本文主要是介绍GPT分区表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 概述
GPT和MBR分区表的详细介绍可以参考UEFI规范,其中,UEFI规范可以从官网下载:www.uefi.org 。为方便大家下载,已放在本站:http://download.csdn.net/detail/u013344915/7019195
本文仅对UEFI规范这一部分“GUID Partition Table (GPT) Disk Layout”做简单的解读,更详细地请参考规范原文。原文只有十几页,看起来也不会很吃力。
2. 缩略语
- GPT:GUID Paritition Table
- MBR:Master Boot Record
- LBA:Logical Boot Record
3. GPT相对MBR的优势
- Logical Block Addresses (LBAs) are 64 bits (rather than 32 bits).
LBA是64位编址 ——后面会看到,MBR的编址是4字节,因此只有2TB的硬盘空间可以被寻址;而GPT则是8字节。
- Supports many partitions (rather than just four primary partitions).
支持更多的分区,而不是只有4个主分区 ——实际上MBR可以通过扩展分区来绕过4个主分区的限制。
- Provides both a primary and backup partition table for redundancy.
提供了primary和backup分区表,即冗余备份 ——对于MBR,如果第一个扇区这个MBR破坏了,那么可能硬盘就无法访问了。
- Uses version number and size fields for future expansion.
支持以后的扩展
- Uses CRC32 fields for improved data integrity.
通过CRC32来改价数据完整性
- Defines a GUID for uniquely identifying each partition.
每个分区有一个唯一的GUID
- Uses a GUID and attributes to define partition content type.
GUID和属性来定义分区的内容类型
- Each partition contains a 36 character human readable name.
每个分区可以有个易读的名称
4. MBR
MBR分区的格式如下(规范的Chapter 5 - Table 13):
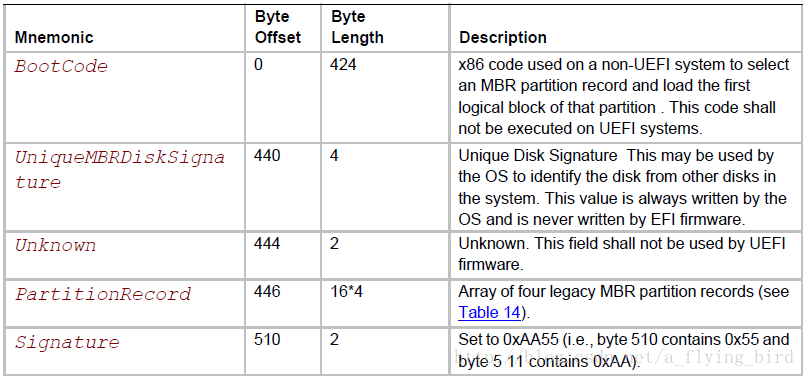
其中PartitionRecord是4个MBR partition record的数组,每个partition record的结构如下(规范的Chapter 5 - Table 14):
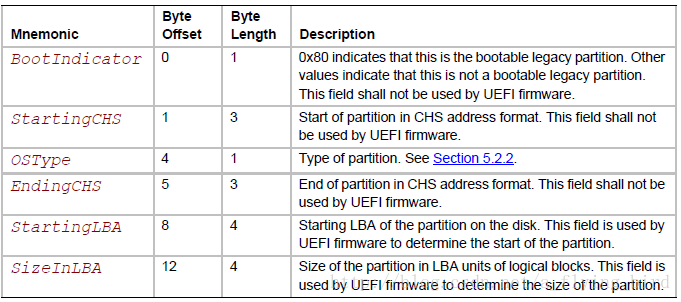
通过以上的两个表,注意到如下几个事实:
- 寻址空间是4个字节:StartingLBA & SizeInLBA,通常一个LBA即一个扇区512字节。所以寻址空间大致是512 * 2^32 = 2TB。如果硬盘空间大于2TB,那么采用MBR就不能把硬盘存储空间用完;
- 只有4个主分区,或者3个主分区+1个扩展分区:但扩展分区中可以有无限制个逻辑分区。对Windows经常装机的对这几个分区会很熟悉;
- MBR中的BootCode是BIOS自举之后加载的硬盘中的第一个数据,接下来才进入OS级别的调用。
MBR格式的磁盘布局如下(规范的图16):
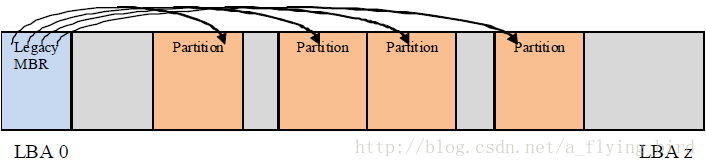
考虑到MBR分区的寻址空间的限制,及其他问题,引申出GPT分区。
5. GPT
对于GPT分区,首先注意一个事实就是:为了让其他OS能够识别硬盘,而采用了兼容MBR的设计策略。即GPT第一个LBA或扇区是称为protective MBR的分区,接下来从LBA1才是GPT的主要的内容。结构如下:
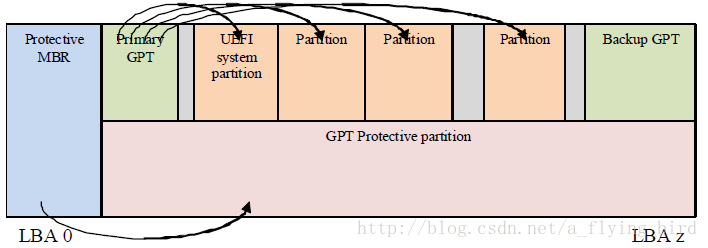
即:
- LBA0:protective MBR,兼容考虑;
- LBA1:Partition Table Header,即GPT分区表的表头,下面会给出Header的组成结构;
- LBA2开始是GPT的每个分区记录,规范称为Partition Entry,其个数仅受磁盘空间所限;
- LBAn:backup GPT Header放在磁盘的最后一个LBA;严格来讲,并不是一个LBA,因为Header部分占用一个LBA,另外的Partition Entries则会占用另外一些LBA空间。
规范的下面这个图形更加形象:
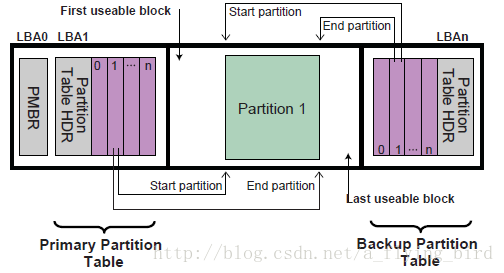
有了上面两个GPT分区结构图,再结合GPT Header和Partition Entry的结构体,就基本理解了GPT分区的情况。
5.1 GPT Header结构体
下面是规范的表17:
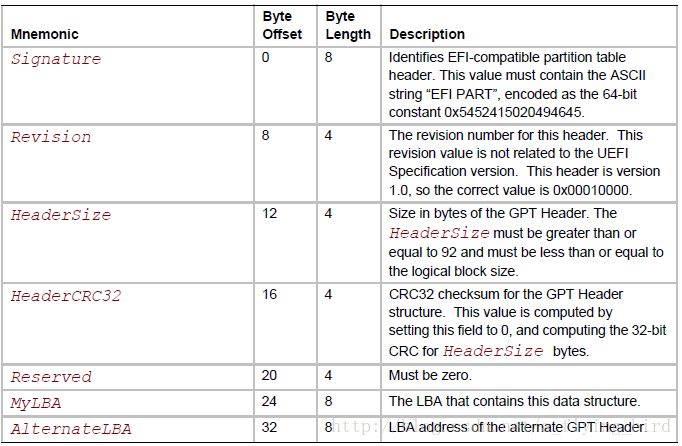
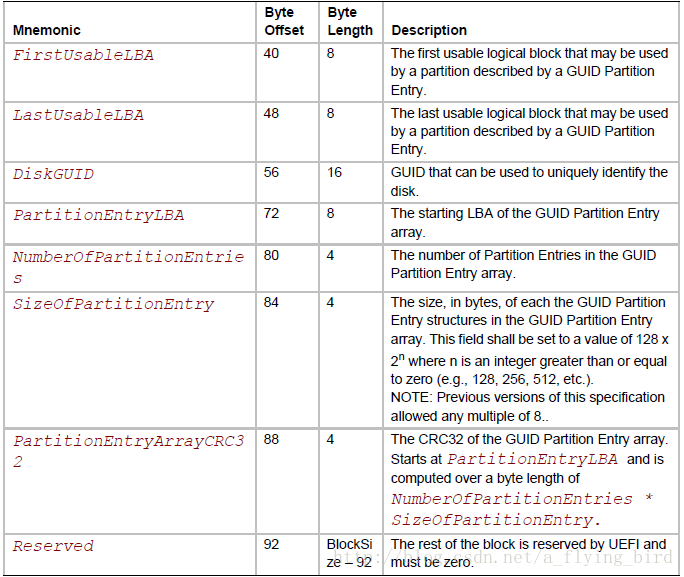
在这个表结构中,
- 有2个CRC32校验:一个是整个Header部分的校验,以及Partition Entries部分的校验。当任何一个分区变化的时候,第二个CRC需要更新,接下来第一个Header级别的CRC也需要更新;
- Header部分仅指定了partition entry的起始LBA、partition entry的个数、每个partition entry的大小;据此就可以通过寻址读取数据来计算partition entries部分的CRC32;
- 指出了backup GPT的LBA,即AlternateLBA;
- 所有LBA寻址都是8个字节,如MyLBA、AlternateLBA、FirstUsableLBA,等等其他的xxxLBA。假定每个扇区是512字节,那么GPT支持的硬盘空间大致就是512 * 2^64 = 8ZB
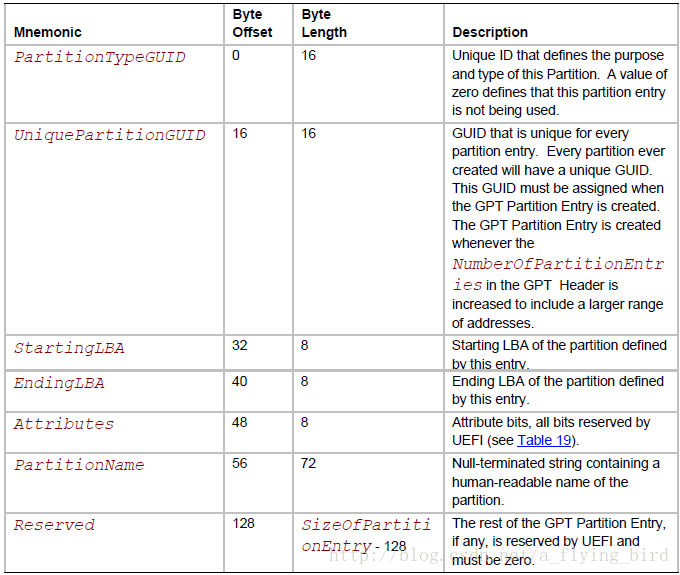
5.2 GPT Partition Entry
对应规范的表18.
6. 示例代码
- Windows:Windows上面读磁盘分区表
- Linux:待补充
7. 延伸阅读
- Windows的磁盘管理、文件系统等:http://msdn.microsoft.com/en-us/library/windows/desktop/aa363978%28v=vs.85%29.aspx
- 分区类型,即MBR中的OSType:http://www.win.tue.nl/~aeb/partitions/partition_types.html
这篇关于GPT分区表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








