本文主要是介绍Elasticsearch倒排索引与文档添加原理(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 相关文章
- 一、 倒排索引
- 二、segment
- 三、 ES添加文档的流程
- 四、 创建倒排索引(refresh)
- 五、 flush
- 六、文档
相关文章
一、 倒排索引
虽然你可能对倒排索引非常熟悉了,但是这里还是想重新反思一下。
思考:我们通过搜索引擎搜索一个关键字,搜索引擎怎样查找它抓取到的那些文档中包含这个关键字。
要去遍历所有文档吗?显然不现实,所以一种新的数据结构倒排索引出现。
| term | 数据 |
|---|---|
| hello | doc1-3-2-0-5,doc2-1-3-1-6 |
| world | doc1-3-2-0-5,doc2-1-3-1-6 |
| Elasticsearch | doc5-3-2-0-5,doc9-1-3-1-6 |
如上所示,算是一个简化版本的倒排索引结构,它的数据中包含文档号、词频、位置和偏移量。
例如,上面的倒排索引显示hello这个单词:
在doc1这个文档中出现了3次,出现在第2个单词,这个单词在文档中从第0个字节开始,第5个字节结束。
在doc2这个文档中出现了1次,出现在第3个单词,这个单词在文档中从第1个字节开始,第6个字节结束。
同理,对应world、Elasticsearch以及其他关键词也一样。
这样当我们搜索hello这个单词的时候,我们可以很容易的知道哪些文档中包含有hello这个单词。当然实际情况会复杂很多,因为会有多个节点包含多个倒排索引。
在ES中我们可以通过mapping的index_option参数来控制倒排索引中包含哪些属性(文档号、词频、位置、偏移量)
二、segment
segment是ES的倒排索引,它的特别之处在于不会被修改,只会被合并和删除。
后面我们会介绍,每一次refresh都会产生一个segment,这些segment最终被保存到磁盘称为一个文件。
每一个segment都会占用文件句柄,更加重要的是每一个搜索请求都必须访问每一个segment,这就意味着存在的segment越多,消耗内存、cpu越多,搜索请求就会变的更慢。
所以,ES会在后台有一个合并segment的任务,下面是控制segment合并的一些参数:
| 参数 | 说明 |
|---|---|
| index.merge.policy.floor_segment | 默认2MB,小于该值的segment优先被合并 |
| index.merge.policy.max_merge_at_once | 默认10,一次最多合并多少segment |
| index.merge.policy.max_merged_segment | 默认5GB,超过该值的segment不合并 |
| index.merge.policy.max_merge_at_once_explicit | 显式调用一次最多合并多少个segment |
三、 ES添加文档的流程
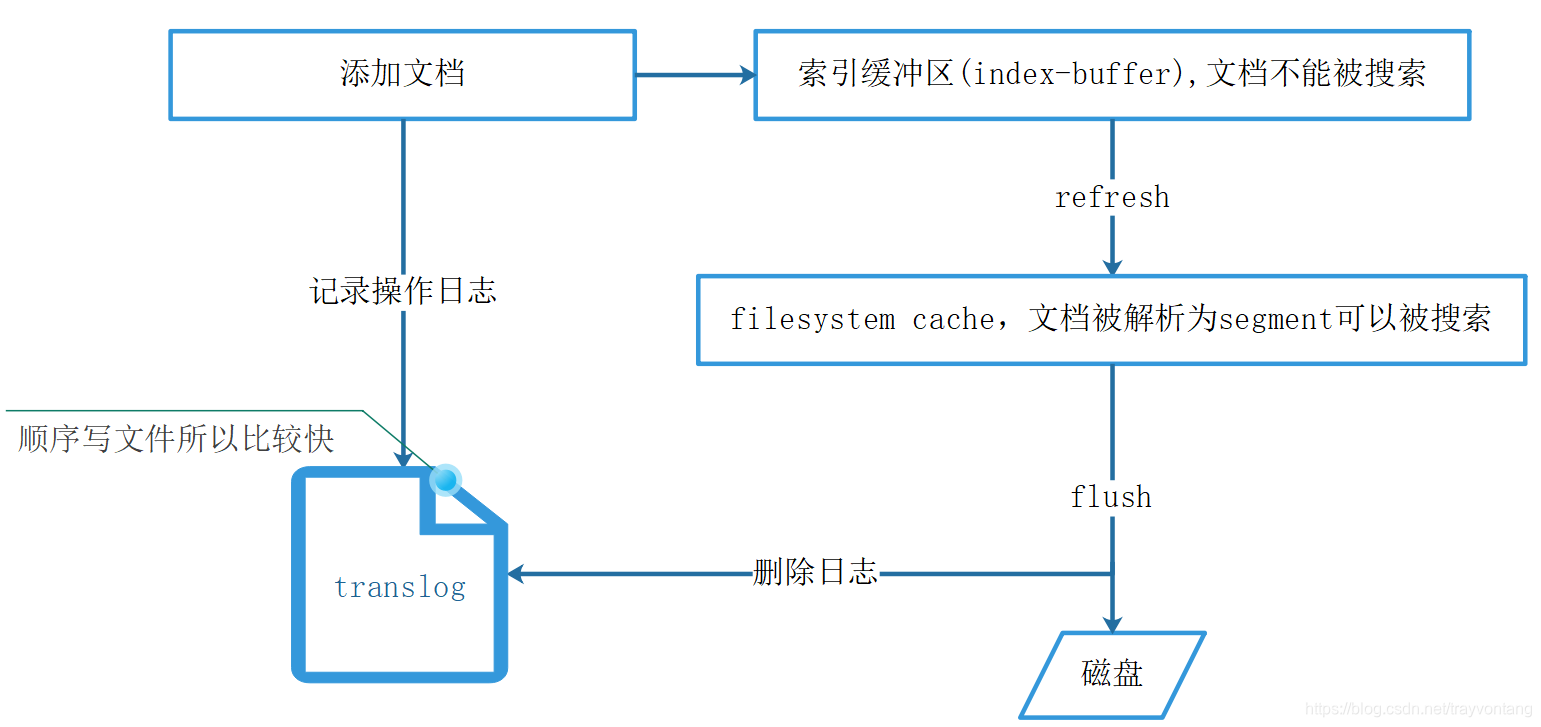
添加文档的时候并不会直接解析,而是先添加到index-buffer,默认会一秒钟使用refresh处理一次,把文档解析为segment存放在filesystem cache中。
然而segment并不会马上写入磁盘,而是根据flush配置策略落盘,后面会详细介绍refresh与flush。
添加文档的时候另一个重要步骤就是写translog,因为文档到segment是有时间差的,并且segment也并不会马上写磁盘,所以先写translog保证数据不丢失。
当然如果translog是异步写,也可能会丢失部分数据。
translog是文件,因为顺序写,而且不出来数据,所以比较快
四、 创建倒排索引(refresh)
refresh就是将document解析为segment的过程,在ES中数据会从index-buffer到filesystem-cache的过程。
refresh过程:
- 将index-buffer中的文档写入一个新的segment中
- 打开segment,以便于文档能够被搜索到
- 清除index-buffer中的文档
五、 flush
flush操作主要是内存中filesystem cache的segment落盘。
flush操作的流程:
- 将index-buffer中的文档写入一个新的segment中
- 清除index-buffer中的文档
- 往磁盘里写入commit point信息
- 将filesystem cache中的segment使用fsync写到磁盘
- 删除旧的translog文件
下面是一些控制flush操作的参数:
| 参数 | 说明 |
|---|---|
| index.translog.flush_threshold_ops | 多少次操作时执行一次flush,默认是unlimited |
| index.translog.flush_threshold_size | translog大小达到此值时flush,默认是512mb |
| index.translog.flush_threshold_period | 在该时间内至少有一次flush,默认是30m |
| index.translog.interval | 多少时间间隔内会检查一次translog大小,默认是5s |
六、文档
index-buffer
translog
这篇关于Elasticsearch倒排索引与文档添加原理(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



