噪音专题

AudioSep:从音频中分离出特定声音(人声、笑声、噪音、乐器等)本地一键整合包下载
AudioSep是一种 AI 模型,可以使用自然语言查询进行声音分离。这一创新性的模型由Audio-AGI开发,使用户能够通过简单的语言描述来分离各种声音源。 比如在嘈杂的人流车流中说话的录音中,可以分别提取干净的人声说话声音和嘈杂的人流车流噪声。可以根据需求分离,保留人声或者噪声。甚至可以单独提取声音中的笑声。除此之外,还能提取伴奏声音里指定的乐器声音,比如一段钢琴和吉他合奏曲目,需要单独分

小区噪音监测管理系统设计
一、引言 随着城市化进程的加快,小区居民对于居住环境的要求日益提高。其中,噪音污染已成为影响居民生活质量的重要因素。因此,设计一套小区噪音监测管理系统,对于提升居民的生活品质和小区管理效率具有重要意义。本文将详细阐述该系统的设计要点,包括监测点选择与布置、传感器选型与配置、数据采集与传输、数据处理与分析、监测结果可视化、预警与报警机制、系统管理与维护以及用户权限与访问控制等方面。 二、监测
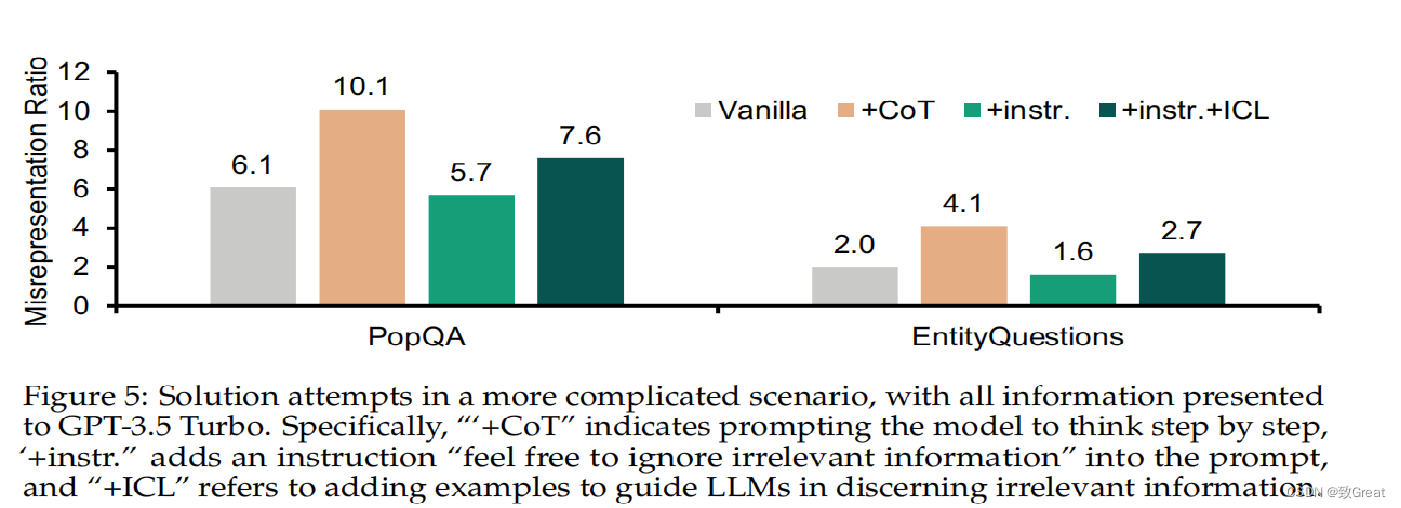
【RAG论文】检索信息中的噪音是如何影响大模型生成的?
前些天看到的两篇论文,论文标题为: 《The Power of Noise Redefining Retrieval for RAG Systems》《How Easily do Irrelevant Inputs Skew the Responses of Large Language Models》 主要讲述了检索文档是如何影响大模型输出的以及相关实验结果,为了浪费时间,大家可以参考下其中的
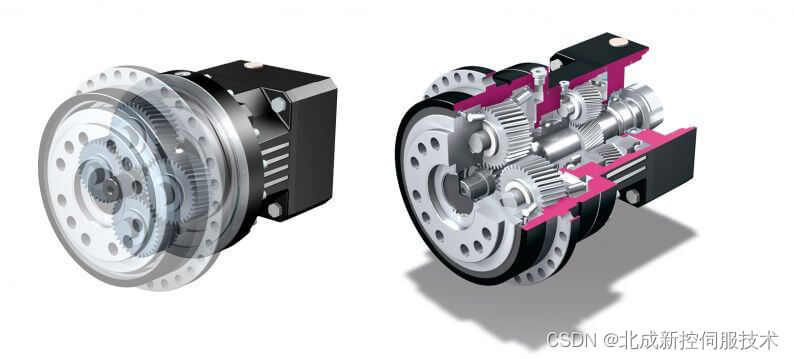
台湾精锐APEX行星减速机噪音产生及优化策略
台湾精锐APEX行星减速机在各种机械装置中的应用逐渐广泛。然而,其噪音问题也日益凸显。噪音不仅影响工作环境,还可能对设备的正常运行和使用寿命产生负面影响。因此,了解APEX行星减速机噪音的产生以及优化噪音问题变得至关重要。 APEX行星减速机的噪音主要源于传动齿轮的摩擦、振动和碰撞。许多学者认为,齿轮传动中轮齿啮合刚度的变化是导致齿轮动载、振动和噪声的主要因素。为了降低噪音,一种常用的方法是通过

【全方位检查笔记本大噪音的来源】
夏天来了。天气热了,该为我们的心爱本本降降温,本想用风扇给我们心爱的本本降温,这时却出现了一个大问题:噪音非常大,这可怎么是好?有问题就有解决的办法。跟着系统吧小编一起来解决这个问题 笔记本电脑噪音来源 首先我们要知道,笔记本噪音主要的来源有以下四个方面:第一是笔记本的散热风扇工作时产生的,第二是机械硬盘读取数据时产生的,第三是光驱工作时产生的,第四是各种电子元器件工

SuperCollider学习笔记(二)- 噪音(Noise)
定义 噪音来自无周期的信号源(Aperiodic Sources),即声波的频率、强弱变化无规律、杂乱无章的声音,与振荡器产生的有固定频率和振幅的信号相对。 分类解读 低频噪音生成器(“Low Frequency” Noise Generators) 这一分类下有LFNoise0,LFNoise1,LSNoise2,LFClipNoise等,它们的参数为frequency(频率), mul


壁挂炉噪音大是怎么回事?有什么解决方法?
燃气壁挂炉属于精密仪器,在冬季供暖时,不时会发出嗡嗡的噪音。可是如今一些品牌生产的壁挂炉在运行时声音都比较小,基本都会在40分贝以下,完全符合国家的标准。为什么还有不正常的噪音?小松哥带你一探究竟。 壁挂炉运行时机器振动噪音 这种噪音很有可能是由于壁挂炉安装位置不恰当,导致壁挂炉内部设备风机运行时与机壳产生共振,使壁挂炉在运行中产生不同程度的噪音。在这种情况下,调整好调节风机的软连
CUTTag技术优势——特异性强,背景噪音较低
CUT&Tag是一种新的DNA—蛋白质互作研究方法。与传统的ChIP-Seq相比,CUT&Tag技术操作简便,无需免疫共沉淀和超声破碎;细胞起始量低。60-100000个细胞就可以满足需要,且CUT&Tag单细胞技术已经实现;一步完成建库,不需要传统的修复末端,加A,加接头构建文库;信噪比高。 CUT&Tag技术优势——特异性强,背景噪音较低;灵敏度强;重复性较好;成本远低于ChIP-Seq

obs噪音抑制调多少合适_(3)阿里国际站OBS申请设置使用教程,国际站直播回放如何下载?OBS音频没有声音怎么办?...
点击蓝色字关注我们! 一个努力中的公众号 长的好看的人都关注了 本文共:5413字 预计阅读时间:14分钟 今天阿刁给大家带来国际站直播第三篇,OBS推流设置教程。 国际站OBS怎么申请,国际站开放OBS了吗?OBS怎么用,OBS音频没有声音怎么办?阿里国际站的OBS应该怎么设置,国际站直播回放如何下载?国际站阿刁为你解答。 先说点没用的题外话,九月公司内部鸡血打圈战,不知道有没有人知道圈
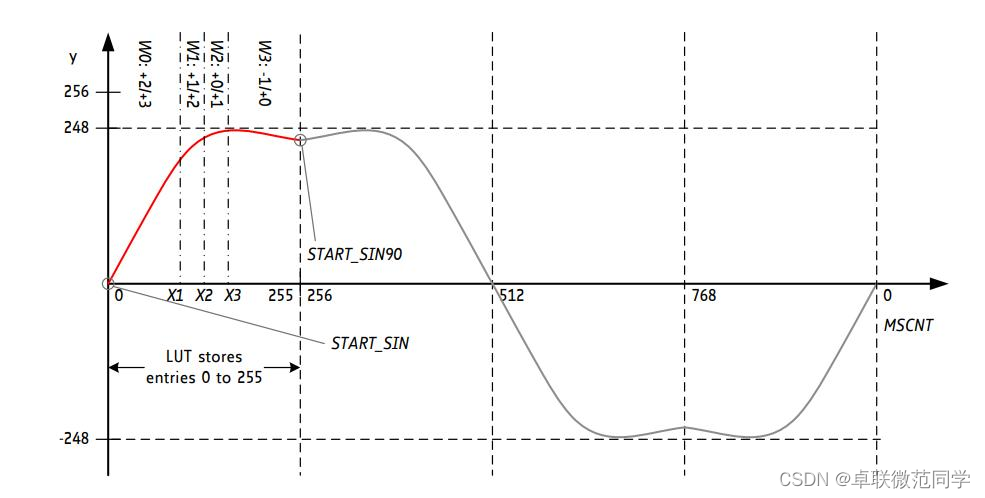
如何提步进电机高精度,降低噪音和共振?(TMC)
以下这个方法特别适合用于 PM 电机或者大力矩的步进电机优化微步波形效果,因为这些电机的制造这些电机的电机制造商通常无法实现对正弦波的良好适应,因为他们必须优化极靴以获得高扭矩,或者易于制造。 采取TMC开发板来调试 有噪音或者共振或者震动就可以调整 波形不好的话就可以使用该工具来调整微步波形表。 这个工具的作用是在低速情况下它有助于更精确控制微步,降低运行噪音,减少电机的共振和震动。不适合高速。
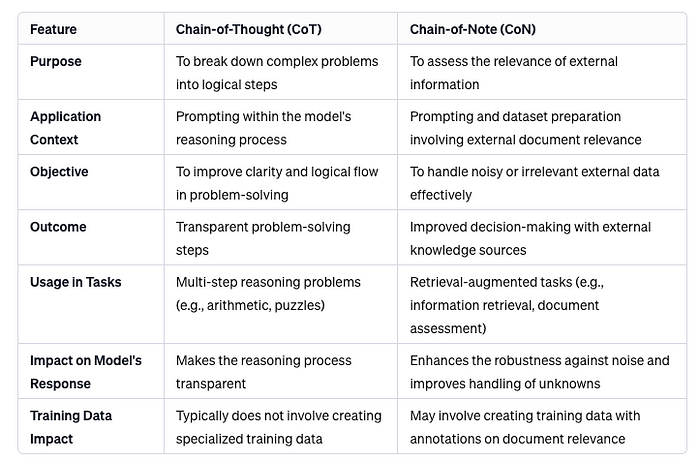
消除噪音:Chain-of-Note (CoN) 强大的方法为您的 RAG 管道提供强大动力
论文地址:https://arxiv.org/abs/2311.09210 英文原文地址:https://praveengovindaraj.com/cutting-through-the-noise-chain-of-notes-con-robust-approach-to-super-power-your-rag-pipelines-0df5f1ce7952

python机器学习之降维算法PCA人脸识别中的参数和接口案例,用PCA做噪音过滤
降维算法PCA 一.人脸识别中的components_ 应用 首先导入所需要的库 from sklearn.datasets import fetch_lfw_people#人脸识别数据from sklearn.decomposition import PCA import matplotlib.pyplot as pltimport numpy as np 实例化数据集 fac
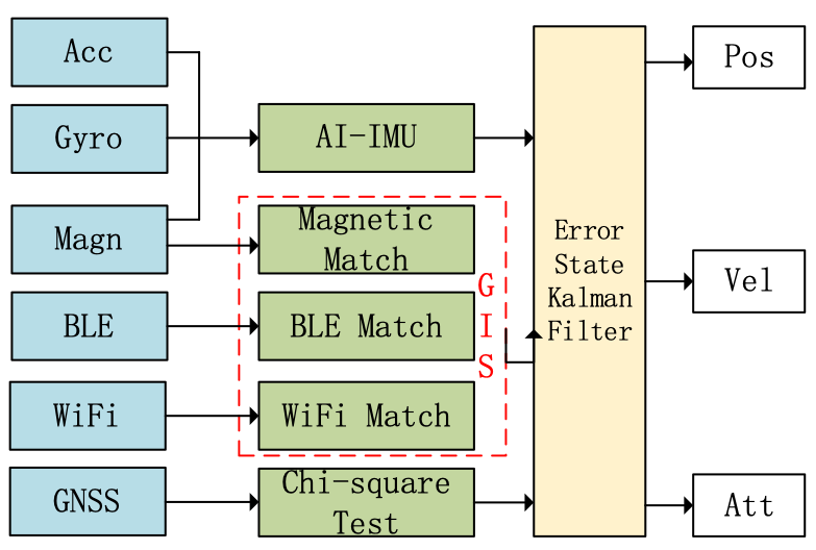
攻克“信号噪音”,高德武大联队卫冕全球定位大赛冠军
在人手一部智能手机的时代,出门用手机导航已非常普遍。但在这种平常的背后,则是一整套复杂技术方案的支撑。尤其是定位技术,更是地图导航底层的重要基础,直接决定了产品的使用体验。“让定位更精准”,也成为了全球各大相关机构和企业竞相角逐的“技术奥林匹克”。 近日,在西班牙刚闭幕的室内定位与导航领域国际会议IPIN2021上,武汉大学与高德地图联合团队以大幅领先的优势,斩获了“基于智能手机的室内定位”赛道
如何消除视频中的背景噪音
如果你在繁忙的街道上、刮风的日子、或在其他有嘈杂声音的周围拍摄视频,则会产生令人烦恼的噪音。幸运的是,从视频中消除背景噪音并不是一件困难的事情,因为有许多可靠的降噪软件可以提供帮助。本文就收集了3种最佳方法,可帮助你轻松减少视频中的背景噪音。 一、使用金狮视频助手在 Win/Mac 上消除视频中的背景噪音 金狮视频助手提供先进的功能来编辑视频和消除背景噪音,只需简单的操作即可为您输出视频。它的
ACT45L-201-2P-TL000 ---- 车载以太网的高效噪音抑制
近年来,汽车传感器系统及摄像头系统设备不断增加,以太网作为此类先进多媒体以及信息通信系统车载 LAN 得到了快速的引进。 TDK开发出了在小型、低背形状下实现了优异噪音抑制特性的以太网用共模滤波器ACT45L系列。 有望作为车载LAN的主干网络的以太网 车载LAN可大致分为车体系统、安全系统、动力传动系统、多媒体及信息通信系统。现在,以车体系统为中心最为普及的是CAN,数据传输速度最大可达到1
浅谈什么是语音芯片的白噪音支持功能:打造舒适家居与优质音频体验
随着科技的不断进步和人们对生活质量要求的提升,语音芯片已经成为了现代电子产品中不可或缺的一部分。而在这些语音芯片中,支持白噪音的功能逐渐受到人们的关注。本文将围绕语音芯片中的白噪音支持功能展开讨论,带您领略其带来的舒适家居与优质音频体验。 一、白噪音的定义与特点 首先,我们来了解一下白噪音。白噪音是指一段声音信号,其中包含了所有可听频率的声音,且每个频率的声音强度相等。它类似于自然界中的风声、
睡眠助手/白噪音/助眠夜曲微信小程序源码下载 附教程
睡眠助手/白噪音/助眠夜曲微信小程序源码 附教程 支持分享海报 支持暗黑模式 包含了音频数据 最近很火的助眠小程序,前端vue,可以打包H5,APP,小程序 后台可以设置流量主广告,非常不错的源码 代码完整 完美运营 搭配无人直播挺好的 源码下载:https://download.csdn.net/download/m0_66047725/88178635
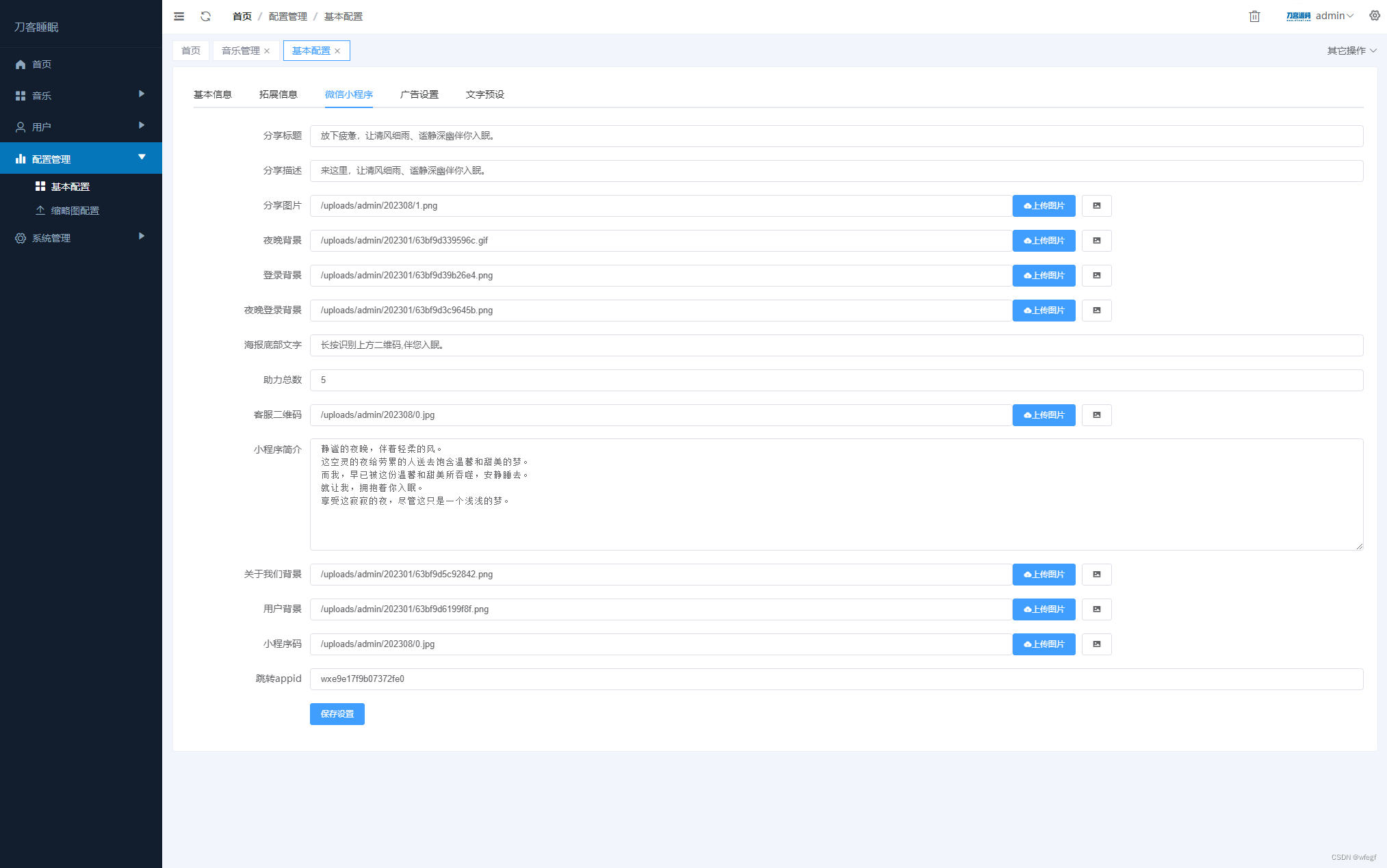
2023最新睡眠助手/白噪音/助眠夜曲小程序源码 附教程
正文: 最近很火的助眠小程序,前端vue,可以打包H5,APP,小程序 程序: wweojo.lanzouy.com/iqqg617f9rid 图片:
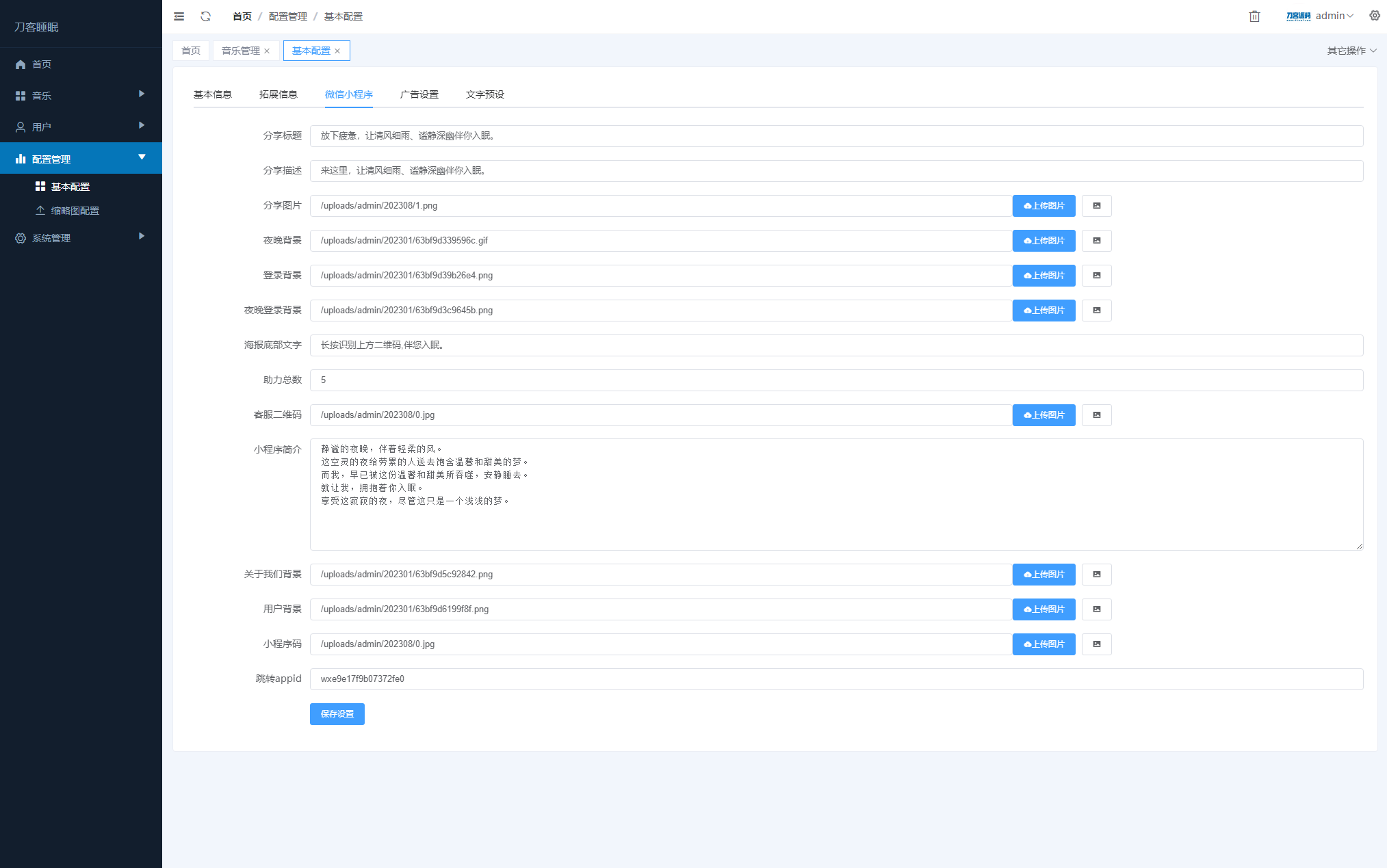
睡眠助手/白噪音/助眠夜曲微信小程序源码 附教程
简介: 睡眠助手/白噪音/助眠夜曲微信小程序源码 附教程 支持分享海报 支持暗黑模式 包含了音频数据 最近很火的助眠小程序,前端vue,可以打包H5,APP,小程序 后台可以设置流量主广告,非常不错的源码 代码完整 完美运营 搭配无人直播挺好的 具体请看下方演示小程序 图片:

图像数据噪音种类以及Python生成对应噪音
前言 当涉及到图像处理和计算机视觉任务时,噪音是一个不可忽视的因素。噪音可以由多种因素引起,如传感器误差、通信干扰、环境光线变化等。这些噪音会导致图像质量下降,从而影响到后续的图像分析和处理过程。因此,对于从图像中获取准确信息的应用,我们需要有效地处理这些噪音。在本篇讨论中,我们将深入探讨图像数据中常见的几种噪音类型,以及相应的处理方法,旨在提升图像处理任务的准确性和稳定性。 噪音种类

基于MCRA的语音噪音估计
Minima Controlled Recursive Averaging 噪音估计(MCRA) MCRA是由Israel Cohen在论文中提出的最小值追踪递归平均法,本文根据此论文总结如何来评估带噪语音中噪音部分,从而可以来做噪音消除任务。 输入信号的时域表示 带噪输入信号公式 y ( n ) = x ( n ) + d ( n ) y(n) = x(n) + d(n) y(n)=x(