本文主要是介绍mysql中两千万大表做时间范围查询很慢,怎么解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
预备知识
1、一个表的数据量达到好几千万或者上亿时,加索引的效果没那么明显啦。性能之所以会变差,是因为维护索引的B+树结构层级变得更高了,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢。
少量数据可以考虑使用数据索引
2、InnoDB存储引擎最小储存单元是页,一页大小就是16k。
B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据;
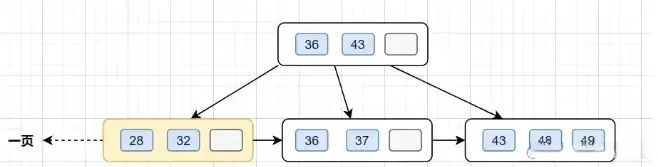
假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。
-
如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16.
-
非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(面试官问你int类型,一个int就是32位,4字节),而指针大小在InnoDB源码中设置为6字节,所以就是8+6=14字节,16k/14B =16*1024B/14B = 1170
因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,也就是说,可以存放两千万左右的记录。B+树高度一般为1-3层,已经满足千万级别的数据存储。
如果B+树想存储更多的数据,那树结构层级就会更高,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢。
解决方案考虑:可以考虑将页的大小调大减少IO;
如何调整B+树的N大小?
1, 通过改变key值来调整
N叉树中非叶子节点存放的是索引信息,索引包含Key和Point指针。Point指针固定为6个字节,假如Key为10个字节,那么单个索引就是16个字节。如果B+树中页大小为16K,那么一个页就可以存储1024个索引,此时N就等于1024。我们通过改变Key的大小,就可以改变N的值
2, 改变页的大小
页越大,一页存放的索引就越多,N就越大。
数据页调整后,如果数据页太小层数会太深,数据页太大,加载到内存的时间和单个数据页查询时间会提高,需要达到平衡才行。
2、其他解决方案
2.1 数据表分区
举例
CREATE TABLE orders (id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,order_no VARCHAR(20) NOT NULL,order_date DATE NOT NULL,amount DECIMAL(10,2) NOT NULL,PRIMARY KEY (id, order_date)
) ENGINE=InnoDB
PARTITION BY RANGE(YEAR(order_date))
(PARTITION p_2018 VALUES LESS THAN (2019),PARTITION p_2019 VALUES LESS THAN (2020),PARTITION p_2020 VALUES LESS THAN (2021),PARTITION p_other VALUES LESS THAN MAXVALUE
);
2.2 分库分表
采用水平分表,按月或按年分表
实施方案
1.取模方案:
拆分之前,先预估一下数据量。比如用户表有4000w数据,现在要把这些数据分到4个表user1 user2 uesr3 user4。比如id = 17,17对4取模为1,加上 ,所以这条数据存到user2表。
注意:进行水平拆分后的表要去掉auto_increment自增长。这时候的id可以用一个id 自增长临时表获得,或者使用 redis incr的方法。
优点:数据均匀的分到各个表中,出现热点问题的概率很低。
缺点:以后的数据扩容迁移比较困难难,当数据量变大之后,以前分到4个表现在要分到8个表,取模的值就变了,需要重新进行数据迁移。
2.range 范围方案
以范围进行拆分数据,就是在某个范围内的订单,存放到某个表中。比如id=12存放到user1表,id=1300万的存放到user2 表
优点:有利于将来对数据的扩容
缺点:如果热点数据都存在一个表中,则压力都在一个表中,其他表没有压力。
我们看到以上两种方案 都存在缺点 但是却又是互补的,那么我们将这两个方案结合会怎样呢?
3.hash取模和range方案结合
如下图 我们可以看到 group 组存放id 为0~4000万的数据,然后有三个数据库 DB0 DB1 DB2,DB0里面有四张表,DB1 和DB2 有三张表
假如id为15000 然后对10取模(为啥对10 取模 因为有10个表),取0 然后 落在DB_0,然后在根据range 范围,落在Table_0 里面。

分区分表的区别:
1、实现方式上
-
mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完整的一张表,都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm表结构
-
分区不一样,一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。
2、提高性能上
-
分表重点是存取数据时,如何提高mysql并发能力上;
-
而分区呢,如何突破磁盘的读写能力,从而达到提高mysql性能的目的。
3、实现的难易度上
1、分表的方法有很多,用merge来分表,是最简单的一种方式。这种方式根分区难易度差不多,并且对程序代码来说可以做到透明的。如果是用其他分表方式就比分区麻烦了。2、分区实现是比较简单的,建立分区表,根建平常的表没什么区别,并且对开代码端来说是透明的
分区分表的联系
1、都能提高mysql的性高,在高并发状态下都有一个良好的表现。
2、分表和分区不矛盾,可以相互配合的,对于那些大访问量,并且表数据比较多的表,我们可以采取分表和分区结合的方式,访问量不大,但是表数据很多的表,我们可以采取分区的方式等。
分库分表存在的问题
1、事务问题
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
2、跨库跨表的join问题
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
3、额外的数据管理负担和数据运算压力
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
2.3 冷热数据归档
归档表数据的初始化
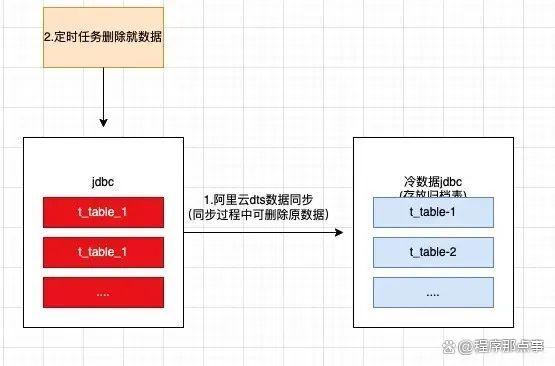
1、业务增量数据处理过程

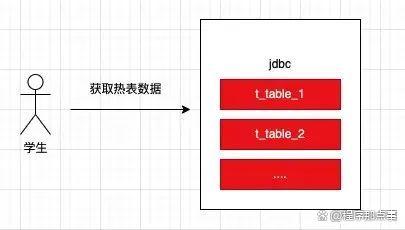
2、数据的获取过程
2.4 同步至es中进行查询
3. 方案选择

这篇关于mysql中两千万大表做时间范围查询很慢,怎么解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



