本文主要是介绍MySQL中的正排/倒排索引和DoubleWriteBuffer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
正排/倒排索引
正排索引
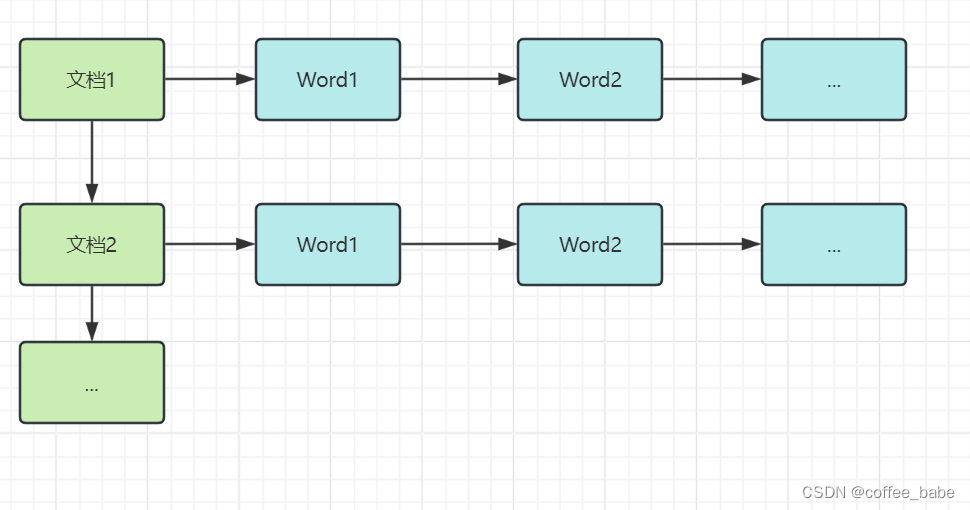
文档1:词条A,词条B,词条C
文档2:词条A,词条D
文档3:词条B,词条C,词条E
正排表是以文档的ID为关键字,表中记录文档中的每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
正排表的结构如图所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,
直接为文档建立一个新的索引块,挂接在原来的索引文件的后面,如果是有文档删除,则直接找到该文档号对应的索引信息,将其直接删除。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
倒排索引
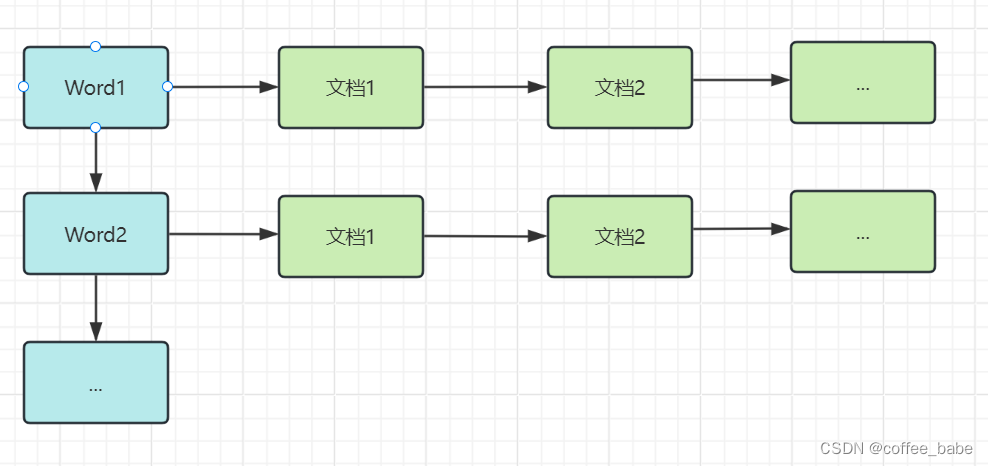
词条A:文档1,文档2
词条B:文档1,文档3
词条C:文档1,文档3
词条D:文档2
词条E:文档3
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字的所有文档,所以效率高于正排表。
在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排索引和全文索引有什么区别?
倒排索引和全文索引之间存在一些关键的区别,尽管它们在某些方面可能有重叠,以下是它们的主要区别:
- 1.定义和目的
1.1倒排索引
定义:倒排索引是一种索引数据结构,用于存储文档中的词条及其在文档中的位置。它的核心是一个映射,将词条映射到包含这些词条的文档ID列表
目的:主要用于快速检索包含特定词条的文档,非常适合搜索引擎中的关键词查询
1.2 全文索引
定义:全文索引是一种用于加速对文本文档内容进行搜索的索引结构。它通常包括倒排索引,但可能还包含其他结构和优化技术,如位置索引、词频等
目的:提供对文本文档的全文搜索能力,支持复杂查询,如布尔搜索、短语搜索、相似度搜索等 - 2.索引结构
倒排索引:包含一个或多个词条,每个词条关联一个文档ID列表。文档ID列表可能还包含位置信息(即词条在文档中的具体位置)。例如
词条 "apple" -> [文档1,文档2,文档5]
词条"banana" -> [文档2,文档3]
全文索引:除了倒排索引外,全文索引可能还包含其他数据结构和信息,哟关于优化查询性能和支持复杂查询。可能包含c词条的词频信息、词条的位置索引、同义词处理、词干处理等。例如:
词条"apple" -> [文档1(位置:5,20), 文档2(位置:3, 15), 文档5(位置7)]
词条"banana" -> [文档2(位置:8,22),文档3(位置:11)]
- 3.功能和查询能力
倒排索引:主要支持关键词查询,即查找包含某个或某些特定词条的文档。查询速度块,适合简单的词条存在性查询
全文索引:支持复杂查询,如布尔查询、短语查询、前缀查询、模糊查询、相似度查询等。提供更丰富的查询功能,能够处理自然语言查询,进行排序和相关性评分 - 4.使用场景
倒排索引:通常用于搜索引擎和信息检索系统,用于快速查找包含特定关键词的文档。适合于大规模文本数据的关键词检索
全文索引:广泛用于数据库管理系统、内容管理系统和搜索引擎,提供高级的全文搜索功能。适用于需要进行复杂文本搜索和自然语言处理的应用场景 - 5.总结
倒排索引是全文索引的一部分,是一种具体的数据结构,主要用于支持关键词查询。
全文索引则是一个更广泛的概念,包含倒排索引以及其他用于支持复杂文本搜索的技术和数据结构
DoubleWriteBuffer
概述
InnoDB是MySQL中一种常用的事务性存储引擎,它具有很多优秀的特性。其中,Doublewrite Buffer(双写缓冲区)是InnoDB的一个重要特性之一
为什么需要DoubleWrite Buffer?
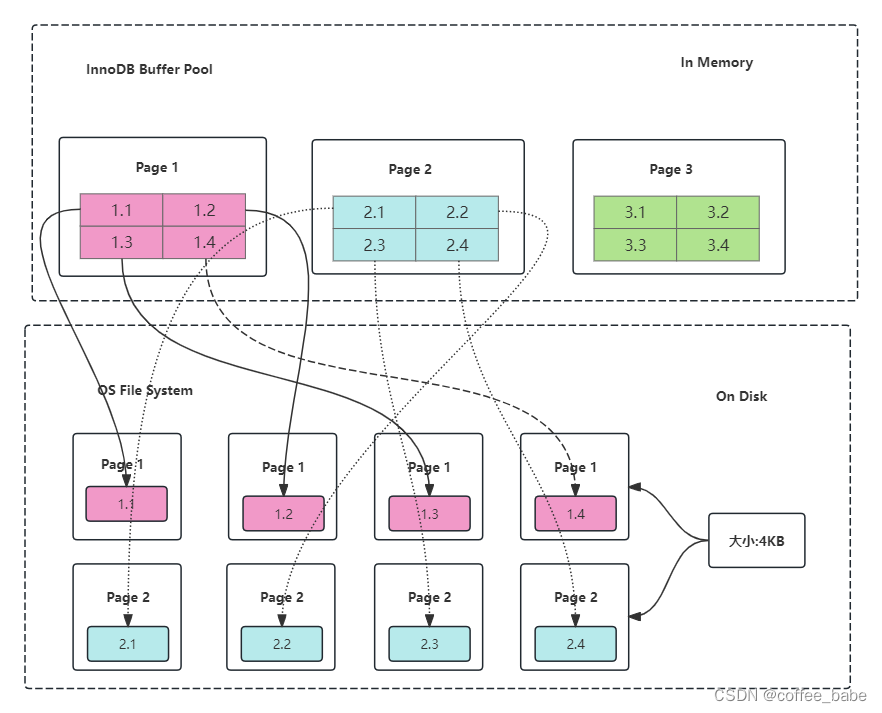
我们常见的服务器一般都是Linux操作系统,Linux文件系统页(OS page)的大小默认是4KB。而MySQL的页(Page)大小默认是16KB,可以使用如下命令查看MySQL的Page大小:
mysql> SHOW VARIABLES LIKE 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.01 sec)
一般情况下,其余程序因为需要跟操作系统交互,它们的页(Page)都会大于等于操作系统的页大小,为整数倍。比如,Oracle的Page大小为8KB。MySQL程序是跑在Linux操作系统上的,需要跟操作系统交互,所以MySQL中一页数据刷到磁盘,要写4个文件系统里的页。如图所示。
需要注意的是,这个操作并非原子操作,比如我操作系统写到第二个页的时候,Linux及其断电了,这时候就会出现问题了。造成"页数据损坏"。并且这种"页数据损坏"靠redo日志是无法修复的。重做日志中记录的是对页的物理操作,而不是页面的全量记录,而如果发生Parial Page Write(部分页写入)问题时,出现问题的是未修改过的数据,此时重做日志(Redo Log)无能为力。写double write buffer成功了,这个问题就不用担心了。
DoubleWriteBuffer的出现就是为了解决上面的这种情况,虽然名字带了Buffer,但实际上DoubleWriteBuffer是内存+磁盘的结构。
DoubleWriteBuffer是一种特殊文件flush技术,带给InnoDB存储引擎的是数据页的可靠性。它的作用是,在把页写道数据文件之前,InnoDB先把它们写道一个叫double write buffer完成后,InnoDB才会把页写道数据文件的适当的位置。如果在写页的过程中发生意外崩溃,InnoDB在稍后的恢复过程中在double write buffer中找到完好的page副本用于恢复。
Double Write Buffer原理
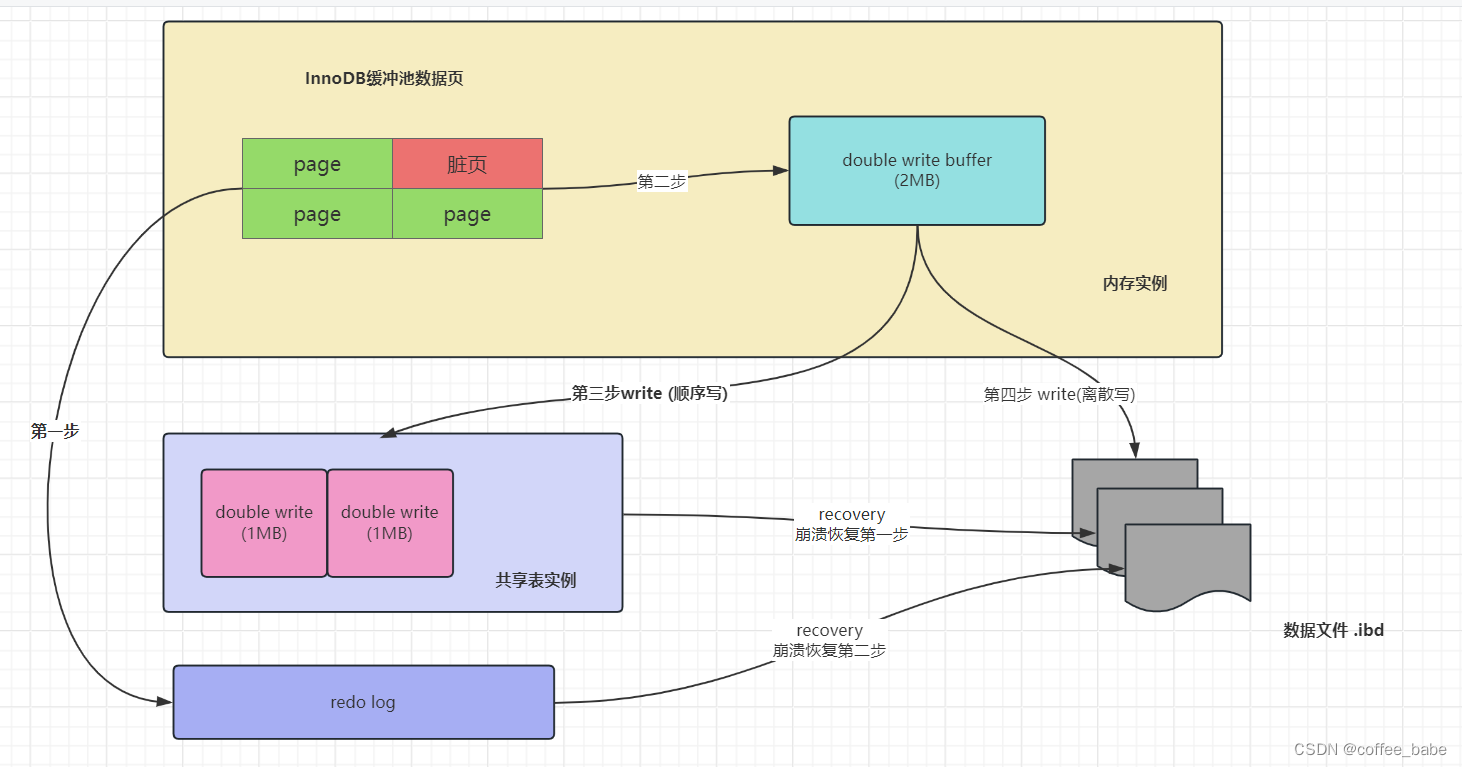
如图所示,当有页数据要刷盘时:
- 1.页数据先通过memcpy函数拷贝至内存中的Doublewrite buffer中
- 2.Doublewrite buffer的内存里的数据页,会fsync刷到Doublewrite buffer的磁盘上,分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB
- 3.Doublewrite buffer的内存里的数据页,再刷到数据磁盘存储.ibd文件上(离散写)
Doublewrite buffer内存结构由128个页(Page)构成,大小是2MB。DoublewriteBuffer磁盘结构再系统表空间上是128个页(2个区,extend1和extend2),大小事2MB.如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中,InnoDB存储引擎可以从共享表空间中的Doublewrite中找到该页的一个副本,将其复制到表空间文件,再应用重做日志。MySQL会检查double write的数据的完整性,如果不完整直接丢弃double write buffer内容,重新执行那条redo log,如果double write buffer的数据是完整的,用double write buffer的数据更新该数据页,跳过该redo log.所以在正常的情况下,MySQL写数据页时,会写两遍到磁盘上,第一遍是写到double write buffer,第二遍是写到真正的数据文件中,这就是"Doublewrite"的由来。在数据库异常关闭的情况下启动时,都会做数据库恢复(redo)操作,恢复的过程中,数据库都会检查页面是不是合法(校验等等),如果发现一个页面校验结果不一致,则此时会用到双鞋这个功能。我们可以通过如下命令来监控Doublewrite buffer工作负载
mysql> SHOW GLOBAL status LIKE '%dblwr%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Innodb_dblwr_pages_written | 1961 |
| Innodb_dblwr_writes | 67 |
+----------------------------+-------+
2 rows in set (0.00 sec)
Doublewrite Buffer相关参数
- 1.innodb_doublewrite:Doublewrite Buffer是否启用开关,默认是开启状态,InnoDB将所有数据存储两次,首先到双写缓冲区,然后到实际数据文件
- 2.innodb_dblwr_pages_written:记录写到DWB中的页数量
- 3.innodb_dblwr_writes:记录DWB写操作的次数
总结
InnoDB Doublewrite Buffer是InnoDB的一个重要特性,用于保证MySQL数据的可靠性和一致性。它的实现原理是通过将要写入磁盘的数据先写入到DoublewriteBuffer中的内存缓存区域,然后再写入到磁盘的两个不同位置,来避免由于磁盘损坏等因素导致数据丢失或不一致的问题。DoublewriteBuffer对于保证MySQL数据的安全性和一致性具有重要意义
这篇关于MySQL中的正排/倒排索引和DoubleWriteBuffer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








