大表专题

MySQL大表数据的分区与分库分表的实现
《MySQL大表数据的分区与分库分表的实现》数据库的分区和分库分表是两种常用的技术方案,本文主要介绍了MySQL大表数据的分区与分库分表的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有... 目录1. mysql大表数据的分区1.1 什么是分区?1.2 分区的类型1.3 分区的优点1.4 分

MySQL千万大表优化实践
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 前段时间笔者遇到一个复杂的慢查询,今天有空便进行了整理,以便日后回顾。举一个相似的业务场景的例子。以文章评论为例,查询20191201~20191231日期间发表的经济科技类别的文章,同时需要显示这些文章的热评数目 涉及到的四
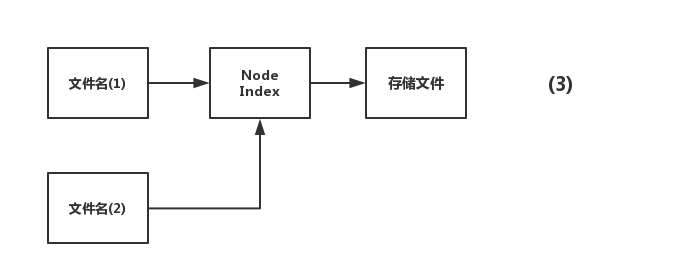
MySQL中快速删除大表
1,背景:某些情况下需要清理线上的大表。 如果设置了分区表的归档日志表,需要删除指定日期前的数据,直接truncate 或者drop table 可能造成所在服务器的IO吃满,进而影响线上业务。这里我们介绍采用硬链接的方式进行删除大表 2,解决方案 这里需要利用了linux中硬链接的知识,来进行快速删除。 所谓的硬链接,就是不止一个文件名指向node Index,有好几个文件名指向

MySQL 大表优化方案 【记录一下】
来源:https://segmentfault.com/a/1190000006158186 当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化。 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度,一般以整型值为主的表在 千万级以下,字符串为主的表在 五百万以下是没有太大问题的。而事实上很多时候MyS

Hive MapJoin(小表对大表)
摘要 MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率 使用 方法一: 在Hive0.11前,必须使用MAPJOIN来标记显示地启动该优化操作,由于其需要将小表加载进内存所以要注意小表的大小 SELEC
cassandra大表读写timeout的配置解决
程序异常如下:Caused by: com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout during write query at consistency LOCAL_ONE (1 replica were required but only 0 acknowledged the write
Hive大表join大表如何调优
目录 一、调优思路1、SQL优化1.1 大小表join1.2 大大表join 2、insert into替换union all3、排序order by换位sort by4、并行执行5、数据倾斜优化6、小文件优化 二、实战2.1 场景2.2 限制所需的字段,间接mapjoin2.2 解决异常值倾斜,如NULL加随机数打散2.3 扩容解决数据倾斜2.3.1 客户表扩大N倍2.3.2 部分倾斜ke
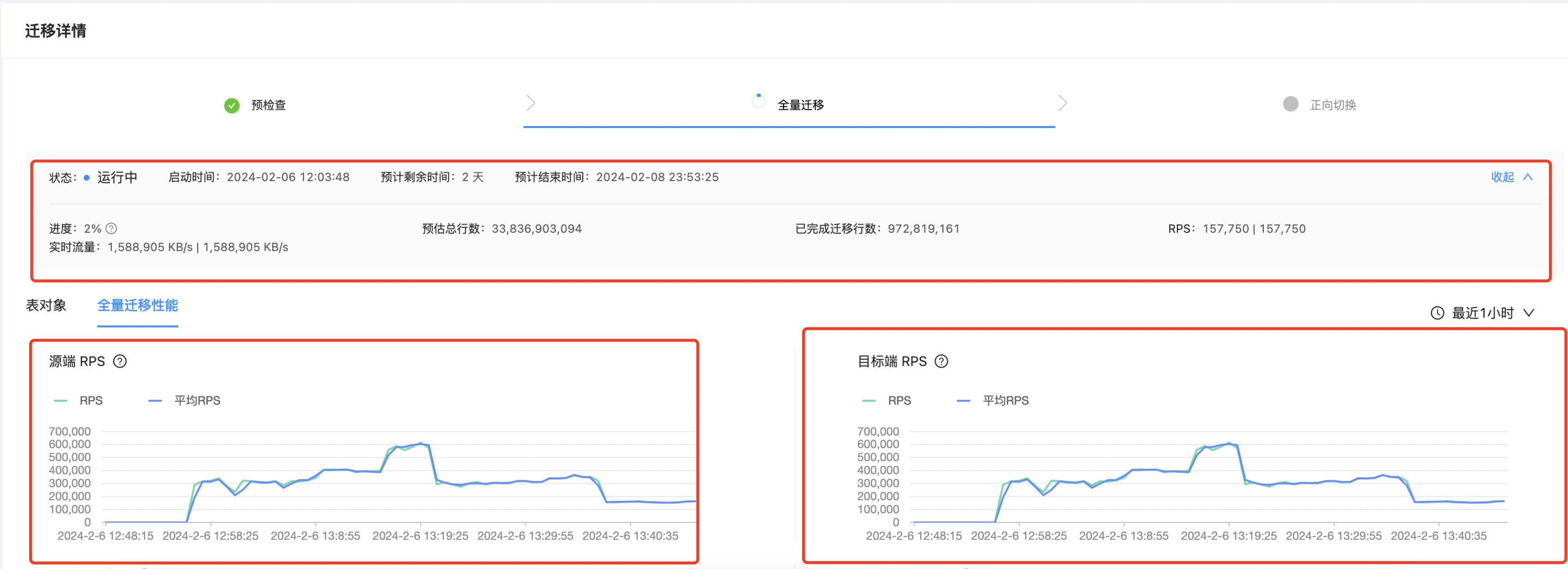
如何通过OMS加快大表迁移至OceanBase
OMS,是OceanBase官方推出的数据迁移工具,能够满足众多数据迁移场景的需求,现已成为众多用户进行数据迁移同步的重要工具。OMS不仅支持多种数据源,还具备全量迁移、增量同步、数据校验等功能,并能够对分表进行聚合操作,例如将MySQL的分库分表数据通过OMS聚合到OceanBase数据库的单表中。 如需深入了解OMS的完整功能,请访问OceanBase的OMS文档进行进一步了解。 今日,我
MySQL 对于千万级的大表的优化?
第一 优化你的sql和索引; 第二 加缓存,memcached,redis; 第三 以上都做了后,还是慢,就做主从复制或主主复制,读写分离,可以在应用层做,效率高,也可以用三方工具,第三方工具推荐360的atlas,其它的要么效率不高,要么没人维护; 第四 如果以上都做了还是慢,不要想着去做切分,mysql自带分区表,先试试这个,对你的应用是

MySQL两千万数据大表优化与解决方案
方案概述 方案一:优化现有mysql数据库。优点:不影响现有业务,源程序不需要修改代码,成本最低。缺点:有优化瓶颈,数据量过亿就玩完了。 方案二:升级数据库类型,换一种100%兼容mysql的数据库。优点:不影响现有业务,源程序不需要修改代码,你几乎不需要做任何操作就能提升数据库性能,缺点:多花钱 方案三:一步到位,大数据解决方案,更换newsql/nosql数据库。优点:扩展性强,成本低,没
mysql 大表凌晨定时删除数据
有几张表数据量非常大,一次维护量有点大(一个月有500多万条数据,并且还在往上涨), 于是想了个定时删除数据,每天凌晨执行,这样每天删除数据量就小, 循环删除,每次删除5000条数据,直到当天的数据删除完: 1,做删除过程: CREATE DEFINER=`root`@`%` PROCEDURE `S_delete_data2`() BEGIN #当次删除行

五年经验,还不懂小表驱动大表
小表驱动大表,也就是说用小表的数据集驱动大表的数据集。假如有order和user两张表,其中order表有10000条数据,而user表有100条数据。 这时如果想查一下,所有有效的用户下过的订单列表。可以使用in关键字实现: select * from orderwhere user_id in (select id from user where status=1) 也可以使用ex
工作随记:oracle重建一张1T数据量的大表
文章目录 一、删除测试表二、重命名旧表:三、验证:四、检查alert日志和昨天到今天的统计信息任务收集是否正常 一、删除测试表 #xshell登录用户hthis用户连接登录处理:sqlplus ht/"123456"sqlplus ht/"123456"@10.8.5.23/htdbdrop table rcd_record_data_26 purge;#创建新表的操

mysql中两千万大表做时间范围查询很慢,怎么解决
预备知识 1、一个表的数据量达到好几千万或者上亿时,加索引的效果没那么明显啦。性能之所以会变差,是因为维护索引的B+树结构层级变得更高了,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢。 少量数据可以考虑使用数据索引 2、InnoDB存储引擎最小储存单元是页,一页大小就是16k。 B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据
MySQL中的大表优化方案
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下: 1:限定数据的范围 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内 2: 读/写分离 经典的数据库拆分方案,主库负责写,从库负责读 3:垂直分区 根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以
聊聊 MySQL 的大表优化方案
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度,一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的。而事实上很多时候MySQL单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量: 字段 尽量使用TINYINT、
详记一次MySQL千万级大表优化过程!
详记一次MySQL千万级大表优化过程! 互联网编程 JavaGuide 今天 原文地址:https://www.zhihu.com/question/19719997/answer/549041957 问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡

遇到上亿(MySQL)大表的优化....
点击上方 好好学java ,选择 星标 公众号重磅资讯、干货,第一时间送达 今日推荐:Nginx 为什么快到根本停不下来? 个人原创100W+访问量博客:点击前往,查看更多 前段时间刚入职一家公司,就遇上这事! 背景 XX实例(一主一从)xxx告警中每天凌晨在报SLA报警,该报警的意思是存在一定的主从延迟(若在此时发生主从切换,需要长时间才可以完成切换,要追延迟来保证主从数据的一致性) XX

flink中如何把DB大表的配置数据加载到内存中对数据流进行增强处理
背景 在处理flink的数据流时,比如处理商品流时,一般我们从kafka中只拿到了商品id,此时我们需要把商品的其他配置信息比如品牌品类等也拿到,此时就需要关联上外部配置表来达到丰富数据流的目的,如果外部配置表很大,我们如何才能做到加载到内存中并完成丰富数据流的目的呢? 丰富数据流 有两种方式可以实现丰富数据流的效果,一种是把外部配置表所有数据加载到每个TaskManager的内存中,另一种
安全快速地删除 MySQL 大表数据并释放空间
一、需求 按业务逻辑删除大量表数据操作不卡库,不能影响正常业务操作操作不能造成 60 秒以上的复制延迟满足以上条件的前提下,尽快删除数据并释放所占空间 表结构如下: create table `space_visit_av` (`userid` bigint(20) not null comment '用户id',`avid` bigint(20) not null comm
安全快速地删除 MySQL 大表数据并释放空间
一、需求 按业务逻辑删除大量表数据操作不卡库,不能影响正常业务操作操作不能造成 60 秒以上的复制延迟满足以上条件的前提下,尽快删除数据并释放所占空间 表结构如下: create table `space_visit_av` (`userid` bigint(20) not null comment '用户id',`avid` bigint(20) not null comm
MySQL 大表数据归档解决办法
当数据库有一张表数据量很大,真正项目只用到一个月内的数据,因此把一个月前的旧数据定期归档。 解决方案如下: 1 - 创建一个新表,表结构和索引与旧表一模一样 create table table_archive like table_name; 2 - 新建存储过程,查询30天的数据并归档进新数据库,然后把30天前的旧数据从旧表里删除 delimiter $ create proc
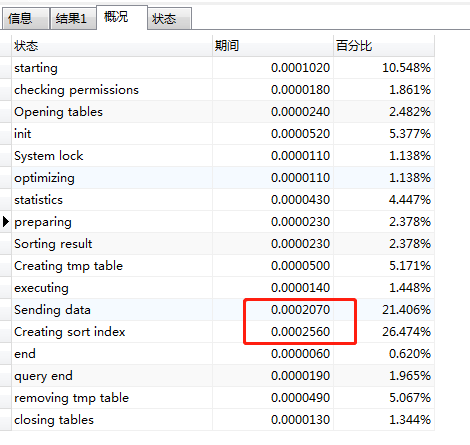
mysql join 400秒_三张关联表,大表;单次查询耗时400s,有group by order by 如何优化...
问题SQL: select p.person_id as personId, p.person_name as personName, p.native_place as nativePlace, ci.company_name as companyName, pp.seal_number as sealNumber, GROUP_CONCAT(pp.major) as major, pp.re

线上千万级大表排序该如何优化?
前言 前段时间应急群有客服反馈,会员管理功能无法按到店时间、到店次数、消费金额 进行排序。经过排查发现是Sql执行效率低,并且索引效率低下。遇到这样的情况我们该如何处理呢?今天我们聊一聊Mysql大表查询优化。 应急问题 商户反馈会员管理功能无法按到店时间、到店次数、消费金额 进行排序,一直转圈圈或转完无变化,商户要以此数据来做活动,比较着急,请尽快处理,谢谢。 线上数据量