倒排专题

Lucence倒排索引
带着问题探索: 全文检索,为什么要全文检索?什么是lucence?什么是倒排索引? 一、全文检索 要了解全文检索首先需要了解:结构化数据与非结构化数据,以及半结构化数据,这三种数据构成了我们生活中所有数据的组成形式。 结构化数据非机构化数据半结构化数据含义有固定格式的的数据无固定格式的数据有一定格式的数据举例数据库中的数据文章,邮件,博客内容XML,HTML文件查询方式sqlgoogle

ElasticSearch--倒排索引
1.ElasticSearch介绍 Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基 于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布, 是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快

Elasticsearc倒排索引(一):概念
顾名思义,有倒排索引则对应肯定就有正排索引,首先介绍一下概念: 倒排索引: 搜索引擎通常检索的场景是:给定几个关键词,找出包含关键词的文档。怎么快速找到包含某个关键词的文档就成为搜索的关键。倒排索引源于实际应用中需要根据属性的值来查找记录,lucene是基于倒排索引实现的。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位

算法:倒排表/倒排索引(Inverted index)
搜索引擎最核心的技术, 倒排索引技术,倒排索引可能需要分成几篇文章才说得完,我们先会说说倒排索引的技术原理,然后会讲讲怎么用一些数据结构和算法来实现一个倒排索引,然后会说一个 索引器怎么通过 文档来生成一个倒排索引。 什么是倒排索引呢?索引我们都知道,就是为了能更快的找到文档的数据结构,比如给文档编个号,那么通过这个号就可以很快的找到某一篇文档,而倒排索引不是根据文档编号,而是通过文档中的某些个

大数据技术之_05_Hadoop学习_04_MapReduce_Hadoop企业优化+HDFS小文件优化方法+MapReduce扩展案例+倒排索引案例(多job串联)+TopN案例+找博客案例
大数据技术之_05_Hadoop学习_04_MapReduce 第6章 Hadoop企业优化(重中之重)6.1 MapReduce 跑的慢的原因6.2 MapReduce优化方法6.2.1 数据输入6.2.2 Map阶段6.2.3 Reduce阶段6.2.4 I/O传输6.2.5 数据倾斜问题6.2.6 常用的调优参数 6.3 HDFS小文件优化方法6.3.1 HDFS小文件弊端6.3.2
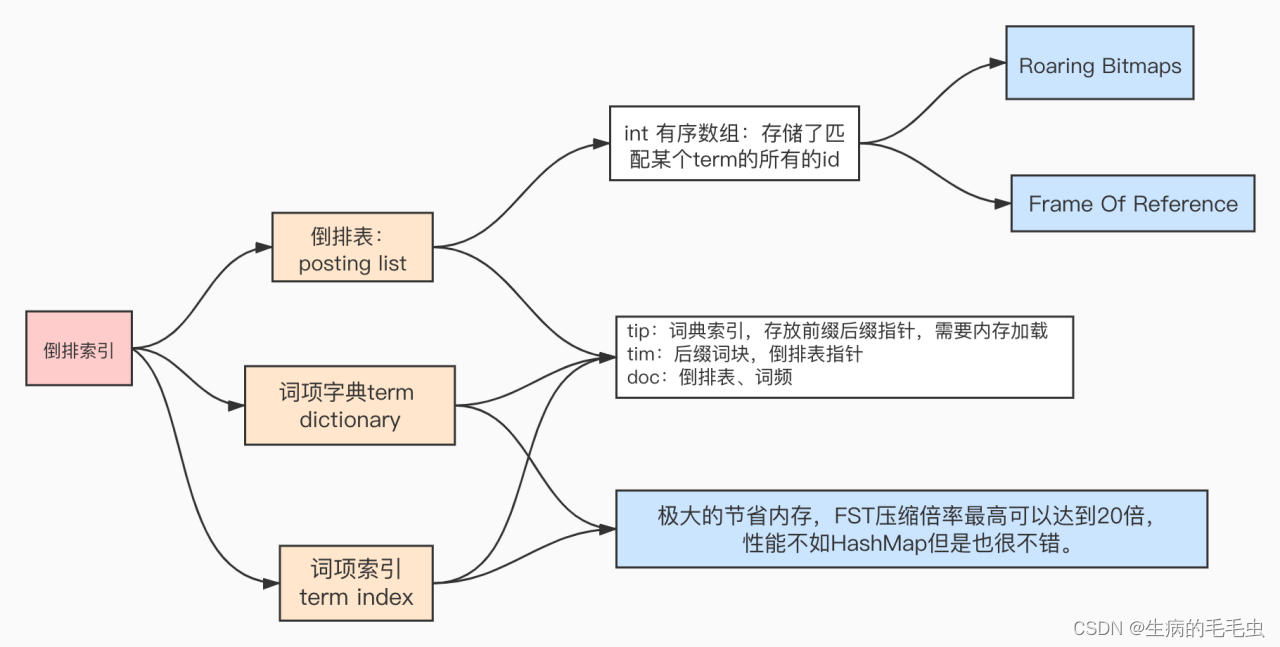
Interview preparation--elasticSearch倒排索引原理
搜索引擎应该具备哪些要求 查询速度快 优秀的索引结构设计高效率的压缩算法快速的编码和解码速度 结果准确 ElasiticSearch 中7.0 版本之后默认使用BM25 评分算法ElasticSearch 中 7.0 版本之前使用 TP-IDF算法 倒排索引原理 当我们有如下列表数据信息,并且系统数据量达到10亿,100亿级别的时候,我们系统该如何去解决查询速度的问题。数据库选择—mysq
ElasticSearch学习笔记(一)倒排索引、ES和Kibana安装、索引操作
文章目录 1 ElasticSearch入门1.1 认识ElasticSearch1.2 倒排索引1.2.1 正向索引1.2.2 倒排索引1.2.3 正向VS倒排 1.3 ES的相关概念1.3.1 文档和字段1.3.2 索引和映射1.3.3 MySQL与ES 2 ES安装2.1 部署单点ES2.1.1 创建网络2.1.2 拉取镜像2.1.3 运行 2.2 部署Kibana2.2.1 拉取镜
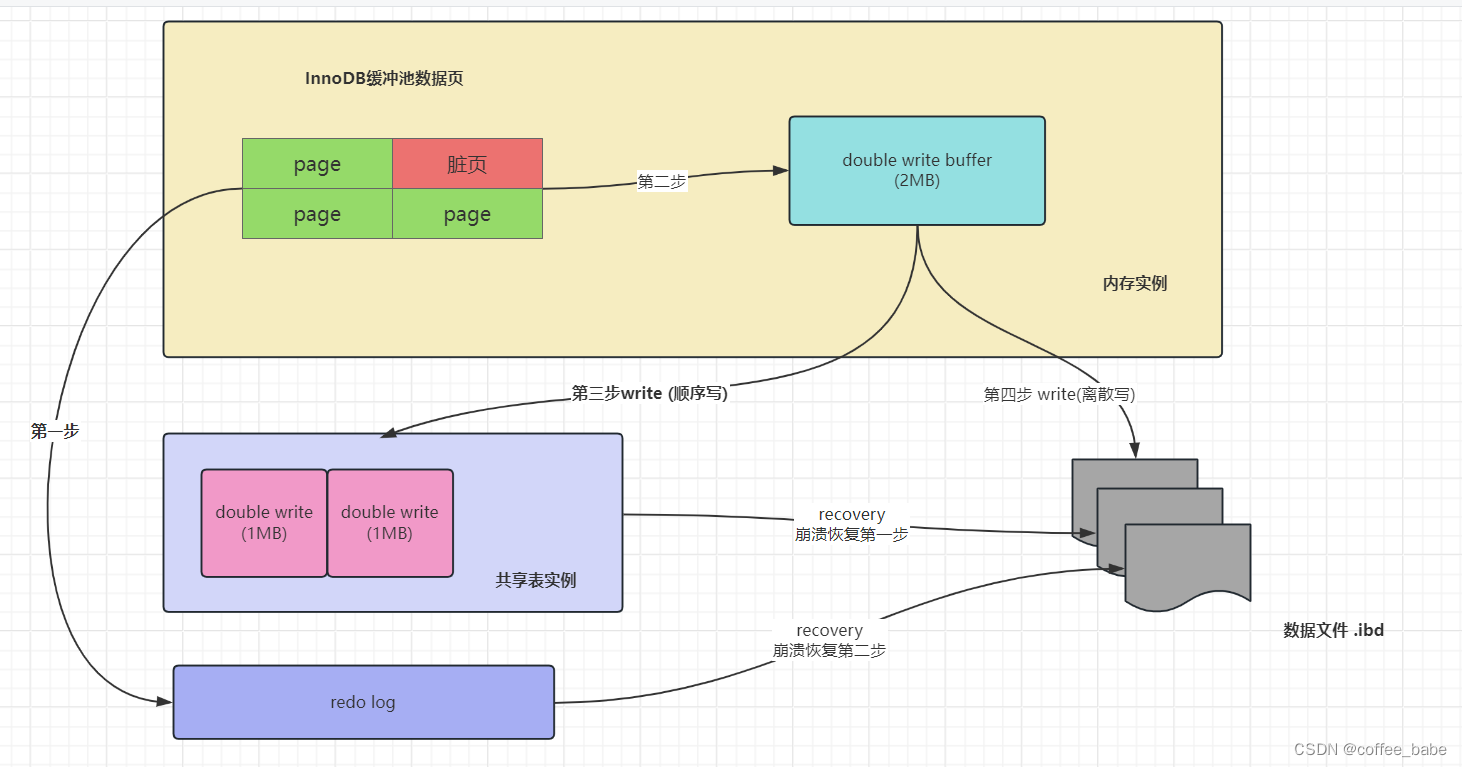
MySQL中的正排/倒排索引和DoubleWriteBuffer
正排/倒排索引 正排索引 文档1:词条A,词条B,词条C文档2:词条A,词条D文档3:词条B,词条C,词条E 正排表是以文档的ID为关键字,表中记录文档中的每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。 正排表的结构如图所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入, 直接为
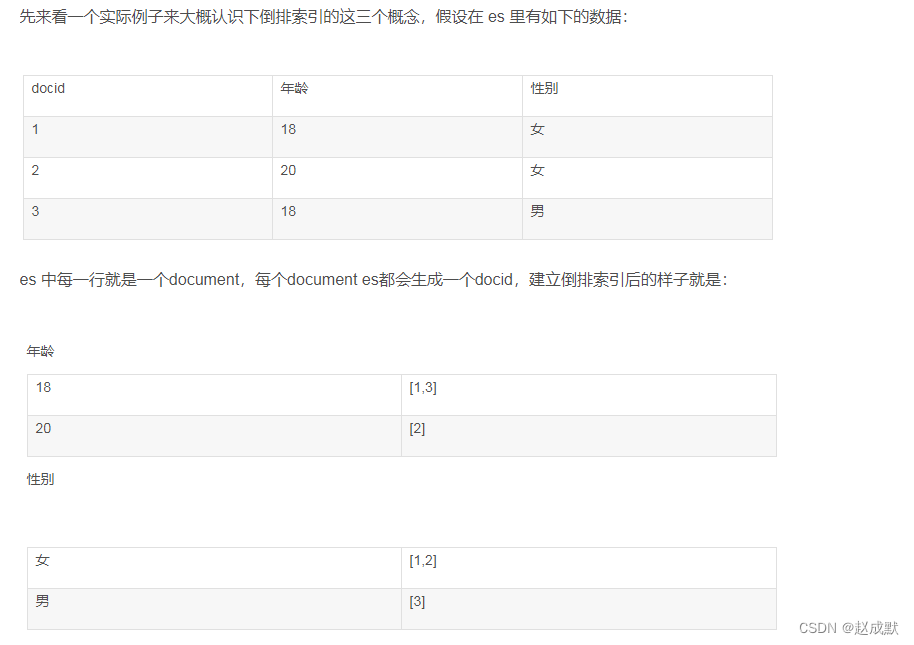
Elastic 索引结构-倒排索引
前言 Elastic 在数据库分类中一般被分为全文检索的数据库,那为什么这么区分呢?主要是因为其独特的索引结构 即倒排索引。 倒排索引 倒排索引先将文档中包含的关键字全部提取出来,然后再将关键字与文档的对应关系保存起来,最后再对关键字本身做索引排序。用户在检索某一关键字时,可以先对关键字的索引进行查找,再通过关键字与文档的对应关系找到所在文档。这类似于查字典一样,字典的拼音表和部首中的内容就

正排索引和倒排索引的区别
正排索引和倒排索引是数据库中常见的两种索引方式,它们有以下区别: 1. 数据结构不同:正排索引是按照文档的顺序存储索引,而倒排索引是根据关键词来存储索引。 2. 查询方式不同:正排索引适合按文档顺序进行查询,倒排索引则更适合通过关键词进行查询。 3. 适用场景不同:正排索引适用于一些特定的查询需求,倒排索引在搜索引擎等场景中应用广泛。 常用的数据库

全文检索:倒排索引的理解
一.定义:是基于单词-文档矩阵的一种存储形式,它描述了一个term词项集合和文档集合之间具有映射关系的数据结构。 1. term词项集合列表:定义要搜索的一些词。 2. 词项文档映射集合列表:定义单词id,单词,单词在文档中的位置,单词出现的频率,文档出现的频率等信息。 文档列表: 词项集合 :
![华为OJ——[中级]单词倒排](/front/images/it_default2.jpg)
华为OJ——[中级]单词倒排
【中级】单词倒排 题目描述 对字符串中的所有单词进行倒排。 说明: 1、每个单词是以26个大写或小写英文字母构成; 2、非构成单词的字符均视为单词间隔符; 3、要求倒排后的单词间隔符以一个空格表示;如果原字符串中相邻单词间有多个间隔符时,倒排转换后也只允许出现一个空格间隔符; 4、每个单词最长20个字母; 输入描述: 输入一行以空格来分隔的句子 输出描述: 输出句子的逆序

Lucene暴走之巧用内存倒排索引高效识别垃圾数据
[size=medium] 识别垃圾数据,在一些大数据项目中的ETL清洗时,非常常见,比如通过关键词 (1)过滤垃圾邮件 (2)识别yellow网站 (3)筛选海量简历招聘信息 (4)智能机器人问答测试 ........ 各个公司的业务规则都不一样,那么识别的算法和算法也不一样,这里提供一种思路,来高效快速的根据关键词规则识别垃圾数据。 下面看下需求: 业务定义一些主关键
Elasticsearch如何动态维护一个不可变的倒排索引
上一篇文章中介绍了Elasticsearch中是如何搜索文本的,同时也简述了在es里面索引数据结构的特点不可变性。 索引不可变性的缺点限制了单个索引存储的最大数据量以及更新的频次,所以es面临的问题是如何解决倒排索引不可更新的特点而同时仍然保持不可变特性带来的好处。 答案就是使用多个索引 代替原来的每次重写整个索引,es里面采用方式是增加新的索引来反映最近的变化,然

正排索引和倒排索引简单介绍
正排索引和倒排索引简单介绍 在搜索引擎中,数据被爬取后,就会建立index,方便检索。 在工作中经常会听到有人问,你这个index是正排的还是倒排的?那么什么是正排呢?什么又是倒排呢?下面是一些简单的介绍。 网页A中的内容片段: Tom is a boy. Tom is a student too. 网页B中的内容片段:

现代信息检索3---词汇表和倒排记录表
第二节里我们了解了倒排索引的基本知识,包括构建、合并、查询等。课件里有个关于google中是否使用布尔模型?这个问题我们还是看下图吧: 让我感觉简单的布尔模型还是有用武之地的。下面是新的知识,对于我这个自学的人来说还是有点难,只能按照我自己的理解去说了。如果有误,欢迎指正。 你一定还记得这个图吧!当时只是一笔带过,现在应该去思考为什么会是这样的。先说下步骤吧: 我们构建索引的输入一般

信息检索笔记-词项及倒排记录表
建立倒排表的几个主要步骤:搜集文档;对文档中的文本进行词条化;对词条进行语言学处理,得到词项;根据词项建立倒排索引。 通过词条化和语言学处理我们才能确定系统的所用词项词典。词条化将原始的字符流转换成一个个词条的过程,而语言学处理主要是建立词条的等价类。 文档分析及编码生成 文档一般由文件或者web中的网页组成,那么第一步我们要确定其编码方式,有时我们
Java面试必问题50:ElasticSearch倒排索引详解
Elasticsearch的倒排索引是一种高效的数据结构,存储了词条(term)和文档ID之间的对应关系。 倒排索引的结构如下: - 词项(term)存储在一个有序的词典(Dictionary)中,每个词项都关联着一个唯一的词项编号。 - 对于每个词项,倒排索引会有一个倒排列表(Inverted List),它记录了包含该词项的文档ID列表。 在倒排列表中,文档ID序列通常是有序的

关于倒排索引表的总结
最近在研究elasticsearch的技术栈 ,发现ES底层是基于luence技术进行检索,检索的原理是倒排索引表。那么什么是倒排索引表呢?在知乎上看到一个讲解elasticsearch的倒排索引表的帖子。 链接是:https://zhuanlan.zhihu.com/p/33671444 为什么说elasticsearch的倒排索引表的检索速度是比关系型数据库的索引查新更快呢?首先,关系型数
Elasticsearch倒排索引与B+Tree对比
如何快速检索? Elasticsearch 是通过 Lucene 的倒排索引技术实现比关系型数据库更快的过滤。特别是它对多条件的过滤支持非常好,比如年龄在 18 和 30 之间,性别为女性这样的组合查询。倒排索引很多地方都有介绍,但是其比关系型数据库的 b-tree 索引快在哪里?到底为什么快呢? 笼统的来说,b-tree 索引是为写入优化的索引结构。当我们不需要支持快速的更新的时候,可以用预
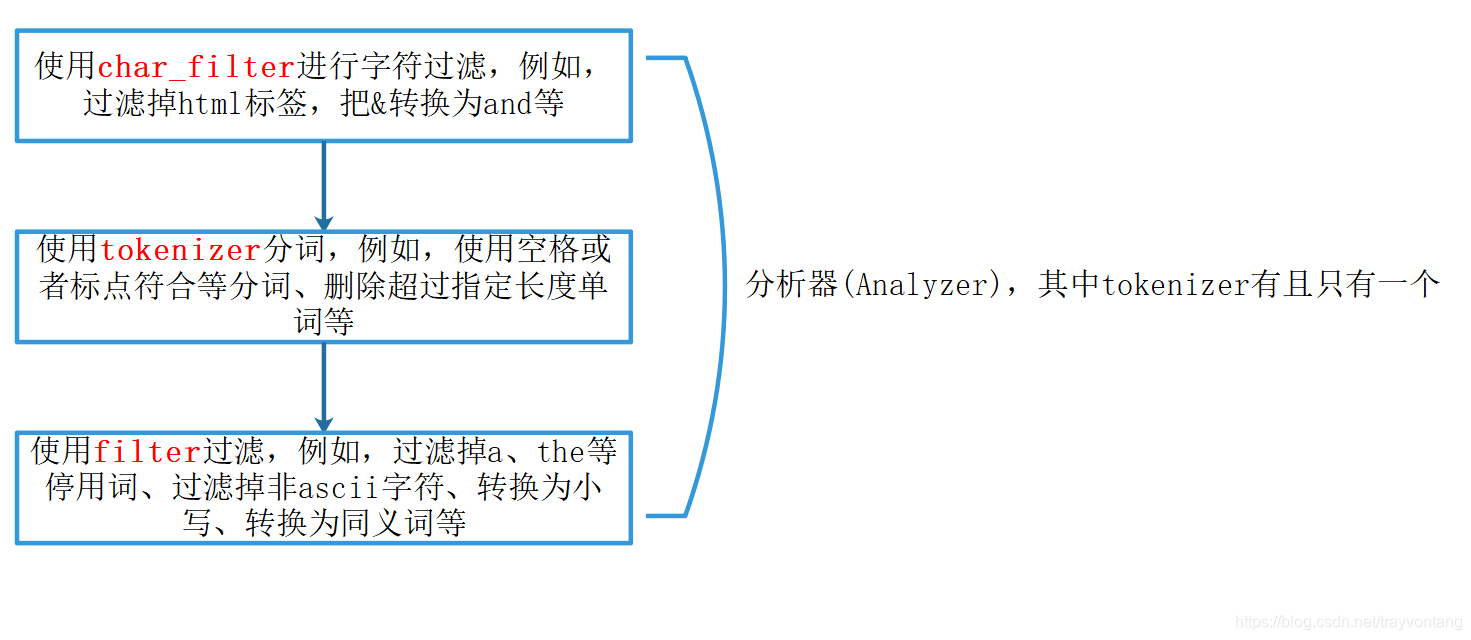
Elasticsearch倒排索引与文档添加原理(一)
目录 相关文章一、 倒排索引二、segment三、 ES添加文档的流程四、 创建倒排索引(refresh)五、 flush六、文档 相关文章 一、 倒排索引 虽然你可能对倒排索引非常熟悉了,但是这里还是想重新反思一下。 思考:我们通过搜索引擎搜索一个关键字,搜索引擎怎样查找它抓取到的那些文档中包含这个关键字。 要去遍历所有文档吗?显然不现实,所以一种新的数据结构倒排索引出
搜索引擎中的倒排索引是什么
在搜索引擎领域,倒排索引是一种核心数据结构,它让搜索引擎能够以极高的效率找到包含用户查询关键词的所有网页。为了理解倒排索引的工作原理,我们可以将其与一种更直观、生活化的例子相比较:书店里的索引卡片系统。 假设你是一位图书管理员,你的任务是帮助顾客快速找到他们想要的书籍。如果你按每本书来组织信息,每当有人来找特定主题的书时,你可能需要查看每一本书来确定它是否是顾客想要的。这种方式显然效率很低,特别
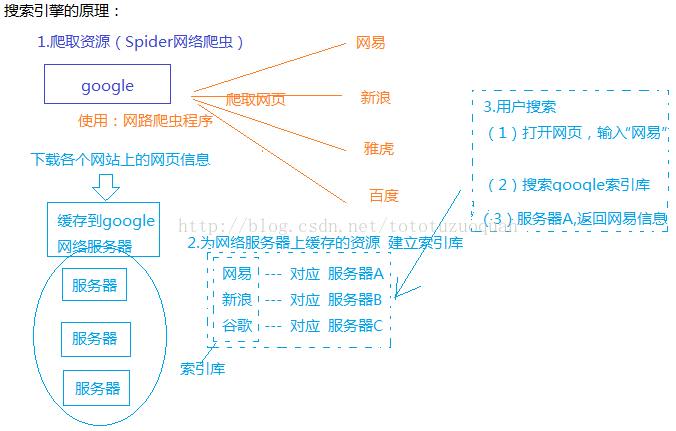
1.搜索引擎的历史,搜索引擎起步,发展,繁荣,搜索引擎的原理,搜索技术用途,信息检索过程,倒排索引,什么是Lucene,Lucene快速入门
一: 1 搜索引擎的历史 萌芽:Archie、Gopher Archie:搜索FTP服务器上的文件 Gopher:索引网页 2 起步:Robot(网络机器人)的出现与spider(网络爬虫) Robot基于网络的,可以执行特定任务的程序 Spider:特殊的机器人,网络爬虫,爬取互联网上的信息(可以是文件,网络)----网络自
ElasticSearch倒排索引原理是什么?如何实现?
1、ElasticSearch倒排索引原理是什么? ElasticSearch的倒排索引原理是一种高效的信息检索技术,它允许用户快速搜索文档中的关键字。以下是其原理的详细解释: 1、文档分析:在索引文档之前,ElasticSearch会对文档进行分词处理,即将文本拆分成一个个的单词或词项。这个过程通常还包括去除停用词(如“的”、“是”等常见但对搜索意义不大的词)和进行词干提取等步骤。这样,原始

BoostCompass(建立正排索引和倒排索引模块)
阅读导航 一、模块概述二、编写正排索引和倒排索引模块✅安装 jsoncpp✅Jieba分词库的安装1. 代码基本框架2. 正排索引的建立3. 倒排索引的建立 三、整体代码⭕index.hpp 一、模块概述 这个模块我们定义了一个名为Index的C++类,用于构建和维护一个文档索引系统。该系统采用单例模式确保只有一个索引实例,并使用正排索引和倒排索引来快速检索文档。正排索引存储