本文主要是介绍如何通过OMS加快大表迁移至OceanBase,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OMS,是OceanBase官方推出的数据迁移工具,能够满足众多数据迁移场景的需求,现已成为众多用户进行数据迁移同步的重要工具。OMS不仅支持多种数据源,还具备全量迁移、增量同步、数据校验等功能,并能够对分表进行聚合操作,例如将MySQL的分库分表数据通过OMS聚合到OceanBase数据库的单表中。
如需深入了解OMS的完整功能,请访问OceanBase的OMS文档进行进一步了解。
今日,我们的将主要介绍如何使用OMS迁移大表时,如何提升迁移速度。这在迁移历史库或归档库的数据时尤为重要,能够带来显著效益。接下来,我们将通过一个具体实例来探讨如何实现迁移过程的加速。
案例背景
最近遇到一个用户,使用 OMS 迁移 某数据到 OceanBase MySQL 模式,原表中的数据量大约有300+亿行,并且表存在longtext字段,这整体来看,是一个非常大的迁移工程,普通迁移也是至少耗时在周级别以上。用户在使用 OMS 迁移时,也遇到了很多问题:
- 原表中的表主键使用的是AUTO_RANDOM(5),这个是其源数据库特有的生成随机数方式,因为其分Region的方式是按range分,因此为了避免局部热点,需要随机生成。但是这样就导致一个问题,OMS在对源表进行切片时,效率非常差。
- OMS 在全量迁移时,会对表进行切片,根据主键的最大值和最小值,然后切分成多个分片分别进行迁移,因为表数据量非常大,导致分片数量非常多,影响迁移速度;
- OMS 日常迁移最快可以到30w行/秒,但是因为表中有longtext字段等原因,实测最多到1w行/秒,这样的迁移整体可能要超过1个月的时间;
- OMS 在写入目标端时,出现磁盘不足情况报错。
开始优化
问题1
首先,用户在 OMS 配置完迁移任务之后,发现迁移任务迟迟不开启同步,如下图,一直没有反应

这里因此对日志进行分析,查看 OMS 的 connetor.log 日志,发现在执行切片的 SQL 时,总是出现超时的报错,下面是报错的日志,日志的最后一条,就是执行切片的 SQL,可以看到会根据 id 字段进行一次排序。
The last packet successfully received from the server was 600,100 milliseconds ago. The last packet sent successfully to the server was 600,098 milliseconds ago.
460 at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
461 at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
462 at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
463 at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
464 at com.mysql.jdbc.Util.handleNewInstance(Util.java:425)
465 at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:990)
466 at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3562)
467 at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3462)
468 at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3905)
469 at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2530)
470 at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2683)
471 at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2495)
472 at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1903)
473 at com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:2011)
474 at com.alibaba.druid.pool.DruidPooledPreparedStatement.executeQuery(DruidPooledPreparedStatement.java:227)
475 at com.oceanbase.oms.dataflow.jdbcclient.AbstractJDBCClient.nextSlicePkTop(AbstractJDBCClient.java:1438)
476 at com.oceanbase.oms.dataflow.jdbcclient.AbstractJDBCClient.nextSlicePkTop(AbstractJDBCClient.java:1473)
477 at com.oceanbase.oms.dataflow.slice.PkSliceService.lambda$slice$2(PkSliceService.java:207)
478 ... 6 common frames omitted
479 Caused by: java.net.SocketTimeoutException: Read timed out
480 at java.net.SocketInputStream.socketRead0(Native Method)
481 at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
482 at java.net.SocketInputStream.read(SocketInputStream.java:171)
483 at java.net.SocketInputStream.read(SocketInputStream.java:141)
484 at com.mysql.jdbc.util.ReadAheadInputStream.fill(ReadAheadInputStream.java:101)
485 at com.mysql.jdbc.util.ReadAheadInputStream.readFromUnderlyingStreamIfNecessary(ReadAheadInputStream.java:144)
486 at com.mysql.jdbc.util.ReadAheadInputStream.read(ReadAheadInputStream.java:174)
487 at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:3011)
488 at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3472)
489 ... 17 common frames omitted
490 [2024-02-01 12:43:40.589] [INFO] [slice-worker-2] [SELECT `id` FROM `xxx`.`xxx` FORCE INDEX(`PRIMARY`) ORDER BY `id` ASC LIMIT 1]这里为什么执行切片。OMS 的全量迁移逻辑,首先默认会对源表的主键找到最大值和做小值,然后每600条数据(sliceBatchSize参数控制) 做一个分片,这样源表会切成多个分片,然后并发地同步多个分片到目标端,这样可以加快整个同步的任务。
因为表的数据量非常大,并且主键是 AUTO_RANDOM(5),因此要进行一次排序执行时间会很长,OMS 切片查询默认超时时间是 10 分钟,超时之后又会重试,因此这个 SQL 基本是执行不出来,所以迁移任务迟迟没有办法启动。
可以看到,想通过 OMS 自动来做切片,基本比较困难,因此这里第一个优化就是人工介入进行手动切片,这块在全量迁移的参数管理里有几个参数,可以帮助我们进行手动进行切片
source."sliceByMinMax"=true
source."sliceMinMaxValue"=5342,17870283355246524268
source."sliceBatchSize":6000- sliceByMinMax:设置为false,则表示人工手动设置最大值和最小值,而不是通过 SQL 去查;
- sliceMinMaxValue:设置主键 id 字段的最大值和最小值,这个我们自己可以根据 SQL 查询结果设置;
- sliceBatchSize:每个切片内的数据量
修改方式,在迁移任务的右上角-> 查看组件监控-> Full-Import 全量导入组件-> 点击更新,然后在source中加入这三个参数:

通过修改上面的参数,OMS 任务顺利运行起来了!
问题2
通过问题1的优化,虽然 OMS 迁移运行起来了,但是在执行一段时间之后发现,迁移任务又掉 0 了,并且持续时间很长

这里掉 0 之后,再次查看 connector.log 日志发现,因为我们手动设置了切片的最大值和最小值,而这个最大值和最小值相差比较大,所以在做分片的时候,因为很多切片区间是没有数据的,数据量为 0,所以在迁移这个切片时,实际没有数据迁移。
[2024-02-06 14:15:10.035] [INFO] [sourceTask-11] [xxx.xxx {xxx.xxx PK 13216115 [id:79296689342] - [id:79296695342]} rows : 0 , onNewBatchState:0.021]实际这里 id 字段并不是连续递增的,因为 AUTO_RANDOM(5) 的缘故,导致表中 id 字段的最大最小值跨度非常大,但是小的值很多都是空的,所以 id 字段并不适合用来做切片。
因此是需要重新选择一个字段用来做切片的,经过对表结构分析,发现有个时间的字段比较适合来做切片 created double(20,8),字段保存的是:秒的时间戳+毫秒,用了double类型,时间精确到了毫秒,因为时间是连续的,并且跨度不大,基本每个时间段内都是有数据的,所以相比较来说是适合用来切片,并且上面有索引,切片查询是范围扫,不会太慢。
这里就需要另外修改一个参数,来指定切片使用这个字段
sliceIndex: {"库名.表名": "索引名:字段名"}另外考虑到 sliceBatchSize 为 600,created字段每相差600秒内的数据量不能太大,否则每个切片数据量会比较大,迁移任务的jvm内存可能会撑爆。
因此重新调整参数之后如下:
source."sliceByMinMax"=true
source."sliceIndex"={"库名.表名": "索引名:created"}
source."sliceMinMaxValue"=1293595467,1707212258
source."sliceBatchSize":60
重新调整之后,恢复任务开始重新同步。
问题3
用户在遇到上面几个问题时,用的 OMS 版本还是4.2.1的版本,4.2.1 版本是不支持旁路导入的。旁路导入实际上是一个针对大表迁移的最优方式,旁路导入支持向 data 文件中直接写入数据,可以绕过 SQL 层的接口,直接在 data 文件中分配空间并插入数据,从而提高数据导入的效率,测试发现整体效率可以提升3-6倍。
这块因为在用户遇到这个问题时,OMS 4.2.2 版本即将发布,因此在让用户等了两天之后,将 OMS 升级到4.2.2 版本,开始使用旁路导入的方式。
旁路导入的配置也很简单,如下图,在配置 OMS 迁移任务时,在迁移选项中有个写入方式的选项,这里选择Direct Load方式,这样数据的迁移就会自动使用旁路导入的方式。

不过旁路导入这里有个问题,就是如果表中有数据,需要将数据清空之后再开始导入。即使旁路导入报错中断,如果要恢复迁移的话,也是需要重新清空表。
如何确认是否成功开启了旁路导入,这块可以在迁移任务的参数配置页面看到,如下图,出现direct.sink时,说明启动了旁路导入功能。

问题4
在任务开始一段时间后,OMS 收到报错
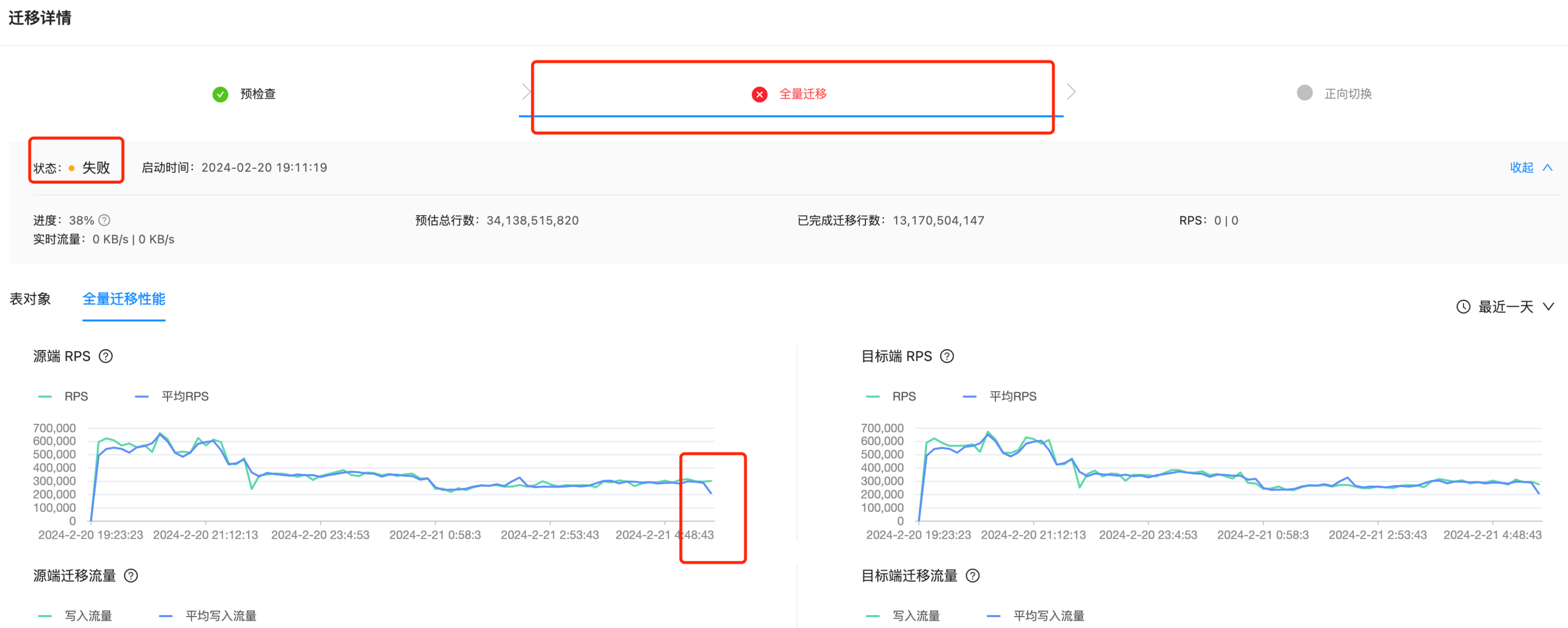
查看日志报错如下
[2024-02-21 05:37:06.473] [WARN] [sinkTask-27] [SyncSinkTask run ignore error, batch [com.oceanbase.oms.dataflow.common.stream.PartOfStreamRecordBatch
@67403183], cause [{}]]
java.lang.RuntimeException: Direct insert into "actions" failedat com.oceanbase.oms.connector.direct.sink.DirectPathWriter.flushRecords(DirectPathWriter.java:120)at com.oceanbase.oms.connector.direct.sink.DefaultDirectPathSink.offer(DefaultDirectPathSink.java:68)at com.oceanbase.connector.framework.threadmanager.sinktask.SyncSinkConnectorTask.run(SyncSinkConnectorTask.java:47)at java.lang.Thread.run(Thread.java:853)
Caused by: java.sql.SQLException: status : ERROR , error code : -4184at com.oceanbase.oms.connector.direct.sink.DirectPathConnection.insert(DirectPathConnection.java:233)at com.oceanbase.oms.connector.direct.sink.DirectPathPreparedStatement.executeBatch(DirectPathPreparedStatement.java:103)at com.oceanbase.oms.connector.direct.sink.DirectPathWriter.flushRecords(DirectPathWriter.java:95)... 3 common frames omitted可以看到返回了4184的错误,查看 OceanBase 错误码,4184 的报错表示磁盘满了,实际这里只迁移了1亿多行,根据估算,是不能把磁盘写满的。
因此对每个磁盘的容量进行排查,发现每个 zone 只有 2 台机器上有流量,其他 4 台机器上基本没有写入流量,这里怀疑可能出现了数据的倾斜。但是这张表创建的是时候是做了分区,分区是均匀打散到所有机器上的,不应该出现倾斜。
继续排查发现,因为业务量随着时间不断增长,年份越近,数据量越大,分区打散虽然是按分区数量打散的,但是没有考虑到数据量的问题,可以看到2018年的数据量明显比2015年大很多。
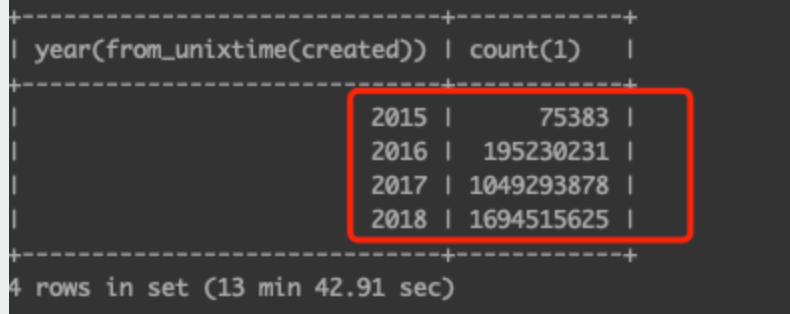
而2018年的所有分区是集中在了一台机器上,导致这台机器的数据量非常大,这个是不符合预期的。经过验证,发现 OceanBase 目前在创建分区的时候,会以多个分区为一组,然后将这一组的分区集中到一台机器上,这个在range分区时有些不太合理。例如2018年按月有12个分区,一般情况下这12个分区应该在同一个zone中的6台机器上每台上有2个分区,同理2017年的分区也是这样。而实际时2017年的所有分区在一台机器上,2018年的所有分区在另一台机器上。这块和OceanBase官方确认之后,这块后续会做优化。
不过目前这种情况,有两种方式可以解决:
- 在创建二级分区,二级分区使用hash分区,进一步将分区打散;
- 手动迁移分区,迁移分区方式参考:Transfer Partition
因业务模型关系,这里无法做二级分区,否则会导致大量的跨机事务,因此只能选择手动迁移分区。
其他优化
优化1:
除了上面三个问题的解决,另外为了加快整体同步速度,这里还做了对JVM的调整,因为用户的 OMS 机器配置较高,所以默认的 JVM 参数无法全部发挥机器的性能。
调整 JVM 参数,同样也是在迁移任务的参数配置页面,修改如下
connectorJvmParam=-server -Xms64g -Xmx64g -Xmn60g -Xss512k 优化2:
当资源充分的情况下,也可以修改 source 和 sink 端的 workNum 数量,默认是8,这里也是修改成了32
source.workNum: 32
sink.workNum: 32优化后收益
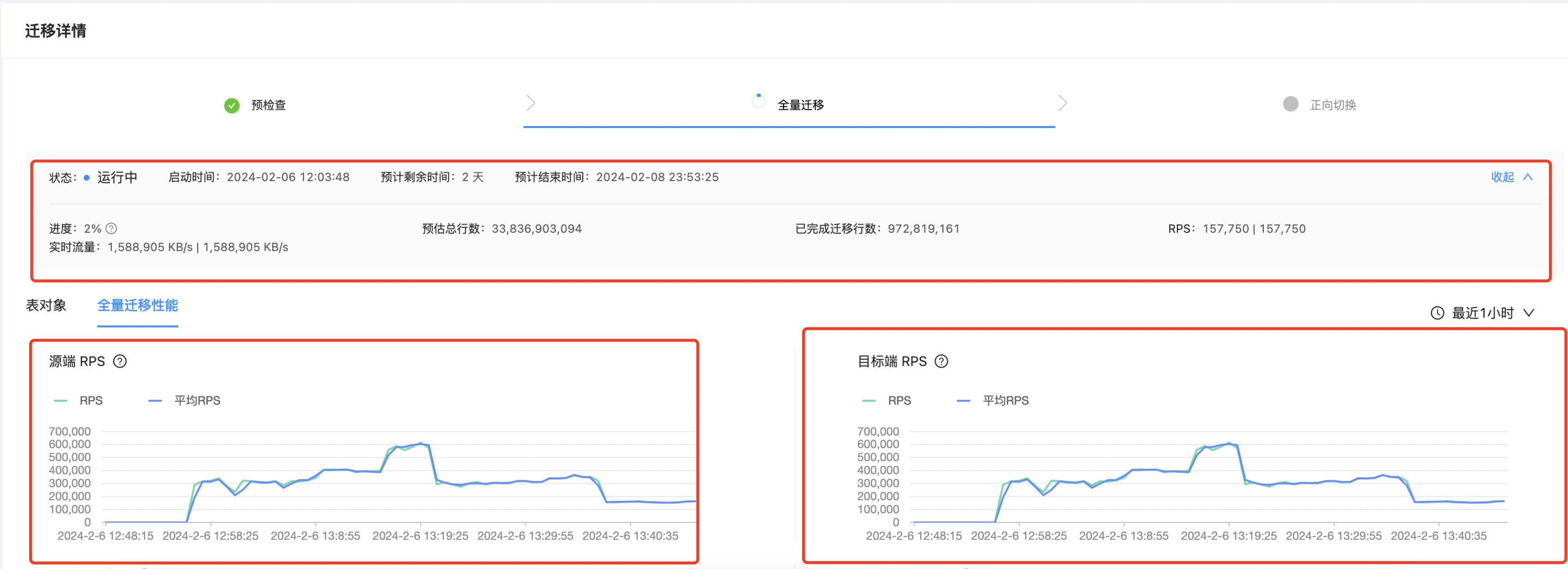
经过以上这些优化之后,这张大表的迁移实时流量基本达到了 1.5G/s,RPS最高可以达到 61w行/s,可以看到整体收效明显,如果迁移正常的话,基本2-3天就可以完成这张大表的迁移。
这篇关于如何通过OMS加快大表迁移至OceanBase的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!