分区表专题

PostgreSQL分区表(partitioning)应用实例详解
https://www.jb51.net/article/97937.htm PostgreSQL分区表(partitioning)应用实例详解 更新时间:2016年11月22日 10:25:58 作者:小灯光环 我要评论 这篇文章主要为大家详细介绍了PostgreSQL分区表(partitioning)应用实例,具有一定的参考价值,感兴趣的小伙伴们可以参考一下

【硬刚Hive】Hive面试题(3):如何用sqoop将hive中分区表的分区字段导入到MySQL中
问题分析: 1.hive中分区表其底层就是HDFS中的多个目录下的单个文件,hive导出数据本质是将HDFS中的文件导出 2.hive中的分区表,因为分区字段(静态分区)不在文件中,所以在sqoop导出的时候,无法将分区字段进行直接导出 思路:在hive中创建一个临时表,将分区表复制过去后分区字段转换为普通字段,然后再用sqoop将tmp表导出即实现需求 步凑如下: 1.创建目标表(
PostgreSQL分区表原理、案例的灵活应用
PostgreSQL分区表的灵活应用 通常情况下,扫描一个大表会很慢,需要扫描整张表格,如果能够把大表分拆成小表,查询数据的时猴,只扫描数据所属的小表,就能大大降低扫描时间,提高查询速度。 1、简介 PostgreSQL10之前的版本不支持内置分区表,若要实现分区功能,需通过继承的方式实现。 PostgreSQL 10.x 之前的版本提供了一种“手动”方式使用分区表的方式,需要使用继承 +

关于PostgreSQL的分区表的历史及分区裁剪参数enable_partition_pruning与constraint_exclusion的区别
1. 疑惑 我们知道控制分区裁剪的参数有两个: enable_partition_pruningconstraint_exclusion 这两个参数有什么区别呢? 2. 解答 要说明这两个参数的区别需要先讲一讲PostgreSQL数据库中分区的历史,在PostgreSQL 10版本之前,PostgreSQL数据库实际上是没有单独的创建分区表的DDL语句,都是通过表继承的原理来创建分区表,
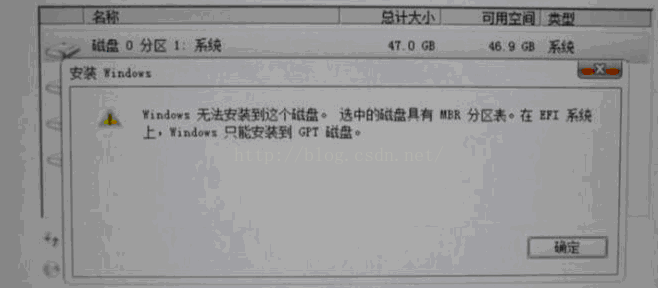
windows 无法安装到这个磁盘,选中的磁盘具有MBR分区表。在EFI系统上,windows只能安装在GPT磁盘上
问题: 今天下午路过李芬在装固态硬盘,遇到了一个棘手的问题。在选择安装分区的时候,提示有这样的错误。 Windows 无法安装到这个磁盘。选中的磁盘具有MBR分区表。在 EFI 系统上,Windows 只能安装到 GPT 磁盘。 解决方案一: 之前遇到这样过这样的错误。立马就想到了解决方案,但解决方法虽然能解决安装问题。但有些缺陷,就是必须把硬盘中所有的分区都


【MySQL、Hive】分区表
SQL 本身并不直接支持多线程处理,因为 SQL 是一种声明式语言,主要用于定义和操作数据库中的数据。多线程通常是在应用程序层面实现的。然而,有一些方法可以在 SQL 环境中优化并发处理和提高性能,这些方法在某种程度上可以被视为"多线程"的替代方案。 分区表查询(MySQL): 使用partition by方案,把数据分成按年度的小芬,查询时只从特定分区表中检索数据,提升效率。 CREATE

大数据技术之_08_Hive学习_02_DDL数据定义(创建/查询/修改/删除数据库+创建表+分区表+修改表+删除表)+DML数据操作(数据导入+数据导出+清除表中数据)
大数据技术之_08_Hive学习_02 第4章 DDL数据定义4.1 创建数据库4.2 查询数据库4.2.1 显示数据库4.2.2 查看数据库详情4.3.3 切换当前数据库 4.3 修改数据库4.4 删除数据库4.5 创建表4.5.1 管理表(内部表)4.5.2 外部表4.5.3 管理表与外部表的互相转换 4.6 分区表4.6.1 分区表基本操作4.6.2 分区表注意事项 4.7 修改表4.

查看U盘的具体信息,分区表格式、实际容量和分区状态
查看U盘的具体信息,分区表格式、实际容量和分区状态 前言: 利用windows自带的命令行窗口就可以 1、使用命令提示符查看MBR和GPT分区类型 (1)按“Windows + R”键,在弹出的运行对话框中输入“diskpart”,并按回车键启动diskpart实用程序 (2)输入“list disk”命令,然后按回车,查看磁盘信息 (3)在命令行中的“Gpt”列下方,带有一个星号(
MySQL键分区分区表
什么是键分区分区表? 键分区是一种MySQL数据库中的分区策略,它基于某个列的键值将数据分割成不同的分区。每个键值都会被映射到一个唯一的分区,这样可以确保数据在不同分区中均匀分布。键分区广泛应用于MySQL Cluster环境中,它可以提供高可用性、可伸缩性和容错性。 如何创建键分区分区表? 创建键分区分区表需要以下几个步骤: 1. 设计分区键:首先,需要选择一个适合的列作为分区键。分区键
创建分区表,以及将数据写入分区表
创建分区表 CREATE TABLE 表名(`字段1` string,`字段2` int) partitioned by(分区字段 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; 例子 CREATE TABLE my_table(`id` string,`cnt` int) partitioned by(date stri
数据库-表、索引、触发器、分区表、查询语句使用注意事项
文章目录 普通表、数据类型索引触发器分区表查询语句DML 普通表、数据类型 联机交易事务的表字段个数不超过个数N个(n<50?)批量业务表字段个数不超过500个。原因:单标字段个数越多,查询性能越差。不应使用浮点型数据类型存放金额,应使用整数型多表关联时,表示同一涵义的字段应使用相同的数据类型。原因:避免隐式转换。 索引 索引中所有字段长度合计不得超过2704字节。原因:B树
StarRocks分区表历史数据删除与管理
一、背景介绍 在使用 StarRocks 时,可能会遇到需要删除大批量数据的情况。然而,StarRocks 对 DELETE 操作的支持并不理想,主要存在以下问题: 不建议执行高频的 DELETE 操作:删除的数据会标记为“Deleted”,暂时保留在 Segment 中,不会立即进行物理删除。Compaction(数据版本合并)完成之后会被回收。查询效率可能降低:执行 DELETE 语句后,

MaxCompute查看分区表某个分区生成时间
查看分区信息 查看某个分区表具体的分区的信息。 命令格式 desc <table_name> partition (<pt_spec>); 参数说明 table_name:必填。待查看分区信息的分区表名称。pt_spec:必填。待查看的分区信息。格式为partition_col1=col1_value1, partition_col2=col2_value1...。对于有多级分区的表,必须指明
普通表在线重定义为分区表
普通表在线转换成分区表示例 源表表结构如下: CREATE TABLE EDC_SEPERATOR ( SEPERATOR_ID NUMBER(15) NOT NULL, EQUIPMENTINFO NVARCHAR2(20), RECORD NVARCHAR2(50), TITLE NVARCHAR2(50), ID
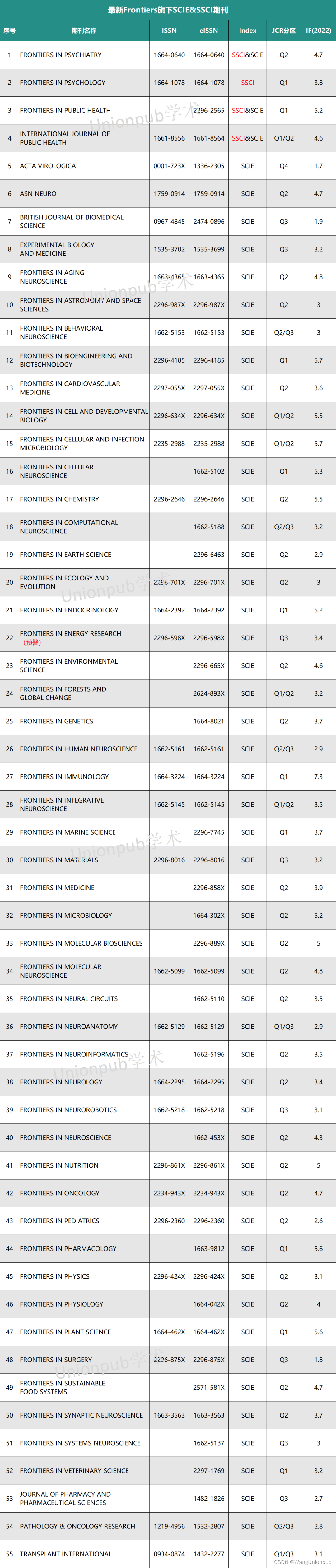
Frontiers旗下期刊,23年分区表整理出炉!它还值得投吗?
本周投稿推荐 SSCI • 中科院2区,6.0-7.0(录用友好) EI • 各领域沾边均可(2天录用) CNKI • 7天录用-检索(急录友好) SCI&EI • 4区生物医学类,0.5-1.0(录用率99%) • 1区工程类,6.0-7.0(进展超顺) • IEEE(TOP),7.5-8.0(实力强刊) Frontiers旗下的期刊曾被冠以“水刊”的名声,其开源发表形

MySQL普通表转换为分区表实战指南
码到三十五 : 个人主页 引言 本文将详细指导新手开发者如何将MySQL中的普通表转换为分区表。分区表在处理庞大数据集时展现出显著的性能优势,不仅能大幅提升查询速度,还能有效简化数据维护工作。通过掌握这一技巧能够更好地应对数据密集型应用带来的挑战,为系统的高效运行奠定坚实基础。 目录 引言步骤 1: 备份原始数据步骤 2: 修改表结构以包含分区键在主键中步骤 3. 修改
opengauss创建和管理分区表
创建和管理分区表 背景信息 openGauss数据库支持的分区表为范围分区表、列表分区表、哈希分区表。 范围分区表:将数据基于范围映射到每一个分区,这个范围是由创建分区表时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期,例如将销售数据按照月份进行分区。列表分区表:将数据中包含的键值分别存储在不同的分区中,依次将数据映射到每一个分区,分区中包含的键值由创建分区表时指定。哈希
PostgreSQL分区表(partitioning)应用实例
前言 项目中有需求要垂直分表,即按照时间区间将数据拆分到n个表中,PostgreSQL提供了分区表的功能。分区表实际上是把逻辑上的一个大表分割成物理上的几小块,提供了很多好处,比如: 查询性能大幅提升删除历史数据更快可将不常用的历史数据使用表空间技术转移到低成本的存储介质上 那么什么时候该使用分区表呢?官方给出的指导意见是:当表的大小超过了数据库服务器的物理内存大小则应当使用分区表,接
kudu-impala分区表(hash和range分区)
展开 1、分区表支持hash分区和range分区,根据主键列上的分区模式将table划分为 tablets 。每个 tablet 由至少一台 tablet server提供。理想情况下,一张table分成多个tablets分布在不同的tablet servers ,以最大化并行操作。 2、Kudu目前没有在创建表之后拆分或合并 tablets 的机制。 3、创建表时,必须为表提供分区模式。
你了解MySQL分区表吗?知道哪些情况不适用分区表吗?
一、分区表的使用 简单来说,分区表就是把物理表结构相同的几张表,通过一定算法,组成一张逻辑大表。这种算法叫“分区函数”,当前 MySQL 数据库支持的分区函数类型有 RANGE、LIST、HASH、KEY、COLUMNS。 无论选择哪种分区函数,都要指定相关列成为分区算法的输入条件,这些列就叫“分区列”。另外,在 MySQL 分区表中,主键也必须是分区列的一部分,不然创建分区表时会失败,比如:

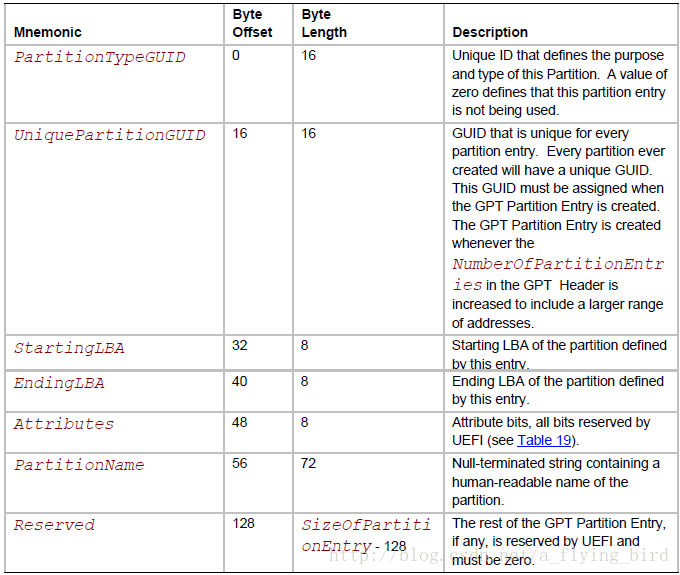
GUID(GPT)分区表详解
保护MBR 保护MBR包含一个DOS分区表(LBA0),只包含一个类型值为0xEE的分区项,在小于2TB的磁盘上,大小为整个磁盘;在更大的磁盘上,它的大小固定为2TB。它的作用是阻止不能识别GPT分区的磁盘工具试图对其进行格式化等操作,所以该扇区被称为“保护MBR”。实际上,EFI根本不使用这个分区表。 EFI部分 EFI部分又可以分为4个区域:EFI信息区(GPT头)、分区表、G
SQL SERVER分区表的创建和维护实例
SQL SERVER分区表的创建和维护实例 阅读目录 提出问题解决问题 在日常工作中,我们会遇到以下的情况,一个表每日数万级的增长,而查询的数据通常是在本月或今年,以前的数据偶尔会用到,但查询和插入的效率越来越慢,用数据库分区会有助于解决这个问题。关于分区的理论知识网上很多我这里就不在累赘,我从一个实际例子出发,看如何将一个已经运行了很长时间的普通表进行分区。 回到目录
oracle 分区表常用语句(2)
给分区表增加分区 第一种不存在MAXVALUE(直接添加即可) ALTER TABLE T6 ADD PARTITION P5 VALUES LESS THAN(TO_DATE(' 2018-08-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')); 第二种存在MAXVALUE alter table T6
Oracle 分区表学习笔记
一、基本概念 表空间:是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表, 所以称作表空间。 分区表:当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。 二、具体作用