分库专题

MySQL大表数据的分区与分库分表的实现
《MySQL大表数据的分区与分库分表的实现》数据库的分区和分库分表是两种常用的技术方案,本文主要介绍了MySQL大表数据的分区与分库分表的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有... 目录1. mysql大表数据的分区1.1 什么是分区?1.2 分区的类型1.3 分区的优点1.4 分

Mycat搭建分库分表方式
《Mycat搭建分库分表方式》文章介绍了如何使用分库分表架构来解决单表数据量过大带来的性能和存储容量限制的问题,通过在一对主从复制节点上配置数据源,并使用分片算法将数据分配到不同的数据库表中,可以有效... 目录分库分表解决的问题分库分表架构添加数据验证结果 总结分库分表解决的问题单表数据量过大带来的性能
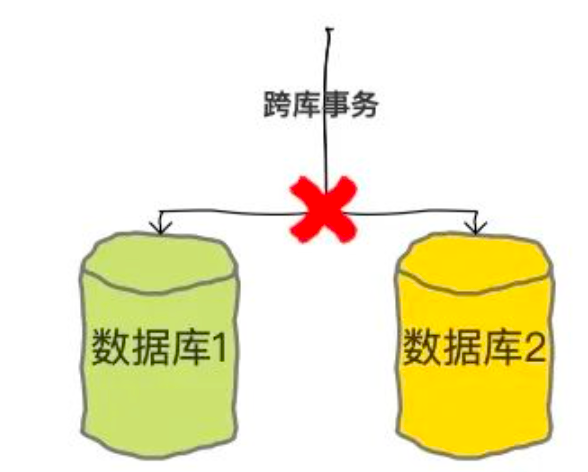

基于shard-jdbc中间件,实现数据分库分表
一、水平分割 1、水平分库 1)、概念: 以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中。 2)、结果 每个库的结构都一样;数据都不一样; 所有库的并集是全量数据; 2、水平分表 1)、概念 以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中。 2)、结果 每个表的结构都一样;数据都不一样; 所有表的并集是全量数据; 二、Shard-jdbc 中间件 1、架构图 2、特点

基于Shard-Jdbc分库分表,数据库扩容方案
一、数据库扩容 1、业务场景 互联网项目中有很多“数据量大,业务复杂度高,需要分库分表”的业务场景。 这样分层的架构 (1)上层是业务层biz,实现业务逻辑封装; (2)中间是服务层service,封装数据访问; (3)下层是数据层db,存储业务数据; 2、扩容场景和问题 当数据量持续新增,面临着这样一些需求,两台数据库无法容纳,需要数据库扩容,这里选择2台—扩容到3台的模式,如下图

分库分表:应对大数据量挑战的数据库扩展策略
随着互联网技术的发展,数据量的爆炸性增长给数据库系统带来了前所未有的挑战。为了有效管理大规模数据并保持高性能,分库分表成为了一种常见的数据库扩展策略。本文将探讨分库分表的概念、动机、实施策略以及潜在的挑战和解决方案。 什么是分库分表? 分库分表是一种数据库架构设计策略,它将数据分散存储在多个数据库(分库)和多个表(分表)中。这种方法可以提高数据库的可伸缩性、可用性和性能。 为什么需要分库分表

一文读懂数据库分库分表
阅读此文你将了解: 什么是分库分表以及为什么分库分表如何分库分表分库分表常见几种方式以及优缺点如何选择分库分表的方式 数据库常见优化方案 对于后端程序员来说,绕不开数据库的使用与方案选型,那么随着业务规模的逐渐扩大,其对于存储的使用上也需要随之进行升级和优化。 随着规模的扩大,数据库面临如下问题: 读压力:并发QPS、索引不合理、SQL语句不合理、锁粒度写压力:并发QPS、事务、锁粒

强!分库分表与分布式数据库技术选项分析
点击上方“朱小厮的博客”,选择“设为星标” 后台回复"1024"领取公众号专属资料 来源:rrd.me/gEhKy 最近经常被问到分库分表与分布式数据库如何选择,网上也有很多关于中间件+传统关系数据库(分库分表)与NewSQL分布式数据库的文章,但有些观点与判断是我觉得是偏激的,脱离环境去评价方案好坏其实有失公允。 本文通过对两种模式关键特性实现原理对比,希望可以尽可能客观、中立的阐明各自真实

阿里面试题:分库分表无限扩容后的瓶颈以及解决方案
点击上方“朱小厮的博客”,选择“设为星标” 后台回复"书",获取 后台回复“k8s”,可领取k8s资料 前言 像我这样的菜鸟,总会有各种疑问,刚开始是对 JDK API 的疑问,对 NIO 的疑问,对 JVM 的疑问,当工作几年后,对服务的可用性,可扩展性也有了新的疑问,什么疑问呢?其实是老生常谈的话题:服务的扩容问题。 正常情况下的服务演化之路 让我们从最初开始。 单体应用 每个创业公司基本都
Sharding-JDBC教程:Spring Boot整合Sharding-JDBC实现分库分表+读写分离
在上一篇文章介绍了如何使用Sharding-jdbc进行分库+读写分离,这篇文章将讲述如何使用Sharding-jdbc进行分库分表+读写分离。 架构回顾 在数据量不是很多的情况下,我们可以将数据库进行读写分离,以应对高并发的需求,通过水平扩展从库,来缓解查询的压力。如下: 在数据量达到500万的时候,这时数据量预估千万级别,我们可以将数据进行分表存储。 在数据量继续扩大,这时可以考虑分库分

实现对MySQL数据库进行分库/分表备份(shell脚本)
工作中,往往数据库备份是件非常重要的事情,毕竟数据就是金钱,就是生命!废话不多,下面介绍一下:如何实现对MySQL数据库进行分库备份(shell脚本) Mysq数据库dump备份/还原语法: mysqldump -u 用户名 –p 数据库名 > 导出的文件名; mysqldump -u 用户名 –p 数据库名 < 导入的文件名; 首先,我们需要知道是备份全库还是部分库; 其次,我们需要获取到需要

【实战总结】分库路由字段与业务字段绑定落库
目录 问题背景 常见的解决方案 方案1:Hbase+ES 方案2:MQ异步绑定 问题背景 我们一般分库分表的路由字段是用户的账户ID(userId),有些业务场景外部不以此做业务,而是以业务请求ID等进行业务交互 所以我们内部系统通过userId来串联业务关系,但是与外部交互要使用到bizId等这些代表业务唯一性的字段,这两个字段不同路由可能会打到不同的库是没办法做数据库事务处理
数据库:分库分表——哈希的作用与原理
数据库:分库分表——哈希的作用与原理 在分布式数据库系统中,随着业务的增长和数据量的增加,分库分表成为一种常见的解决方案。分库分表可以有效地提升系统的扩展性和性能,而在这一过程中,哈希函数和一致性哈希算法起到了核心作用。本文将详细探讨哈希的基本概念、在分库分表中的作用,以及它们的原理和应用场景。 文章目录 数据库:分库分表——哈希的作用与原理摘要一、哈希的基本概念二、在分库分表

分库分表学习笔记(二)
分库分表学习笔记(一)-CSDN博客 分表分库规则 图源(https://zhuanlan.zhihu.com/p/535713197) 水平分表 水平分表一般是我们数据库的数据太多了,原大众点评的订单单表早就已经突破两百G。 数据量太多的影响 1. 查询性能下降:随着数据量的增加,查询的响应时间可能会显著增加,
分库分表之后怎么进行join操作?
目录 一、应用层join 二、使用数据库中间件 三、数据冗余 四、搜索引擎 在我们做了分库分表之后,数据会散落在不同的数据库中,这时候在需要进行跨库或跨表的JOIN操作时,就会比较麻烦。 如果数据被分表后,分散在不同的数据库上面,那么标准的join是要在单库内执行的,所以这就会带来复杂性。还有就是不同的库可能在不同的服务器上面,那么一次join就需要和多个数据库交互,那就会有更
Java项目中的分库分表实践指南
摘要 随着互联网应用的快速发展,单一数据库实例越来越难以满足高并发和大数据量的需求。分库分表是一种有效的解决方案,它通过将数据分散存储到不同的数据库或表中来提高系统的扩展性和性能。本文将详细介绍Java项目中实现分库分表的策略、步骤和最佳实践。 1. 分库分表的概念 分库:将数据按照某种规则分散存储到多个数据库实例中。分表:将数据按照某种规则分散存储到同一个数据库中的多个表中。 2. 分库

分库分表学习笔记(一)
图源(鹅厂技术架构师公众号) MySQL执行顺序: FROM:确定数据来源。JOIN:执行表之间的连接操作。WHERE:过滤记录。GROUP BY:对记录进行分组。HAVING:对分组结果进行过滤。SELECT:选择要返回的列。DISTINCT:去除重复记录(如果有)。ORDER BY:

分库分表问题汇总---更新中
分布式全局唯一ID 往往直接使用数据库自增特性来生成主键ID,而在分库分表的环境中,数据分布在不同的分片上,不能再借助数据库自增长特性直接生成,否则会造成不同分片上的数据表主键会重复。 Twitter的Snowflake(又名“雪花算法”) UUID/GUID(一般应用程序和数据库均支持) MongoDB ObjectID(类似UUID的方式) Ticket Server(数据库生存方式
mycat水平分库-对用户id取模
schema.xml: <?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" ><table name=
大数据技术之_29_MySQL 高級面试重点串讲_02_Mysql简介+Linux 版的安装+逻辑架构介绍+性能优化+性能分析+查询截取分析+分区分库分表简介+Mysql锁机制+Mysql主从复制
大数据技术之_29_MySQL 高級面试重点串讲_02 第1章 Mysql 简介1.1 概述1.2 高级 MySQL 第2章 Mysql Linux 版的安装2.1 下载地址2.2 检查当前系统是否安装过 mysql2.3 修改 Mysql 配置文件位置2.4 修改字符集和数据存储路径2.5 MySQL 的安装位置说明2.6 Mysql 配置文件说明2.7 Mysql 的数据存放目录 第3章

数据库分库分表(sharding)---全局主键生成策略
第一部分:一些常见的主键生成策略 一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由。目前几种可行的主键生成策略有: 1. UUID:使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外
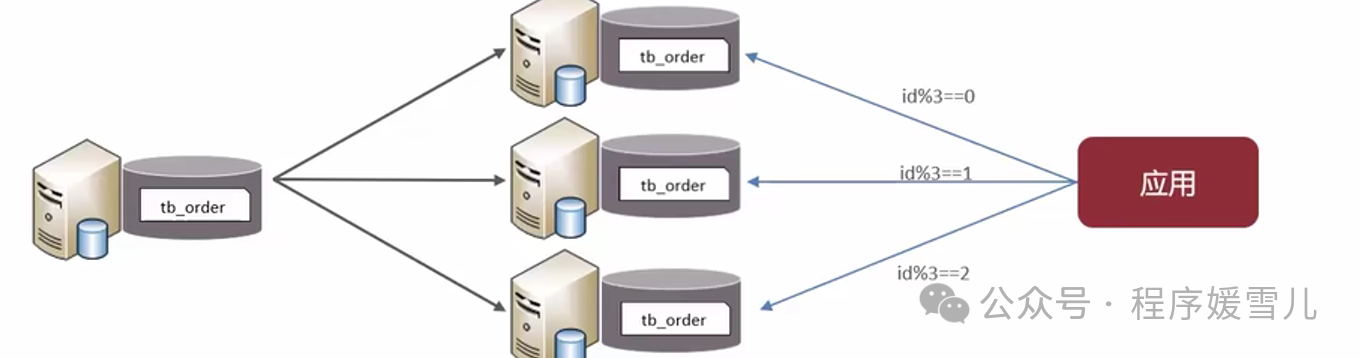
mysql分库分表,包含概念+具体实操,很细节~
大家好,我是程序媛雪儿,今天咱们唠唠mysql分库分表。 是什么 mysql分库分表主要是为了应对数据量或访问量过大而导致单个数据库或单个表的性能瓶颈而采取的一种数据库架构设计。通过将数据分布到多个数据库或表中,能有效地提升数据库的性能,提高并发处理能力,减少单点故障的风险。 上面这个解释是文邹邹的官方解释,其实总的来看,这个概念有以下几个点 1、

MySQ分库分表与MyCat安装配置
目录 介绍 拆分策略 垂直拆分 1. 垂直分库 2. 垂直分表 水平拆分 1. 水平分库‘ 2. 水平分表 实现技术 MyCat概述 安装 概念介绍 MyCat入门 需求 环境准备 分片配置 启动服务 连接测试 执行SQL语句测试 MyCat配置 1. schema.xml 1. schema标签 2. datanode标签 3. datahos
Sharding(切片)技术(解决数据库分库一致性问题)
Sharding(切片) 不是一门新技术,而是一个相对简朴的软件理念,就是当我们的数据库单机无法承受高强度的i/o时,我们就考虑利用 sharding 来把这种读写压力分散到各个主机上去。 所以Sharding 不是一个某个特定数据库软件附属的功能,而是在具体技术细节之上的抽象处理,是Horizontal Partitioning 水平扩展(或横向扩展)的解决方案,其主要目的是为突破单节点数