千万级专题

Mysql 千万级数据量插入和查询应该怎么优化
关于插入: 宏观上:建二个表,其中一个表不建主键,不键索引。只记录,到了晚上,在把这个表的记录导入 有主键有索引的表里。方法的目的,二表,一表为插入最优化,另一表为查询最优化。 微观上:以下是涉及到插入表格的查询的5种改进方法: 一、使用LOAD DATA INFILE从文本下载数据这将比使用插入语句快20倍。 二、使用多个值表的 INSERT 语句 ,可以大大缩减客户端与
淘宝从几百到千万级并发的十四次架构演进之路(推荐收藏参考)
淘宝从几百到千万级并发的十四次架构演进之路(推荐收藏参考) 牛旦教育IT课堂 2019-06-19 11:53:00 作者:huashiou 原文地址:https://segmentfault.com/a/1190000018626163 1、概述 本文以淘宝作为例子,介绍从一百个并发到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让大家对架构的演进

千万级数据,无索引情况下,字符串模糊查询like instr position locate对比
千万级数据,无索引情况下,字符串模糊查询like instr position locate对比

千万级数据快速查询,sql相同的情况下,PHP和python获取有效数据速度比较
1、同样的sql查询,PHP请求时间比python稍微短。 2、PHP的返回数据比python要大。 索引已经尽可能利用,但是查询速度还是较慢。数据量级较高,其中牵扯量级等值的多表联合查询。 优化方案:根据主表的索引优势,快速定位主表满足条件的id数据集合。作为临时表,极大缩减联合查询行数,左查询。 thinkPHP5临时表查询: $aids = Db::name('ax')->fi

java实现删除redis千万级数据的大key
redis删除千万级大key问题处理-20171017 1、问题描述 redis数据存储了几千万的数据的key,使用del无法删除,占用大量redis内存,且会导致redis切机 2、问题分析 redis使用del每秒可清理100w~几百万个值,假如是几千万的大数据量的key时,会导致redis阻塞10秒以上,sentinel会检测redis状态判断redis故障,而进行切换,应

Elasticsearch向量检索(KNN)千万级耗时长问题分析与优化方案
最终效果 本文分享,ES千万级向量检索耗时分钟级的慢查询分析方法,并分享优化方案。通过借助内存加速,把查询延迟从分钟级降低到毫秒级别。 方案缺点是对服务器内存有比较大的依赖! 主要问题:剔除knn插件,此插件在做ANN检索时,构建查询语句耗时长。 1.背景 1.1 资源背景 es.8.8版本 2个es节点 ; 堆内存31g; 服务器内存资源充足(100+); HDD磁盘 该优化是在

爆款来袭!AI萌娃T台秀,单条视频千万级播放量,制作方法竟如此简单!
大家好,我是小奇,一名热衷于分享AI副业项目的普通博主。不管你是AI小白还是老手,我都能帮你轻松上手,用AI技术赚钱。想多赚点?跟我来,一起探索AI副业,实现财务自由!记得关注我哦! 最近在Tiktok上刷到小宝宝走T台的视频,一个个穿着花哨的衣裳,摇摇晃晃地走着,那模样简直能把人心都萌化了,看了不点赞都难! 这些视频虽然短,但播放量惊人,动不动就是几千万,不仅人气爆棚,还能通过平台的奖励计划

批量生产千万级数据 推送到kafka代码
1、批量规则生成代码 1、随机IP生成代码 2、指定时间范围内随机日期生成代码 3、随机中文名生成代码。 package com.wfg.flink.connector.utils;import java.time.LocalDate;import java.time.LocalDateTime;import java.time.LocalTime;import java.util.Ar
MySQL千万级数据从190秒优化到1秒全过程
文章目录 一、性能问题的分析1. 问题背景2. 查询分析 二、优化思路1. 添加索引2. 分区表3. 优化查询4. 查询缓存 三、具体优化步骤1. 添加复合索引2. 对表进行分区3. 启用查询缓存4. 优化查询 四、总结 🎉欢迎来到Java学习路线专栏~探索Java中的静态变量与实例变量 ☆* o(≧▽≦)o *☆嗨~我是IT·陈寒🍹✨博客主页:IT·陈寒的博客�
MySQL 的 count(*) 的优化,获取千万级数据表的总行数
Java芋道源码 2019-04-12 21:44:23 一、前言二、关于count的优化三、使用explain获取行数1、关于explain2、关于返回值 一、前言 这个问题是今天朋友提出来的,关于查询一个1200w的数据表的总行数,用count(*)的速度一直提不上去。找了很多优化方案,最后另辟蹊径,选择了用explain来获取总行数。 二、关于count的优化 网上关于coun
Java导出千万级大数据到CSV文件
在实际应用中,我们经常需要从数据库中导出大量数据到CSV文件。如果数据量很大,一次性加载所有数据可能会导致内存溢出或者性能问题。为了解决这个问题,我们可以使用流式查询的方式逐行读取数据库,并将数据写入CSV文件,从而减少内存占用并提高性能。本文将介绍如何使用Java实现这一功能,并给出详细的代码示例。 准备工作 在开始之前,我们需要做一些准备工作: 确保你已经设置好了Java开发环境,并且具
MySQL 对于千万级的大表的优化?
第一 优化你的sql和索引; 第二 加缓存,memcached,redis; 第三 以上都做了后,还是慢,就做主从复制或主主复制,读写分离,可以在应用层做,效率高,也可以用三方工具,第三方工具推荐360的atlas,其它的要么效率不高,要么没人维护; 第四 如果以上都做了还是慢,不要想着去做切分,mysql自带分区表,先试试这个,对你的应用是

MySQL的count(*)的优化,获取千万级数据表的总行数
一、前言 这个问题是今天朋友提出来的,关于查询一个1200w的数据表的总行数,用count(*)的速度一直提不上去。找了很多优化方案,最后另辟蹊径,选择了用explain来获取总行数。 二、关于count的优化 网上关于count()优化的有很多。博主这边的思路就是没索引的就建立索引关系,然后使用count(1)或者count(*)来提升速度。这两个函数默认使用的是数据表中最短的那个索引字段。
mysql四:30多条mysql数据库优化方法,千万级数据库记录查询轻松解决
转载地址:http://www.ihref.com/read-16422.html 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描, Sql 代码 : select id from t where num
mysql千万级测试1亿数据的分页分析测试
本文为本人最近利用几个小时才分析总结出的原创文章,希望大家转载,但是要注明出处 http://blog.sina.com.cn/s/blog_438308750100im0e.html 有什么问题可以互相讨论:yubaojian0616@163.com 于堡舰 上一篇文章我们测试一些orderby查询和分页查询的一些基准性能,现在我们来分析一下条件索引查询的结果集的测试 现在我们继续

基于大规模边缘计算的千万级聊天室技术实践
当前直播成为一种流行趋势,带货直播,网红带货,明星在线演唱会等,进一步使得直播聊天室变成了一个当前必备的能力,面向大型,超大型的直播场景,技术上也在不断的进行迭代更新。 大规模边缘聊天室如何工作? 大型边缘聊天室的工作过程非常的简单,用户 UserA 加入聊天室 X,用户 UserB 也加入聊天室 X,此时用户 UserA 向聊天室发送消息 hello,服务端接收到该消息后,会

千万级SQL Server数据库表分区的实现
千万级SQL Server数据库表分区的实现 2012-12-04 14:48 by swarb, ... 阅读, ... 评论, 收藏, 编辑 一般在千万级的数据压力下,分区是一种比较好的提升性能方法。本文将介绍SQL Server数据库表分区的实现。 AD: 最近使用SQL SERVER一个的缓存,数据量一天100w的速度增长,同时接受客户查询,速度由于数据量越来越大越来越

千万级数据处理解决方案(收集)
http://blog.csdn.net/huang7914/article/details/2316160 http://www.cnblogs.com/ghd258/articles/260748.html
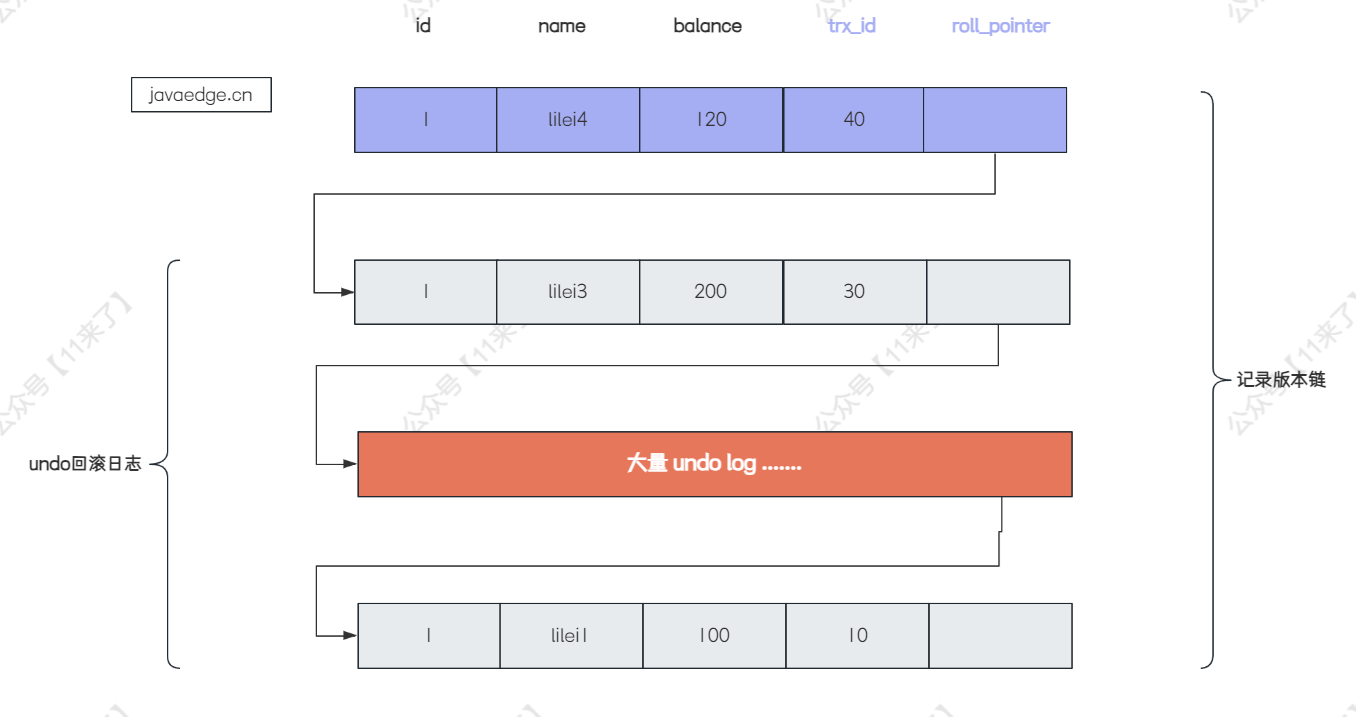
【MySQL进阶之路】千万级数据删除导致的慢查询SQL调优实战
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送! 在我后台回复 「资料」 可领取编程高频电子书! 在我后台回复「面试」可领取硬核面试笔记! 文章导读地址:点击查看文章导读! 感谢你的关注! 千万级数据删除导致的慢查询SQL调优实战 先说一下案例背景: 刚开始,线上系统收到了大量的慢查询告警,检查之后,发现慢查询的都是一些比较简单的 SQ
MySql千万级limit优化方案
经过实践,总结以下比较好的limit分页优化方案 1. 模仿百度、谷歌方案(前端业务控制) 类似于分段。我们给每次只能翻100页、超过一百页的需要重新加载后面的100页。这样就解决了每次加载数量数据大 速度慢的问题了 2. 记录每次取出的最大id, 然后where id > 最大id select * from table_name Where id > 最大id limit 10000,
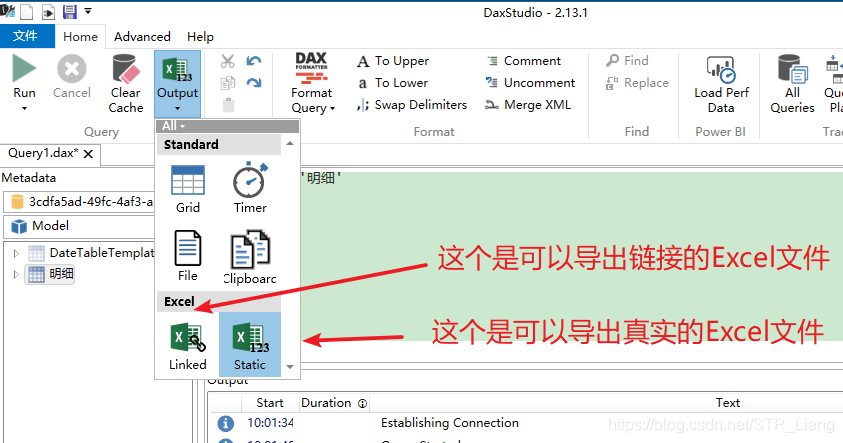
DAX Studio--导出PowerBi数据---(不使用复制表如何快速导出csv文件 / 如何导出百万级/千万级乃至亿级的数据量)多图预警!
多图预警! 1、打开Dax 点击Connect 2、在这里选择正在打开的PowerBi文件,点击Contect 3、选择导出方式--File F、输入指令(输入 EVALUATE ' )单引号可以进行快速提示 5、点击Run 6、选择文件路径,以及保存类型等(一般情况下,我们常用的类型是 txt 或者 第一种 UTF-8 的csv 文件),点击保存即可,稍等片刻,
如何在千万级数据中查询 10W 的数据并排序?都有什么方案?
程序员的成长之路 互联网/程序员/技术/资料共享 关注 阅读本文大概需要 7 分钟。 来自:https://juejin.cn/post/7104090532015505416 前言 在开发中遇到一个业务诉求,需要在千万量级的底池数据中筛选出不超过 10W 的数据,并根据配置的权重规则进行排序、打散(如同一个类目下的商品数据不能连续出现 3 次)。 下面对该业务诉求的实现,设计思路和方案优化

千万级到10亿+的疯涨,搜狗商业平台服务化体系实践之路
千万级到10亿+的疯涨,搜狗商业平台服务化体系实践之路 发表于 11小时前| 3502次阅读| 来源 《程序员》杂志| 6 条评论| 作者 么刚、王宇 《程序员》杂志 2015年11月B 架构 搜狗 数据库 width="22" height="16" src="http://hits.sinajs.cn/A1/weiboshare.html?url=http%3A%2F%2
详记一次MySQL千万级大表优化过程!
详记一次MySQL千万级大表优化过程! 互联网编程 JavaGuide 今天 原文地址:https://www.zhihu.com/question/19719997/answer/549041957 问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡