状态,所以要存储信息,就必须锁住维持一个状态。相比于 CPU、GPU 这类计算芯片,还有专用于存储的芯片,先来说说他们。比如 SRAM (缓存 / 静态随机存储器)、DRAM (内存 / 动态随机存储器),比如 Flash (固态硬盘,闪存,如手机、相机里的存储卡),他们的实现原理是不一样的。这里还会再引入两个概念:数字计算 和 模拟计算。
- SRAM => 通过至少 6 个晶体管,通过反相器来锁止一个状态,实现双稳态电路,由此来存储 0 和 1;==> 适合数字计算;
- DRAM => 利用一个电容和一个晶体管来存储数据,其中这个电容电荷的有无表示 0 和 1,而晶体管是用来控制开断的;==> 适合模拟计算;
- Flash => 利用一种带有浮置栅极的晶体管来存储 0 和 1,这个浮置栅极中可以通过量子遂穿效应来存储电荷;==> 适合模拟计算;
上面这三种常见的存储器只有 SRAM 是基于 CMOS 逻辑来构建的,全都是晶体管,而 DRAM 和 Flash 是利用电荷来存储信息的。从基本构造来讲,SRAM 是最适合做数字计算的,因为它本身就是 CMOS 逻辑,在已有的阵列上做改造,加入逻辑计算单元,就可以实现一定的运算能力,而相比之下 DRAM 和 Flash 就只能做模拟计算。这个 "而" 字转折,并不是说模拟计算不好,情况恰恰相反,AI 爆发之后它极有可能会挑大梁,这么说吧,咱们这里所说的 存算一体芯片 也是属于模拟计算。
到这里,可以明确一下 数字计算 和 模拟计算 的概念了,
- 数字计算;=> 是一种离散、非连续的形式,使用二进制数据进行计算。数字计算通常使用电子开关(如晶体管)来执行计算操作;==> 代表:目前主流的计算芯片、SRAM;
- 模拟计算;=> 使用连续、非离散的形式来进行计算。模拟计算可以模仿物理过程或连续量的变化,例如声音、光线或温度。模拟计算可以使用如电阻、电容和晶体管来实现;==> 存算一体芯片、RRAM (存算一体领域大名鼎鼎的忆阻器)、DRAM、Flash;
在 AI 时代,来分析这两种计算方式的利弊和前途。AI 是一个实时数据量非常庞大的应用场景,特别是大模型时代,神经网络的层数越来越深,模型规模也越来越大。这个时候用 CMOS 逻辑来操作的话,最显著的一个缺点就是能耗太大了。模拟计算的优势在于它的能耗很低,模拟计算你要说它难,它还真的不见得有多难。来看一个公式:V = IR,也就是 电压 = 电流 * 电阻,这就是个欧姆定律。那么模拟计算跟这个欧姆定律有什么关系呢,可以看到这个公式其实就是两个参数相乘,借助物理定律就自然而然地做了一次乘法,然后通过电路的串并联设计就可以把乘积累加起来,这样就完成了一次乘积累加运算,这样的电路设计如下,下面就完成了一次 3 x 3 的矩阵乘运算,是不是感觉豁然开朗,
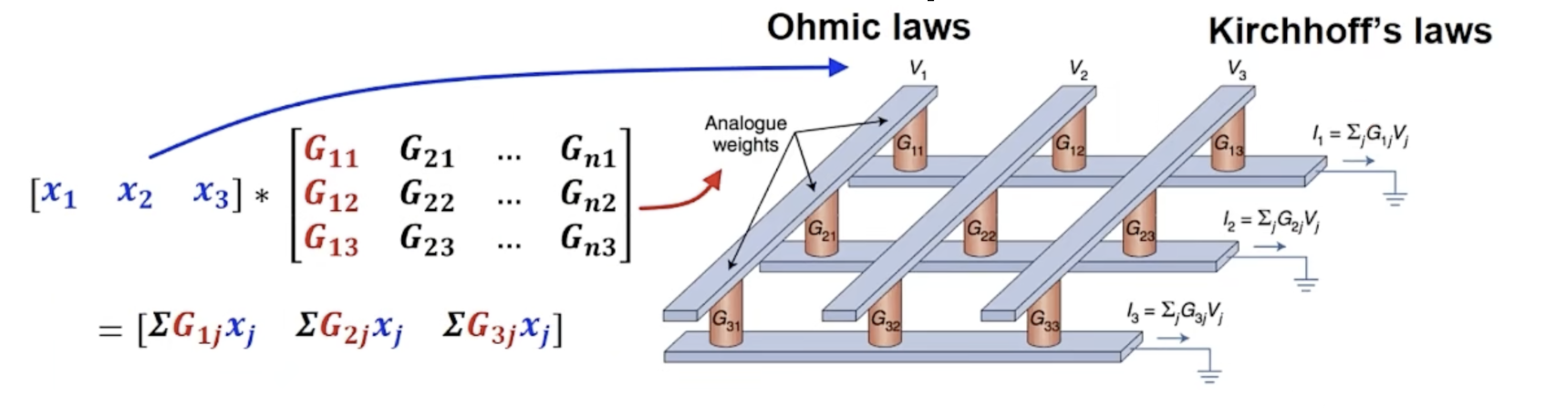
这个模拟计算,用到的晶体管数量是非常少的,因为它并不是二进制的。而且由于电流、电压、电阻的取值是可以连续的,所以它可以直接相乘相加。而反观在晶体管二进制中,因为只有 0 和 1 两个数字,那么要表达其他数字,就得是一连串 0 和 1,这也就意味着要用到一连串的晶体管和复杂的电路连接。这样看来模拟计算电路会 "轻量" 地多,但是模拟计算电路也并非十全十美,它容易引入噪声,因为它是直接利用的一个物理现象。也就是说模拟计算并没有数字计算那么的准确,它的计算精度跟数字计算相比,显然不占优势。但我们考虑在 AI 的场景中,对于数据精度的要求,其实并没有那么高。比如对于分类任务,分类得分 96.9% 和 96.6%,对于分类结果的影响并不大。 所以在 AI 的场景中,其实是可以容忍模拟计算误差的。
上面介绍的都还是存储器层面的存算一体,想象一下,将这种存算一体模拟计算应用到 AI 计算单元来替代掉 GPU,是不是前景十分客观呢。而未来的主流计算芯片架构,会不会变化成下面这样呢 (蜜汁潦草抽象图)...
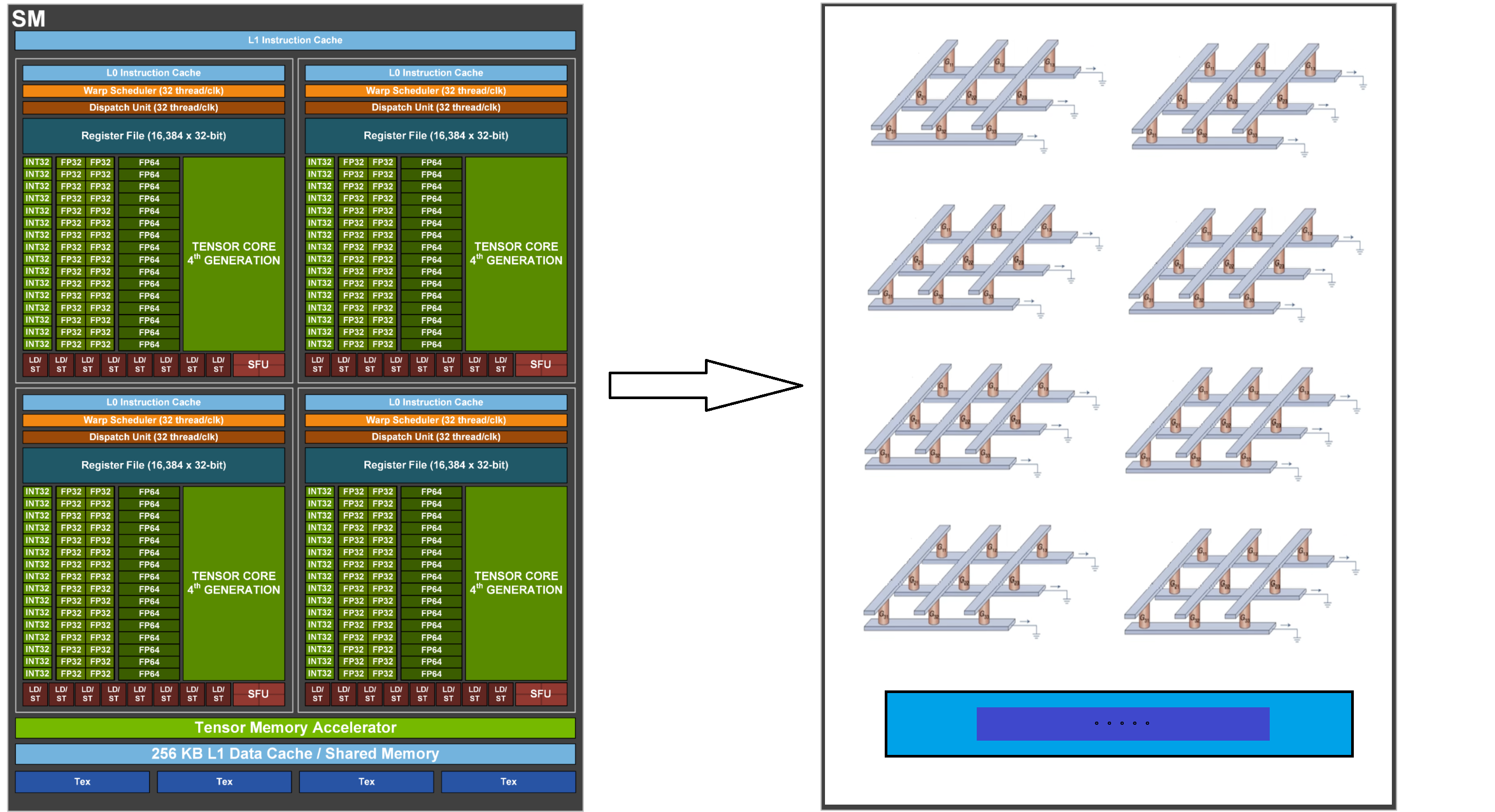
现在最鼎盛的、最繁荣的 AI 芯片都是基于晶体管的数字计算,这对于芯片的制程工艺要求特别高,而芯片的先进制造正是美国卡咱们脖子的地方。采用基于模拟计算的存算一体技术,可能才是咱们能够 "破局" 的突破点。这就像造车,在燃油车领域咱们拼不过人家,我们可以在新能源汽车领域实现弯道超车。
好了,以上分享了 存算一体 弯道超车的希望,希望我的分享能对你的学习有一点帮助。
【极智视界】
《极智芯 | 存算一体 弯道超车的希望》
畅享人工智能的科技魅力,让好玩的AI项目不难玩。邀请您加入我的知识星球,星球内我精心整备了大量好玩的AI项目,皆以工程源码形式开放使用,涵盖人脸、检测、分割、多模态、AIGC、自动驾驶、工业等。一定会对你学习有所帮助,也一定非常好玩,并持续更新更加有趣的项目。https://t.zsxq.com/0aiNxERDq

这篇关于极智芯 | 存算一体 弯道超车的希望的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








