本文主要是介绍SQL SERVER分区表的创建和维护实例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SQL SERVER分区表的创建和维护实例
在日常工作中,我们会遇到以下的情况,一个表每日数万级的增长,而查询的数据通常是在本月或今年,以前的数据偶尔会用到,但查询和插入的效率越来越慢,用数据库分区会有助于解决这个问题。关于分区的理论知识网上很多我这里就不在累赘,我从一个实际例子出发,看如何将一个已经运行了很长时间的普通表进行分区。
提出问题
需解决问题:有一个数据表数据很大,我们通常的查询是在一个季度中。我们需要将以往年份的数据按不同年份存在文件组里,当年的数据分为4个季度存,如果到了新的一年,将之前4个季度的合并到一年中,新的一年又按4个季度分区。
解决问题
好了我们将一步步的开始解决问题。
建立模拟环境
1.首先建立数据库,和创建表。
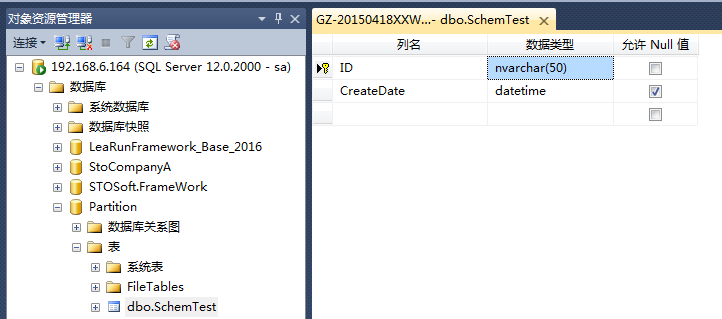
新建个数据库,新建测试表。数据文件放在一个好找的文件夹内,方便分区文件一并放在其中。
2.创建模拟数据。
我用C#程序模拟插入了一些数据,时间从2015-9-1号到2017-4-1每天一天数据。此时表的属性如下,文件组Primary,未分区。
建立分区文件

新建5个文件组,对应5个数据库文件,Y2015存放2015年的数据,Q1,Q2,Q3,Q4存放4个季度的数据,这里我们将文件都放在了同一个文件夹,如果条件允许,放在不同的磁盘上会增加读写效率。
建立分区函数
分区函数RANGE有区分LEFT和RIGHT
LEFT是第一个分区小于等于边界,第二个分区大于
RIGHT是第一个分区小于边界,第二个分区大于等于
CREATE PARTITION FUNCTION [PartitionFunc](datetime) AS RANGE RIGHT FOR VALUES (N'2016-01-01T00:00:00', N'2016-04-01T00:00:00',N'2016-07-01T00:00:00',N'2016-10-01T00:00:00',N'2017-01-01T00:00:00')建立分区方案
这个分区函数将分为6个文件组
CREATE PARTITION SCHEME [PartitionScheme] AS PARTITION [PartitionFunc] TO ([Y2015], [Q1],[Q2],[Q3],[Q4],[PRIMARY])建立好的分区函数和分区方案如下:
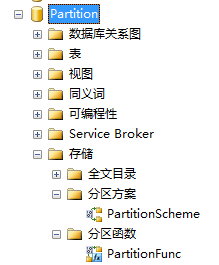
建立分区索引完成分区
分区索引必须是聚集索引,我们建标时用SQL里的主键设置会自动将ID设置为聚集索引这里我们需要把原先的主键改为分聚集索引,在建立分区索引。
CREATE CLUSTERED INDEX [ClusteredIndex_CreateDate] ON [dbo].[SchemTest]
(
[CreateDate]
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [PartitionScheme]([CreateDate])这样表分区就完成了。

查询分区中的数据
我们可以查下在不同分区中的数据,语句如下:
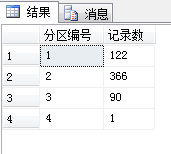
select $PARTITION.PartitionFunc(CreateDate) as 分区编号,count(ID) as 记录数 from SchemTest group by $PARTITION.PartitionFunc(CreateDate) 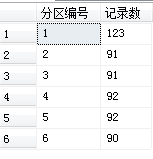
select * from SchemTest where $PARTITION.PartitionFunc(CreateDate)=1 这样查询所有2015年的数据。
分区新增和合并
现在 2015年的数据在2015文件组,2016年数据在4个季度的文件组,2017年数据在Primary的文件组,现在要将2016年的数据放在新增的2016文件组,4个季度的文件组放2017年的数据,Primary放2018年后的。
1.新建2016的文件组

2.分区合并
先将所有季度文件组都合并,这样2017年数据之前都在2015文件组
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2016-01-01T00:00:00');
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2016-04-01T00:00:00');
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2016-07-01T00:00:00');
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2016-10-01T00:00:00'); 可以在分区方案上查看创建SQL语句,这时的分区方案已经更改为:
CREATE PARTITION SCHEME [PartitionScheme] AS PARTITION [PartitionFunc] TO ([Y2015], [PRIMARY])3.分区新增
首先将2016年的数据放在Y2016文件组
--选择文件组
ALTER PARTITION SCHEME PartitionScheme
NEXT USED [Y2016] ;
--修改分区函数
ALTER PARTITION FUNCTION PartitionFunc()
SPLIT RANGE (N'2016-01-01T00:00:00.000') ;同理将2017年的数据分别放在2017年的各个季度中
ALTER PARTITION FUNCTION PartitionFunc() MERGE RANGE (N'2017-01-01T00:00:00');
ALTER PARTITION SCHEME PartitionScheme NEXT USED [Q1] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2017-01-01T00:00:00.000') ;
ALTER PARTITION SCHEME PartitionScheme NEXT USED [Q2] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2017-04-01T00:00:00.000') ;
ALTER PARTITION SCHEME PartitionScheme NEXT USED [Q3] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2017-07-01T00:00:00.000') ;
ALTER PARTITION SCHEME PartitionScheme NEXT USED [Q4] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2017-10-01T00:00:00.000') ;
ALTER PARTITION SCHEME PartitionScheme NEXT USED [PRIMARY] ;
ALTER PARTITION FUNCTION PartitionFunc() SPLIT RANGE (N'2018-01-01T00:00:00.000') ;现在查看分区函数和分区方案的创建语句如下:
CREATE PARTITION SCHEME [PartitionScheme] AS PARTITION [PartitionFunc] TO ([Y2015], [Y2016], [Q1], [Q2], [Q3], [Q4], [PRIMARY])
CREATE PARTITION FUNCTION [PartitionFunc](datetime) AS RANGE RIGHT FOR VALUES (N'2016-01-01T00:00:00.000', N'2017-01-01T00:00:00.000', N'2017-04-01T00:00:00.000', N'2017-07-01T00:00:00.000', N'2017-10-01T00:00:00.000', N'2018-01-01T00:00:00.000')分区记录如下:
如果分区变动比较大不推荐用合并和删除的方法,因为容易出错,如果分12个月建议像下面一样,先将分区表转换为普通表,再把普通表分区。
将分区表转换成普通表
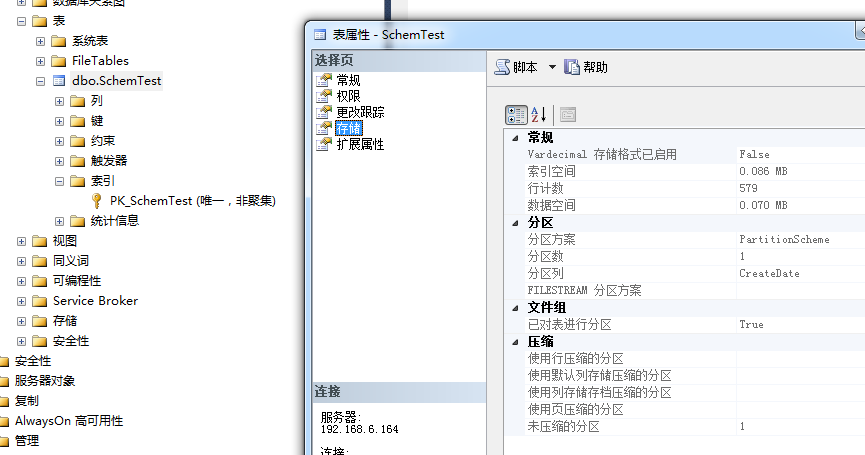
1.删除分区索引
删除分区索引后,并没有变为普通表
2.在原有分区索引字段,建立普通索引,查看表属性会发现表已经恢复为普通表
CREATE CLUSTERED INDEX [IX_SchemTest] ON SchemTest(CreateDate) ON [Primary]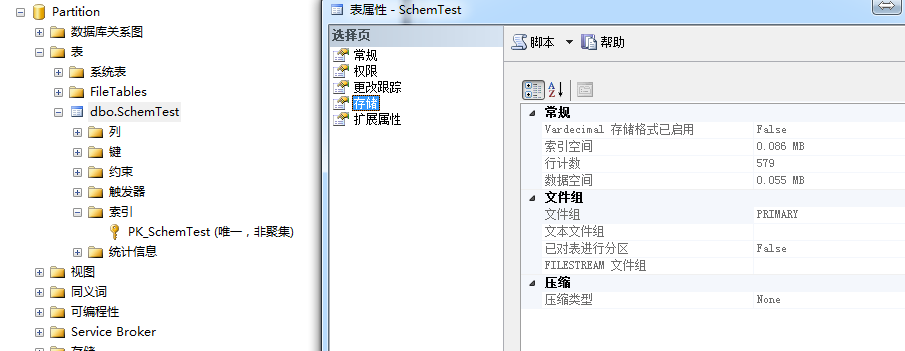
这篇关于SQL SERVER分区表的创建和维护实例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





