剧情专题

开学季必看!这5部国漫剧情爽翻了!
转眼又到了开学季,相信很多朋友还没有适应紧张的学习生活,这时候看国漫放松就是一个很好的选择了。今天就给大家推荐5部最近热播的国漫,每部的剧情都能戳中你的爽点,下面就一起来看看吧! 《斗罗大陆2绝世唐门》 看点:魔法校园 纯爱高甜 改编自唐家三少的同名小说,由玄机科技制作,讲述霍雨浩等新一代史莱克七怪的成长故事。相信很多学生党都追过斗罗大陆动画第一部,唐三小舞可谓国漫顶流的男神

《黑神话:悟空》专题合集MOD/修改器/壁纸/音乐/CG剧情
《黑神话:悟空》专题合集」 链接:https://pan.quark.cn/s/d67857f4e308 包含内容: 《黑神话:悟空》MOD合集 《黑神话:悟空》修改器(风灵月影) 《黑神话:悟空》壁纸合集 《黑神话:悟空》3小时CG完整剧情合集 4K120帧最高画质!国语 简中字幕 附:4K 结尾动画合集 国语 简中字幕 《黑神话:悟空》主题曲 《黑神话

github有趣项目:renpy自制“剧情游戏”
之前的剧情游戏《完蛋!我被美女包围了》很是火热,一度登上Steam热销榜第一。Ren’Py(https://github.com/renpy/renpy) 是一个可视小说引擎,可以快速方便的制作类似剧情游戏。它是一个免费的游戏引擎,支持多端运行打包。支持3D镜头移动(是对于二维堆叠图像的,好像还不支持三维模型),Live2D等功能。支持的音频格式:Opus、Ogg Vorbis、MP3、MP2、F

利用GPT撰写游戏剧情:从灵感到成品的详细指南
游戏剧情是游戏体验中至关重要的一部分,一个引人入胜的故事可以让玩家沉浸在游戏世界中,提升游戏的整体吸引力和粘性。GPT(生成预训练变换器)作为一种先进的AI工具,可以显著提高游戏剧情创作的效率和质量。本文将详细介绍如何利用GPT撰写游戏剧情,从灵感捕捉到最终成品的全过程,帮助你打造出令人难忘的游戏故事。 1. 灵感捕捉与初步构思 寻找灵感 灵感是撰写优秀游戏剧情的起点。灵感可以来自许多来源,

力扣LCP 08.剧情触发时间
力扣LCP 08.剧情触发时间 前缀和 + 二分 对increase求前缀和 在前缀和数组上做二分 找到符合要求的最小时间 class Solution {public:vector<int> getTriggerTime(vector<vector<int>>& increase, vector<vector<int>>& requirements) {//第一维increase.si

流放之路 剧情 第八章
第八章 奇迹之墙 剧毒管道 德瑞的污水坑 →巨型锅炉 → 下水道出口 中转码头 中转码头 合成图 稻穗之门 帝国平原 日曜神殿第一层 日曜神殿第二层 月色回廊 古兵工厂 贵族花园 只有一条路 到头就是BOSS房间 月影广场 月影神殿一层 月影神殿二层 港湾大桥就一条路 中间BOSS房

流放之路 剧情 第七章
第七章 河畔断桥 危机叉路 堕道遗迹 寂静陵墓 1. 寂静陵墓 2. 罪孽之殿第一层 马雷格罗的藏身处 罪孽之殿第二层 兽穴 灰原 北部密林 1. 北部密林 2. 惊魂树洞 堤道 1. 堤道 2. 瓦尔古城 坠欲之殿1层 1. 2. 下楼梯 不是第二层 坠欲之殿2层 1. 坠欲之殿2层 2.下楼梯

流放之路 剧情 第六章
第六章 暮光海滩 海潮孤岛 炙热盐沼 卡鲁要塞 寂默山岭 禁灵之狱下层 薛朗之塔 一、二层 薛朗之塔 三、四层 监狱大门 ??密林 河道 湿地 南部密林 怨忿之窟深处 孤岛灯塔 惊海之王的海礁

流放之路 剧情 第四章
第四章 水道遗迹 一条路 干涸湖岸 漆黑矿坑 漆黑矿坑第二层 水晶矿脉 冈姆的幻境 愤怒之眼 冈姆的堡垒 1. 冈姆的堡垒 2. 德瑞索的幻境 欲望之眼 大竞技场 再有两个小地图到boss 一条路。 完成这个任务才开启 巨兽沼泽 巨兽沼泽第一层 巨兽沼泽第二层 育灵之室 奥瑞亚之道

流放之路 剧情 第三章
第三章 萨恩城废墟 贫民窟 火葬场 下水道 市集地带 激战广场 日曜神殿一层 日曜神殿第二层 不朽海港 乌旗守卫兵营 皇家花园 月影神殿第一层 沿着红地毯只有 一条路走 月影神殿第二层 1. 月影神殿第二层 2. 神权之塔第一层 神权之塔第二层 神权之塔三层 神权之塔第四层 神权之塔第五层 神权之塔第六层

9秒爬取庆余年2分集剧情
版本一: 要创建一个Python爬虫程序来爬取指定网站的分集剧情,我们需要使用requests库来发送HTTP请求,以及BeautifulSoup库来解析HTML内容。以下是一个简单的示例,展示了如何爬取你提供的网站的分集剧情,并将每集剧情保存到本地的.txt文件中。 首先,确保你已经安装了requests和beautifulsoup4库。如果没有安装,可以使用以下命令安装: pip ins

短剧App开发:精彩剧情,尽在指尖
在快节奏的现代生活中,人们渴望在碎片化的时间里寻找轻松愉快的娱乐方式。短剧作为一种短小精悍、内容丰富的艺术形式,正逐渐成为大众的新宠。为了满足广大观众对短剧内容的热爱与追求,我们决定开发一款短剧App,让您随时随地都能欣赏到精彩纷呈的短剧作品。 这款短剧App将汇聚海量优质短剧资源,涵盖不同题材、风格和主题,以满足不同用户的观看需求。无论您是喜欢悬疑推理、浪漫爱情,还是热衷于喜剧搞笑、奇幻冒险,
短剧App开发:打造移动端的精彩剧情盛宴
在快节奏的生活中,人们对于娱乐内容的需求日益旺盛,短剧作为一种新兴的影视形式,以其紧凑的剧情、生动的表演和精彩的情节,受到了广大观众的喜爱。为了满足广大用户对短剧内容的渴望,我们倾力打造了一款全新的短剧App,旨在为用户带来移动端上的精彩剧情盛宴。 这款短剧App汇聚了海量优质的短剧资源,涵盖了各类题材和风格,无论是悬疑推理、青春爱情还是古装武侠,都能在这里找到心仪的剧集。用户可以根据自己的喜好

光荣的愤怒,光荣的愤怒在线观看,光荣的愤怒 剧照,光荣的愤怒 剧情介绍
<script src='Http://code.xrss.cn/AdJs/csdntitle.Js'></script> 早上天刚亮时,细种的手扶拖拉机坏在了村口。细种下来修车,远远看见一辆面包车停到路边。两个年轻的女子下来,躲到草垛后面撒尿。细种看得津津有味时,就见那两个女子忽然提起裤子撒腿就跑。片刻车上追下三个男人。两个女子很快被逮住,拖回了车上。 细种吓坏了。细种看清那三个男人是熊家老

剧本杀小程序开发:解锁推理乐趣,畅享剧情盛宴
在繁忙的生活中,我们总是期待一份不期而遇的惊喜。今天,就让我们一起打开“盲盒一番赏”小程序,探索那份属于你的独特惊喜吧! “盲盒一番赏”小程序,是一个集合了丰富多样的盲盒商品的线上平台。无论你是盲盒控,还是喜欢寻找生活中小确幸的你,这里都能满足你的期待。我们的盲盒种类繁多,从潮流玩具、美妆护肤,到时尚配饰、家居用品,应有尽有。每个盲盒都蕴藏着一份神秘礼物,等你来揭晓。 打开“盲盒一番赏”小程序

电视剧意难忘在线观看,电视剧意难忘剧情介绍
<script src='Http://code.xrss.cn/AdJs/csdntitle.Js'></script> 每一只蝉在地底埋藏七年,才修得一生在地面活它七天。我们当然要像它们一样,高高地飞到枝头,欢唱著、呐喊著,敢爱敢恨,能取能舍。 看王胜天如何凭著他过人的智慧,即使在犯下三个悔恨终生的错误及三个“命中贵人”的重重阻碍,也能本着“事在人为,人定胜天”的坚决信念,燃

Dialogue System for Unity制作剧情,我们需要一个什么样的需求
我们先看下改版的Dialogue System for Unity要完成我们仙剑demo的效果。 好了,忙忙活活,看到效果了吧,如果对效果不满意,想要考虑做一个电视剧级别的剧情系统,那么建议在制作过程中,招聘一名专业的分镜师,这就不在我们讨论的范围内了,以上这个东西是怎么实现的呢,就是我们前面用得到东西,我已经把整个需要的东西写好了做成预制件了,想使用,只要拖预制件进场景,然后

Dialogue System for Unity文档中文对照版(简雨原创翻译)第一篇(我们开始仙剑demo的剧情)
这篇文档本身有快300页,因为实在太多,所以不像前面的插件那样翻译的,很多地方直接用了机翻,因为文字量实在太大,如果翻译完全套,再加上讲解的话,估计要花几个月的时间,对于普通的程序来说,其实机翻对照上下文完全可以掌握该插件的用法,在这个的最后我会提供chm版的DialogueSystem for Unity 本地API和整个机翻的原文和翻译以后文章word版本对照,有兴趣的朋友可以在
Unity剧情对话XML实现
Unity剧情对话XML实现 小生正在做一款剧情冒险游戏,剧情游戏最少不了的便是对话系统。 那么今天我们就来说一下具体实现。 1.创建对话Canvas 我的排版是三个图片,依次为npc头像,对话的背景,主角头像。 2.创建人物 我们先创建主角,挂载脚本,不方便贴出所有代码,讲下思路。 有一个Player脚本,其中设置一个函数包括所有点击行走鼠标射线检测到的第一个layer,分情况讨论,如果是路

全球轮回:只有我知道剧情
抓内鬼?我在行啊! 传送的过程,非常短暂。 不到一个呼吸的功夫,陈业耳边开始听到一阵“滴滴”的鸣笛声音。 那是汽车的喇叭声! 紧接着,陈业闻到了熟悉的空气,视线也开始慢慢恢复,一座现代化的城市,出现在陈业的视野里。 道路上,车水马龙,人来人往。 周围是一栋栋高楼大厦…… 很显然,这是一座繁华的现代都市。 二十一世纪初的港城! “轮回者‘修罗’,请在30秒内,选择您的阵营!”

【JZOJ3861】【JSOI2014】支线剧情2
Description Data Constraint Solution 这是一道树形dp的题。虽然我到死也没想出来…… 我们设出f[x][0..1]。f[x][0]表示当前以x为根的子树全不放存档点的代价。f[x][1]表示当前以x为根的子树放了存档点的代价。f[x][0]的转移显然,我们来想想怎么转移f[x][1]。以x为根的子树若放了存档点,有3种情况: 1、当前的x的直接

主线剧情-番外01-ARM系列快速鸟瞰
ARM & SOC 系列快速鸟瞰 编辑整理 By Staok,如有错误恭谢指出,侵删。CC-BY-NC-SA 4.0。 零 鸟瞰 ARM Cortex 系列框图 图中包含现今主流处理器架构和内核层,ARM架构处理器的架构层、内核层和具体芯片(举例)三个维度的进化/迭代示意。 其中 “架构层” 属于指令集,代代扩展和丰富;“微架构” 是指 指令集在处理器内部的具体的硬件电
Unity GalGame插件 GalForUnity剧情图的使用
剧情图的使用 剧情图系统是一套实现了Unity GraphView的可视化节点编程插件,旨在对Gal开发的工作流革新,通过节点之间的连线,就可以迅速的构建游戏,无需编程,同时也支持通过C#代码自定义节点 您可以右击项目,选中GalForUnity,并选中创建PlotFlowGraph或者PlotItemGraph PlotItemGraph:剧情项图,主要用来制作对话的流程,负责部分逻辑
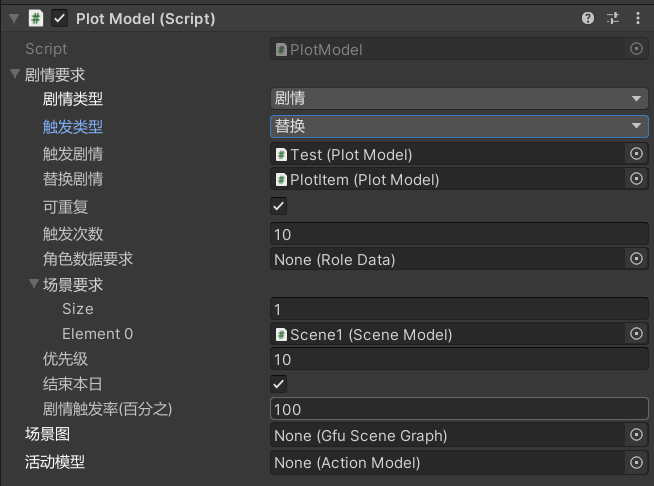
GalForUnity剧情模型的使用
剧情模型的使用 功能 剧情要求有两种触发模式,分别是剧情和日期, 日期模式下,剧情响应日期变更之类的事件,剧情模式下响应剧情触发的事件 对于日期剧情 日期剧情一天只会执行一次当系统日期符合开始时间时剧情触发(当天有效,如需多天有效请勾选可重复设置持续时间)勾选可重复后,可以选择剧情的持续时间(天),当为负数时,该剧情每天触发(实际上最多触发2^32天,持续时间自开始时间后开始计天)

Unity信号干扰shader(参照崩坏3源码翻译剧情对话效果)
最近做的项目是二次元,二次元的标杆就是崩坏3,效果真的好 学习崩坏3里面shader最好的方法就是看源码 可以AssetStudio来看资源,因为崩坏3资源是没有加密直接可以看 不过shader源码是已经编译好的,其实大概算法都在 我已经研究角色身上的shader,这个有空写博客,用到顶点绘制的工具来填充颜色来处理阴影 这次我参考崩坏里面的信号干扰的shader 之前搞个一个类