本文主要是介绍关于OceanBase MySQL 模式中全局索引 global index 的常见问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在OceanBase的问答区和开源社区钉钉群聊中,时常会有关于全局索引 global index的诸多提问,因此,借这篇博客,针对其中一些普遍出现的问题进行简要的解答。
什么是 global index ?
由于 MySQL 不具备 global index 的概念,因此这一问题会经常被社区版用户提及。就在前几天,就要人询问下面这个语法的意义。
create table part_test_tbl(id int,age int,unique key uk_id_idx(id) partition by hash(id),key age_idx(age) partition by hash(age));这个问题的答案可以直接照搬 OB 官网上全局索引的概念:全局索引的创建规则是在索引属性中指定 GLOBAL 关键字。与局部索引相比,全局索引最大的特点是全局索引的分区规则跟表分区是相互独立的,全局索引允许指定自己的分区规则和分区个数,不一定需要跟表分区规则保持一致。
为什么要有 global index ?
在关系性数据库中,索引通常被组织成一颗 B+ 树的形式,叶子节点按照键值的大小被有序存放,索引的键值跟主表上的数据一一对应,当用户指定索引条件访问数据的时候,可以迅速的通过搜索 B+ 树上的对应关系,快速定位到被访问到的数据在主表中的位置。
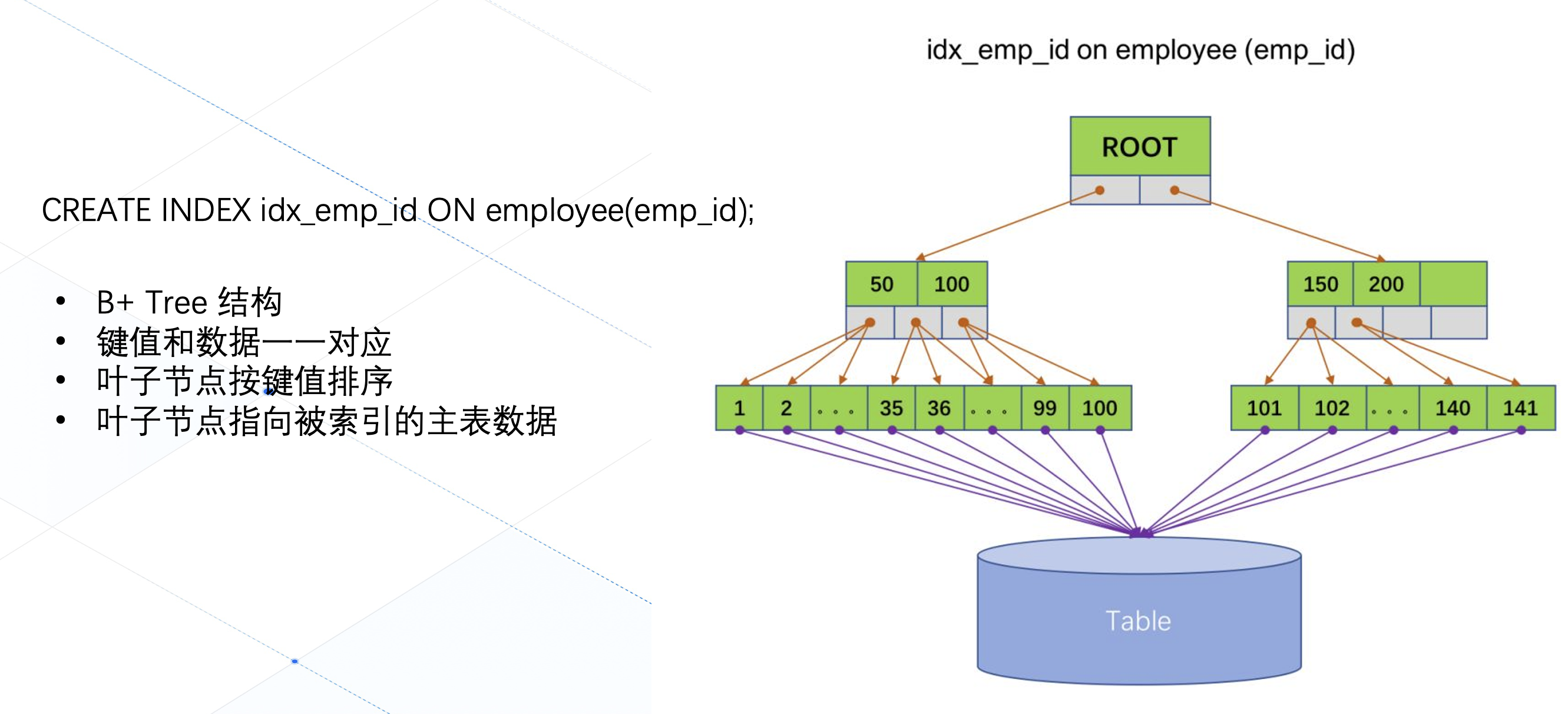
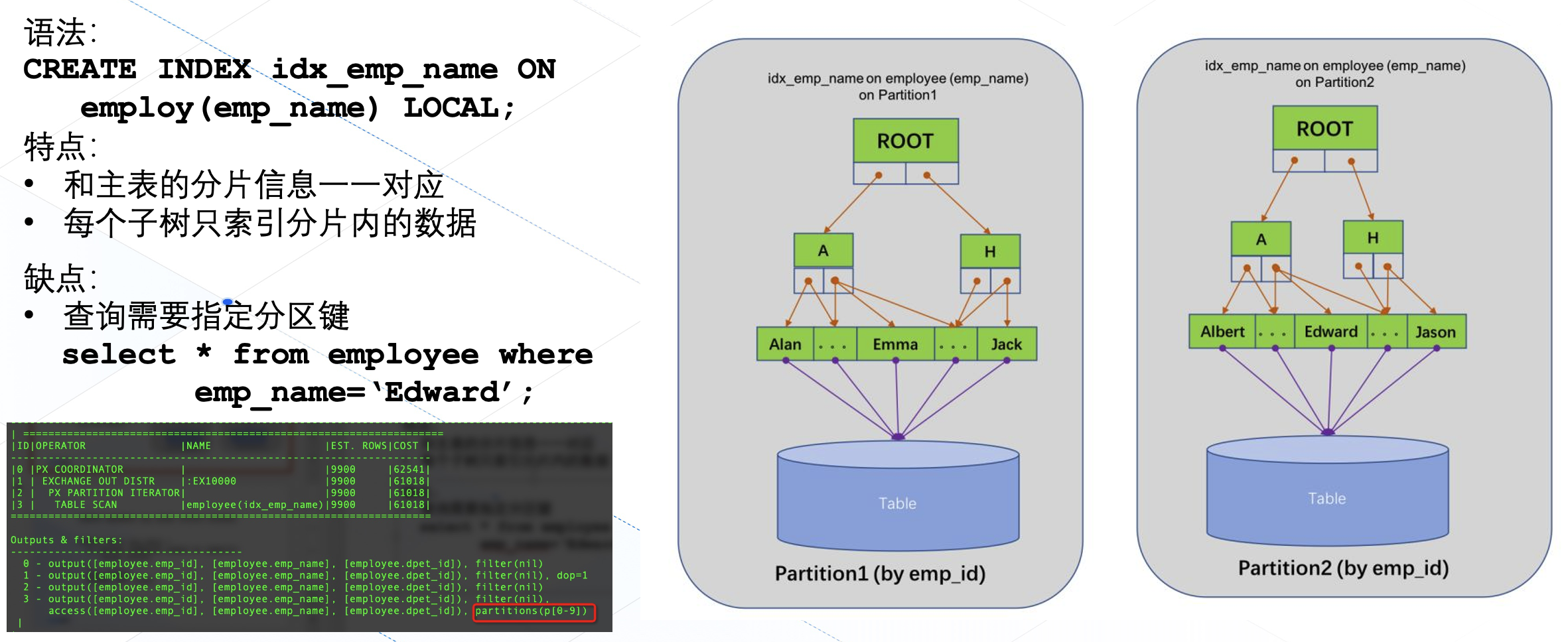
当主表数据被拆分成多个分片的时候(在 OB 中叫分区表),索引应该怎么拆分?一个思路是让索引跟主表一起拆分,拆分后的索引只检索当前分区中的部分数据,这样的索引我们一般称为本地索引(Local Index,MySQL 就只支持这种索引)。在 OB 中要创建这样的索引也很简单,只需要在语句最后指定一个 local 关键字即可。这样的索引有什么缺点呢?
首先第一个缺点就是我们的查询必须要指定分区键,否则,数据库将不知道你需要检索的数据位于哪个分片中,只能枚举出所有的数据分片,让查询效率变低。这里我们展示了一个这样的例子(主表 employ 是分区表,分区键是 emp_id),如果查询中的过滤条件没有指定主表的分区键 emp_id,从执行计划的红框部分可以看出来,数据库就会扫描所有的数据分片。
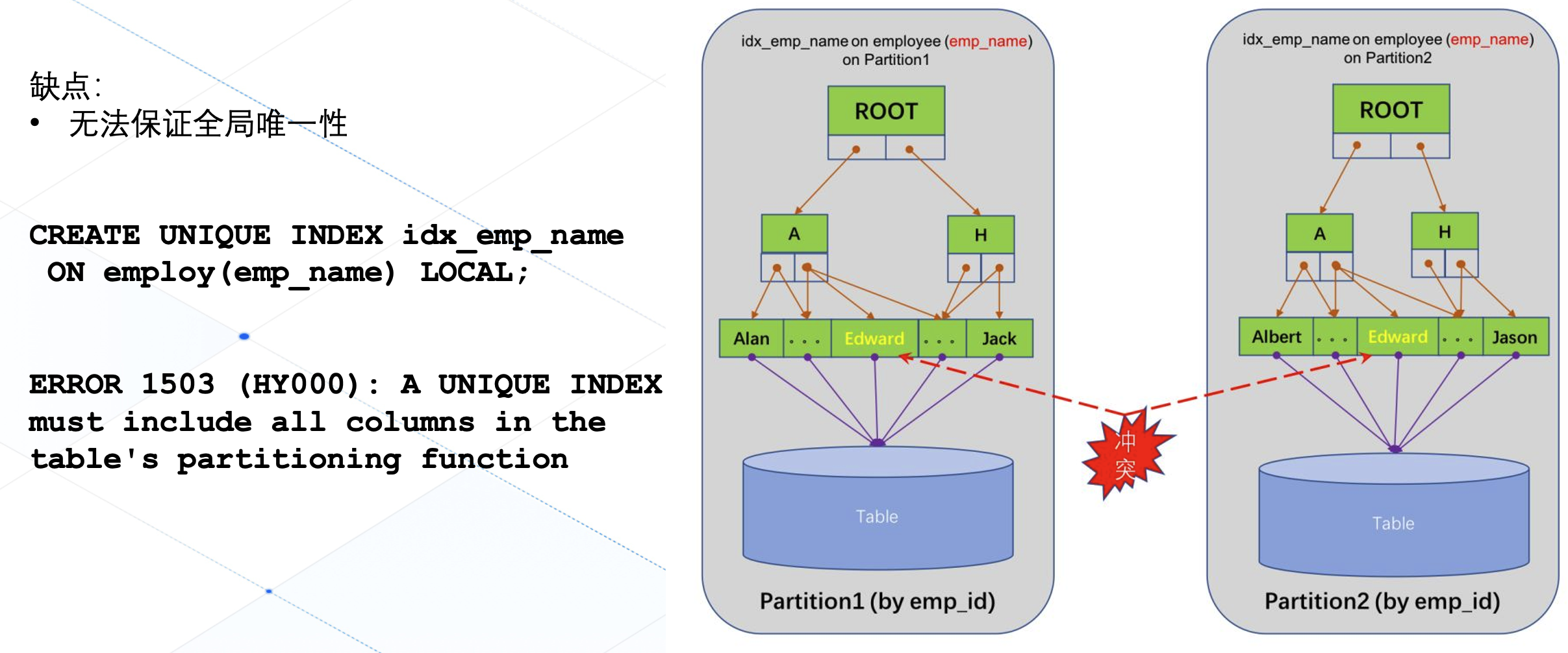
另一个缺点就是由于本地索引是创建在数据分片内部,因此无法保证索引键值的全局唯一性,比如我们下边的这个例子中,本地索引的两部分都可能出现 'Edward' 这个重复键值,因此数据库要求要创建带唯一性约束的本地索引必须要指定数据分片的分区键。
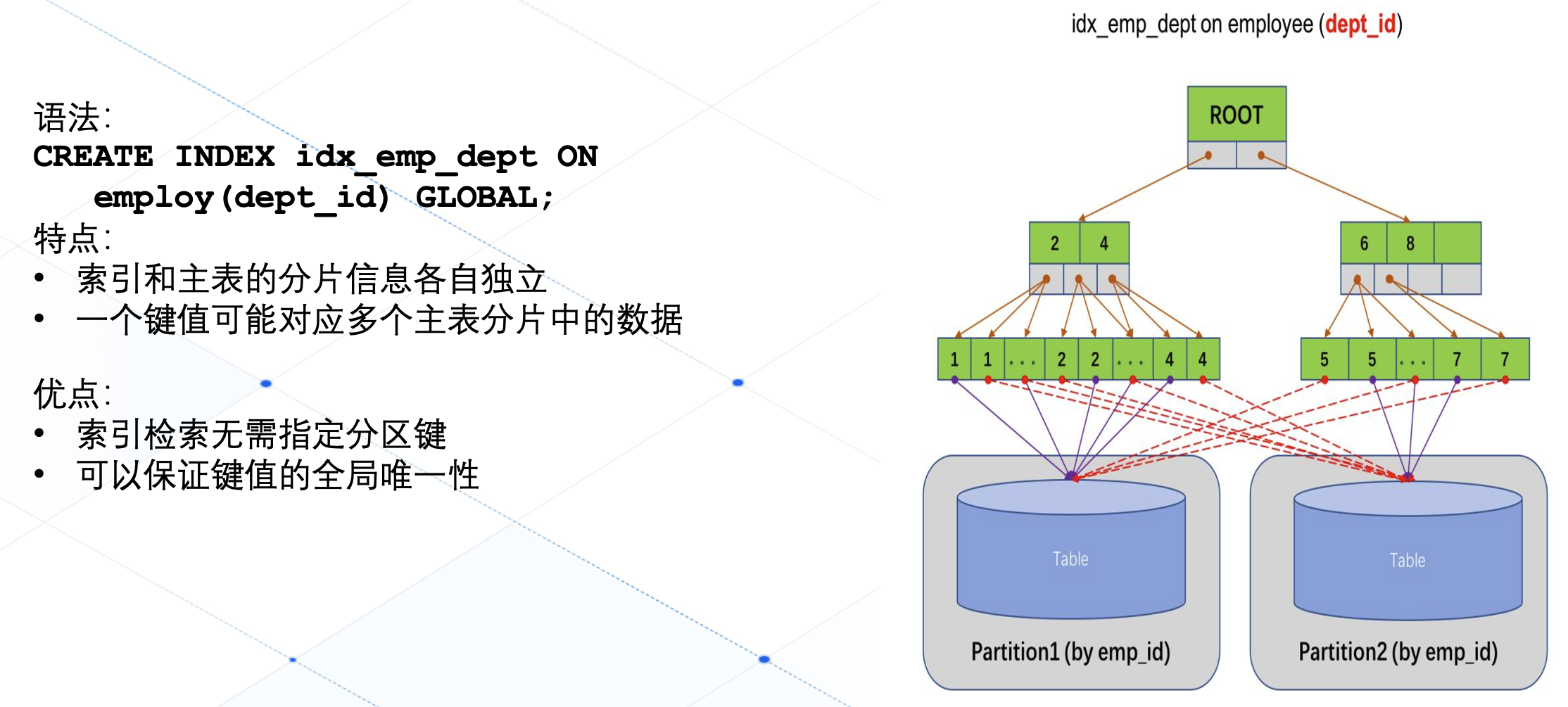
为了解决本地索引的这些不好的用户体验,OceanBase 数据库在 MySQL 模式下又推出了一种新的索引形式,那就是全局索引(Global Index),它和本地索引(Local Index)的本质区别是:全局索引的索引结构并不跟主表的分片信息一一对应,它们数据的分片位置信息是各自独立的。同时呢,一个索引键值可能会对应到不同的主表分片当中,例如在我们右边展示的这个索引结构中,索引键值 1,2,5 都同时对应了两个不同分区里的数据,因此在使用全局索引进行数据检索的时候,我们不再需要指定分区键,同时由于全局索引的索引结构是独立于主表的,索引键值的全局唯一性在这里也可以很好的被保证。
要创建一个全局索引也很简单,只需要我们在创建索引的语法后面指定一个 global 关键字就好了(如果索引后面有分区信息会被默认当作 global index,否则会被默认当作 local index)。
create table t1(c1 int, c2 int, c3 int);create index idx1 on t1(c1);create index idx2 on t1(c2) global;create index idx3 on t1(c3) partition by hash(c3);show create table t1\G
*************************** 1. row ***************************Table: t1
Create Table: CREATE TABLE `t1` (`c1` int(11) DEFAULT NULL,`c2` int(11) DEFAULT NULL,`c3` int(11) DEFAULT NULL,KEY `idx1` (`c1`) BLOCK_SIZE 16384 LOCAL,KEY `idx2` (`c2`) BLOCK_SIZE 16384 GLOBAL,KEY `idx3` (`c3`) BLOCK_SIZE 16384 GLOBALpartition by hash(c3)
(partition p0));什么场景适合使用 global index ?
刚才我们了解了全局索引的两个好处,那么在 OceanBase 这样的分布式数据库中,是不是应该无条件使用全局索引呢?由于全局索引可能会出现跨节点的数据访问,因此数据检索过程中,RPC 的代价是无法忽略的,因此并不是所有情况下用全局索引都比本地索引表现更好。那哪些场景我们推荐使用全局索引呢?
-
- 如果索引键能够覆盖用户检索的全部字段,这种情况下,索引检索不需要再去访问主表,这种情况全局索引代价会比本地索引更小。
- 如果检索的数据量比较少(100行以内),回表所产生的 RPC 代价也会较小,这种情况下,我们也推荐使用全局索引。(前两天听到几个经验值:1 秒钟可以让 100 万行数据 I/O,或者让 10 万行 local index 回表,或者让 1 万行 global index 回表。)
- 如果需要保证索引键满足唯一性约束,并且索引键不包含分区键信息,这种情况下,由于本地索引自身的唯一性缺陷,也只能选择全局索引。
总的来说,全局索引相比于本地索引实现会更加复杂,尤其在分布式数据库中,只有少数的商业数据库支持这种索引形式,但是它对用户的使用约束更小,体验也会更好。
其他几个常见问题
为什么主键索引不能设置成 global 属性
OceanBase 数据库的表目前都是索引组织表(Index Organized Table,简称 IOT 表),暂时还没有支持堆表。索引组织表是一种数据库表的存储方式,它的特点是根据表的主键索引来组织数据,而不是按照数据的物理顺序来组织。因为每张表都是根据主键索引来组织的,所以主键和主表的组织形式一定是一致的,不能设置成 global 属性。
顺带一提,OceanBase 中的无主键表其实也有隐藏主键,是个自增列,column id 为 1, column name 叫 __pk_increment,有兴趣的同学可以去查查 oceanbase.__all_column 看一下。
为什么分区表的分区键一定要被包含在本地唯一索引和主键索引里?
OceanBase 官网文档上说:如果需要在分区表上创建局部分区唯一索引( Local Partitioned Unique Index ),则该索引键需要包含主表的分区键,而对于全局分区唯一索引( Global Partitioned Unique Index )并没有这个限制。
create table t1(c1 int unique key, c2 int) partition by hash(c2);
ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning functioncreate table t1(c1 int primary key, c2 int) partition by hash(c2);
ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function刚才上面介绍 global index 的时候提到了:唯一索引上数据的唯一性检查是只在当前分区做的,如果唯一索引不包含全部分区键,例如让 create table t1(c1 int unique key, c2 int) partition by hash(c2); 执行成功的话,主表上的数据可能会是:
| c1 | c2 |
| 1 | 1 |
| 1 | 2 |
| 2 | 1 |
| 2 | 2 |
| 3 | 1 |
| 3 | 2 |
这时第一个分区的数据是:(在这个分区中 c1 是满足唯一性的,唯一性检查会成功)
| c1 | c2 |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
第二个分区的数据是:(在这个分区中 c1 也是满足唯一性的,唯一性检查也会成功)
| c1 | c2 |
| 1 | 2 |
| 2 | 2 |
| 3 | 2 |
这就会出现:所有分区在对 c1 做唯一性检查时都成功了,数据库认为 c1 列已经满足了唯一性,但实际上 c1 列的数据却并没有满足唯一性。主键同理。当然,MySQL 和 Oracle 数据库也有相同的要求和限制。如果唯一索引被打上了 global 的属性,就不会再和主表使用一样的分区规则去进行分区,自然也就没有这个唯一性检查出错的问题了。
如果大家对 global index 还有什么其他问题,可以在博客下面留言,我们一起学习和探讨~
这篇关于关于OceanBase MySQL 模式中全局索引 global index 的常见问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







