本文主要是介绍消除噪音:Chain-of-Note (CoN) 强大的方法为您的 RAG 管道提供强大动力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:https://arxiv.org/abs/2311.09210
英文原文地址:https://praveengovindaraj.com/cutting-through-the-noise-chain-of-notes-con-robust-approach-to-super-power-your-rag-pipelines-0df5f1ce7952
在快速发展的人工智能和机器学习领域,出现了一种突破性的方法,显着增强了检索增强语言模型(RALM)的稳健性和可靠性。白皮书《Chain-of-Note (CoN): Enhancing Robustness in Retrieval-Augmented Language Models》深入探讨了这种新颖的方法。
引入注释链 (CoN)
为了应对这些挑战,本文引入了“Chain-of-Note”(CoN),这是一种旨在增强 RALM 稳健性的创新框架。CoN 的独特主张是为检索到的文档生成顺序阅读笔记,确保系统评估它们与输入问题的相关性。这种方法不仅评估每个文档的重要性,而且还确定最可靠的信息,从而提高准确性和上下文相关性。
白皮书 — https://arxiv.org/pdf/2311.09210.pdf
感谢这篇论文的作者,它确实是很好的工作
论文中描述的注释链(CoN)技术既可以应用于提示环境,也可以应用于准备语言模型的训练数据集。以下是它在每种情况下的使用方式:
提示: CoN 技术涉及在得出最终答案之前生成中间步骤或“阅读笔记”。这种方法可以集成到语言模型的提示策略中。当向模型提供复杂查询时,可以提示模型生成一系列注释,反映检索到的信息的相关性和详细信息,从而得出最终响应。这反映了思维链提示风格,鼓励模型“大声思考”并详细说明其思维过程,这已被证明可以提高其输出的质量和可靠性。
准备训练数据集:对于训练数据集,CoN 方法可用于通过添加表示模型推理过程的注释来增强数据集。通过创建不仅包括问题和答案,还包括解释为什么特定文档相关或不相关的中间阅读笔记的训练实例,模型可以学习更好地评估其检索到的信息的可信度和相关性。这种训练可能会改进模型处理噪声数据的方式以及在遇到训练范围之外的问题时的响应方式。
但本文明确提到了训练数据集的准备。
然后我脑子里快速闪过一个念头,如果它用在提示中CoT(思想链)和CoN有什么区别。
差异如下表所示
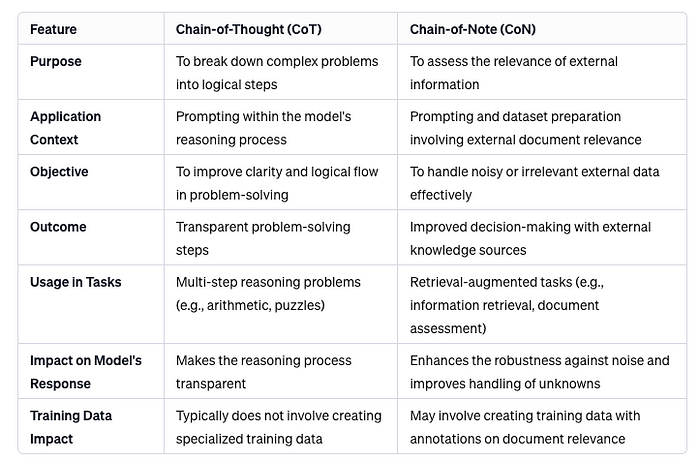
CoN 的力量:增强模型的能力
- 减少噪音:CoN 显着提高了模型过滤掉不相关或不太可信内容的能力,从而产生更精确的响应。
- 处理未知数:它使 RALM 能够在答案超出模型知识范围的情况下以“未知”进行响应,从而避免错误信息。
- 经验成功:在 LLaMa-2 7B 模型上实施 CoN 在开放域 QA 基准测试中显示出显着的改进,噪声环境中的 EM 分数平均提高了+7.9 ,实时问题的拒绝率平均提高了+10.5 。
培训与实施
该过程涉及使用 ChatGPT 生成 10K 训练数据,然后将其用于训练 LLaMa-2 7B 模型。这种方法不仅被证明具有成本效益,而且还增强了模型生成上下文丰富的阅读笔记的能力,同时保持对最终答案准确性的关注。
例子
法国的首都是什么?
检索到的文件#1:“巴黎以其咖啡馆和餐馆而闻名,它是法国人口最多的城市。”
检索到的文件#2:“里昂是法国一座历史文化名城,以其美食而闻名。”
标准 RALM 响应:可能会根据它认为更相关的文档错误地生成响应,或者如果它仅检索文档 #2,则可能会错误地回答“Lyon”。
方法:
- 关于文件 #1 的说明:该文件指出巴黎是法国人口最多的城市,众所周知,巴黎是法国的首都。
- 关于文件 #2 的说明:虽然里昂是法国的一个重要城市,但没有提及它是首都。
CoN 综合回应:考虑到注释,该模型正确地将巴黎识别为法国首都,因为文档 #1 提供了相关信息,而文档 #2 尽管提到了另一个主要城市,但与巴黎作为首都的地位并不矛盾。
让我们看一下 CoN 框架如何应用的示例:
- 相关 → 查找答案: CoN 识别直接回答查询的文档,并使用该信息制定最终响应。
- 不相关 → 推断答案:当文档不直接回答查询但提供上下文线索时,CoN 使用这些线索以及模型的固有知识来推断答案。
- 不相关→回答未知:如果检索到的文档不相关并且模型缺乏足够的信息来回答,CoN 会指导模型回答“未知”。
CoN 方法通过创建这些中间“阅读笔记”,使模型能够更好地滤除噪声、处理未知场景并提供更准确的答案。
影响和未来前景
CoN 的发展是寻求更可靠、更强大的人工智能系统的重大飞跃。通过增强 RALM 辨别和忽略不相关信息的能力,CoN 为 AI 响应的准确性设立了新标准。它的影响是巨大的,从改进搜索引擎和虚拟助手到数据分析和决策人工智能系统中更复杂的应用。
使用型号:
- ChatGPT:该模型用于为 CoN 框架创建训练数据。
- LLaMa-2 7B:论文提到使用 LLaMa-2 7B 与 CoN 框架进行训练。LLaMa(带有注意力的语言模型)很可能指的是大型语言模型,“7B”表示它拥有的参数数量,为 70 亿个。
使用的数据集:
- 自然问题 (NQ):NQ 数据集包含提交到 Google 搜索的真实用户查询,并在维基百科文章中找到答案。它专为自动问答系统的训练和评估而设计。该数据集包含 307,373 个训练示例、7,830 个开发示例和 7,842 个测试示例。NQ 的独特之处在于它使用自然出现的查询,并专注于通过阅读整个页面来寻找答案,而不是从简短的段落中提取答案。链接
- TriviaQA:该数据集是一个阅读理解数据集,包含超过 650,000 个问答证据三元组。它包括由问答爱好者创建的 95,000 个问答对以及独立收集的证据文档,平均每个问题有 6 个。这些文件为回答问题提供了高质量的远程监督。TriviaQA 的问题和答案是从维基百科和网络收集的,使其成为现实的基于文本的问答数据集。
- WebQuestions (WebQ):WebQuestions 数据集利用 Freebase 作为知识库,包含 6,642 个问答对。这些是通过 Google Suggest API 抓取问题然后使用 Amazon Mechanical Turk 获取答案而创建的。这些问题旨在由大型知识图 Freebase 来回答,并且主要围绕单个命名实体。
- RealTimeQA:RealTimeQA 是一个动态问答平台,每周定期公布和评估问题。该数据集关注当前世界事件和新颖信息,挑战传统开放域 QA 数据集的静态性质。它使用 GPT-3 和 T5 等大型预训练语言模型来构建基线模型。该数据集包括实时评估的 179 个 QA 对,以及为模型开发收集的额外 2,886 个 QA 对。RealTimeQA 强调人工智能模型中对最新信息检索的需求,因为据观察,当检索到的文档不足时,GPT-3 往往会返回过时的答案。
附录
- RALM:检索增强语言模型 - 通过集成外部知识源来增强传统语言模型的模型。
- LLMs:大型语言模型 - 能够理解和生成类人文本的高级人工智能模型。
- CoN:Chain-of-Note — 论文中介绍的用于提高 RALM 稳健性的新颖方法。
- EM 分数:精确匹配分数 — 一种用于评估模型响应准确性的指标,基于生成的答案与预期答案的精确匹配。
EM =(精确匹配数/问题总数)×100
在此公式中,“完全匹配”意味着模型的响应与问题的真实答案相同,总分表示为这些完全匹配占评估的总问题的百分比。
- DPR:密集段落检索 — RALM 中使用的一种技术,用于从大型语料库中检索相关文档或段落。
- NQ:自然问题 - 常用于训练和评估问答模型的数据集。
- QA:问答——人工智能的一个研究领域,专注于构建自动回答人类提出的问题的系统。
- IR:信息检索——从大型数据集中获取相关信息的过程。
- CoT:思想链——一种将复杂问题分解为一系列中间步骤以便更容易解决的方法。
- LLaMa-2 7B:LLaMa(大型语言模型)的特定模型,容量为 70 亿个参数。
- RR:拒绝率——用于评估模型正确拒绝超出其知识范围的问题的能力的指标。
- TriviaQA、WebQ、RealTimeQA:用于评估问答模型性能的特定数据集。
这篇关于消除噪音:Chain-of-Note (CoN) 强大的方法为您的 RAG 管道提供强大动力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







