本文主要是介绍线上千万级大表排序该如何优化?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前言
前段时间应急群有客服反馈,会员管理功能无法按到店时间、到店次数、消费金额 进行排序。经过排查发现是Sql执行效率低,并且索引效率低下。遇到这样的情况我们该如何处理呢?今天我们聊一聊Mysql大表查询优化。
应急问题
商户反馈会员管理功能无法按到店时间、到店次数、消费金额 进行排序,一直转圈圈或转完无变化,商户要以此数据来做活动,比较着急,请尽快处理,谢谢。
线上数据量
merchant_member_info 7000W条数据。
member_info 3000W。
不要问我为什么不分表,改动太大,无能为力。
问题SQL如下
SELECTmui.id,mui.merchant_id,mui.member_id,DATE_FORMAT(mui.recently_consume_time,'%Y%m%d%H%i%s') recently_consume_time,IFNULL(mui.total_consume_num, 0) total_consume_num,IFNULL(mui.total_consume_amount, 0) total_consume_amount,(CASEWHEN u.nick_name IS NULL THEN'会员'WHEN u.nick_name = '' THEN'会员'ELSEu.nick_nameEND) AS 'nickname',u.sex,u.head_image_url,u.province,u.city,u.country
FROMmerchant_member_info mui
LEFT JOIN member_info u ON mui.member_id = u.id
WHERE1 = 1
AND mui.merchant_id = '商户编号'
ORDER BYmui.recently_consume_time DESC / ASC
LIMIT 0,10
出现的原因
经过验证可以按照“到店时间”进行降序排序,但是无法按照升序进行排序主要是查询太慢了。主要原因是:虽然该查询使用建立了recently_consume_time索引,但是索引效率低下,需要查询整个索引树,导致查询时间过长。
DESC 查询大概需要4s,ASC 查询太慢耗时未知。
为什么降序排序快和而升序慢呢?
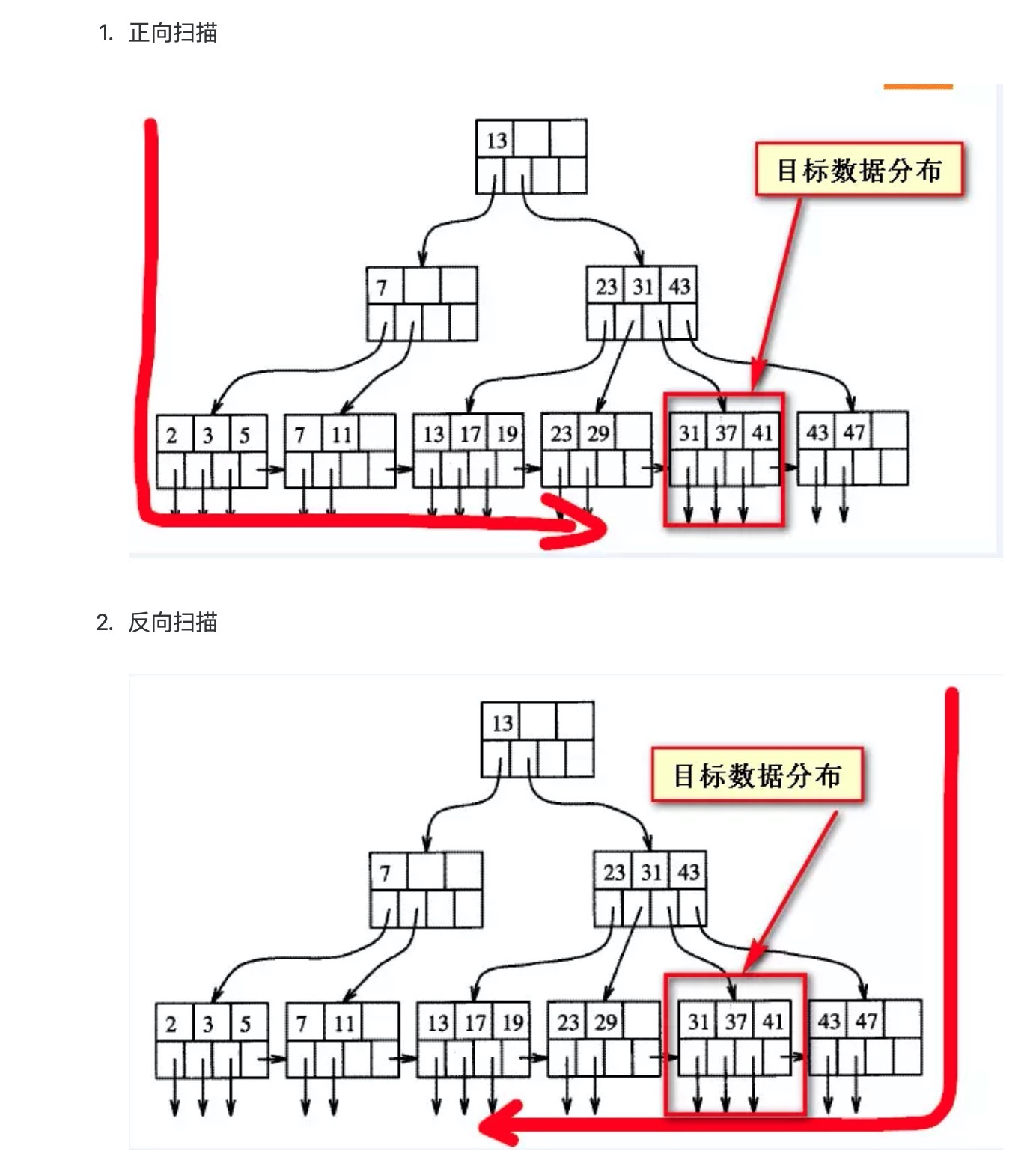
因为是对时间建立了索引,最近的时间一定在最后面,升序查询,需要查询更多的数据,才能过滤出相应的结果,所以慢。
解决方案
目前生产库的索引
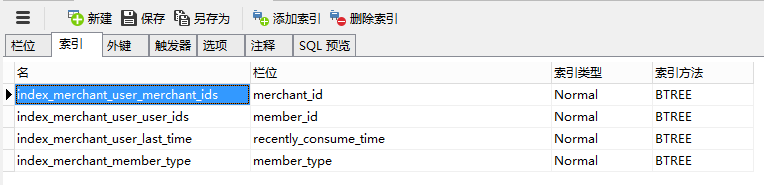
调整索引
需要删除index_merchant_user_last_time索引,同时将index_merchant_user_merchant_ids单例索引,变为 merchant_id,recently_consume_time组合索引。
调整结果(准生产)

调整前后结果对比(准生产)
测试数据
merchant_member_info 有902606条记录。
member_info 表有775条记录。
SQL执行效率
优化前

优化后

type由index -> ref
ref由 null -> const
| TOP | 优化前 | 优化后 |
|---|---|---|
| 到店时间-降序 | 0.274s | 0.003s |
| 到店时间-升序 | 11.245s | 0.003s |
调整索引需要执行的SQL
执行的注意事项:
由于表中的数据量太大,请在晚上进行执行,并且需要分开执行。 # 删除近期消费时间索引
ALTER TABLE merchant_member_info DROP INDEX index_merchant_user_last_time;# 删除商户编号索引
ALTER TABLE merchant_member_info DROP INDEX index_merchant_user_merchant_ids;# 建立商户编号和近期消费时间组合索引
ALTER TABLE merchant_member_info ADD INDEX idx_merchant_id_recently_time (`merchant_id`,`recently_consume_time`);
经询问,重建索引花了30分钟。
最终的分页查询优化
上面的sql虽然经过调整索引,虽然能达到较高的执行效率,但是随着分页数据的不断增加,性能会急剧下降。
| 分页数据 | 查询时间 | 优化后 |
|---|---|---|
| limit 0,10 | 0.003s | 0.002s |
| limit 10,10 | 0.005s | 0.002s |
| limit 100,10 | 0.009s | 0.002s |
| limit 1000,10 | 0.044s | 0.004s |
| limit 9000,10 | 0.247s | 0.016s |
最终的sql
优化思路:先走覆盖索引定位到,需要的数据行的主键值,然后INNER JOIN 回原表,取到其他数据。
SELECTmui.id,mui.merchant_id,mui.member_id,DATE_FORMAT(mui.recently_consume_time,'%Y%m%d%H%i%s') recently_consume_time,IFNULL(mui.total_consume_num, 0) total_consume_num,IFNULL(mui.total_consume_amount, 0) total_consume_amount,(CASEWHEN u.nick_name IS NULL THEN'会员'WHEN u.nick_name = '' THEN'会员'ELSEu.nick_nameEND) AS 'nickname',u.sex,u.head_image_url,u.province,u.city,u.country
FROMmerchant_member_info mui
INNER JOIN (SELECTidFROMmerchant_member_infoWHEREmerchant_id = '商户ID'ORDER BYrecently_consume_time DESCLIMIT 9000,10
) AS tmp ON tmp.id = mui.id
LEFT JOIN member_info u ON mui.member_id = u.id
结尾
如果觉得对你有帮助,可以多多评论,多多点赞哦,也可以到我的主页看看,说不定有你喜欢的文章,也可以随手点个关注哦,谢谢。
我是不一样的科技宅,每天进步一点点,体验不一样的生活。我们下期见!

这篇关于线上千万级大表排序该如何优化?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






