本文主要是介绍Interview preparation--elasticSearch倒排索引原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
搜索引擎应该具备哪些要求
- 查询速度快
- 优秀的索引结构设计
- 高效率的压缩算法
- 快速的编码和解码速度
- 结果准确
- ElasiticSearch 中7.0 版本之后默认使用BM25 评分算法
- ElasticSearch 中 7.0 版本之前使用 TP-IDF算法
倒排索引原理
- 当我们有如下列表数据信息,并且系统数据量达到10亿,100亿级别的时候,我们系统该如何去解决查询速度的问题。
- 数据库选择—mysql, sybase,oracle,mongodb,唯一加速查询的方法是添加索引
索引
- 无论哪一种存储引擎的索引都是如下几个特点
- 帮助快速检索
- 以数据结构为载体
- 以文件的形式落地
- 如下图中mysql的文件形式,其中的idb文件就是使用innodb存储引擎来实现数据存储生成的文件,其他后缀的文件是其他存储引擎生成的,因此无论什么引擎,索引方式,数据结构最终都是要落文件的
- 传统数据库的基本结构如下:

- MySql包括Server层和存储引擎层:Server层包括,连接器,查询缓存,分析器,优化器,执行器
- 连接器:负责和客户端建立连接
- 查询缓存:MySql获取到查询请求后,会先查询缓存,如果之前已经执行过一样的语句结果会以Key-value的形式存储到内存中,key是查询语句,value是查询结果。缓存明中的话可以很快完成查询,但是大多是情况不能明中,不建议用缓存,因为缓存失效非常频繁,任何对表的更新都会让缓存晴空,所以对一个进程更改的表而言,查询缓存基本不可用,除非是一张配置表。可以通过配置来决定释放开启查询缓存,并且MySql8.0 之间删除了查询缓存功能
- 分析器:词法分析,识别语句中表名,列名,语法分析,判断Sql是否满足MySql语法
- 优化器:在有多个索引的情况下,决定使用哪个索引,或者多表联合查询的时候,表的连接顺序这么执行等
- 执行器:执行器先判断权限,有权限才会去调用存储引擎对应的查询接口,默认InnoDB
数据载体 mongodb & mysql
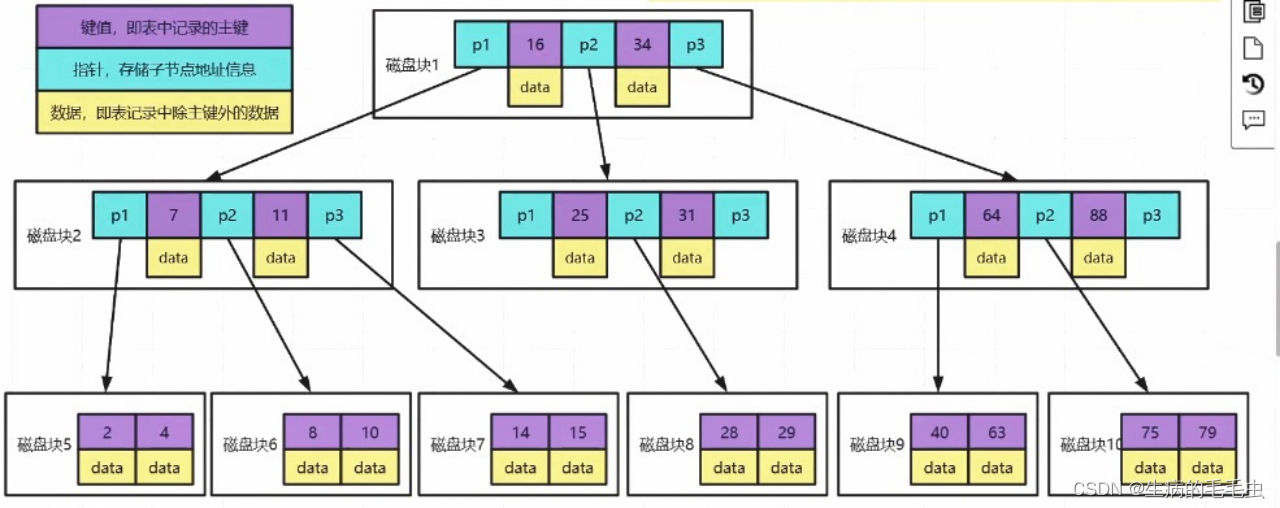
- 以为mongodb为案例,索引数据存储的结构如下
-
Mongodb索引使用的是B树:B树是多叉平衡查找树,包括以下几个结构特性
- 左子树数据小于跟数据,右子树数据大于根节点数据
- 左右子树高度差不大于1
- 每个节点可以有N个字节的,N>2
-
B树的每个节点都存放 索引 & 数据,数据遍布整个树结构,搜索可能在非叶子结点结束,最好情况是O(1)
-
B树存在的问题:
- 紫色部分存储数据的主键信息,蓝色存储的是指针指向下一个节点,黄色部分是存储的主键对应的数据Data。因此Data是在节点中占比最大的一部分数据,他可能有1M或者更大的一个数据体
- 假设我们一个节点的大小是固定的M,在Mysql中最小的数据逻辑单元是数据页,一个数据页是16KB,如果Data越大,M所能容纳的Data个数就越小就导致存储更多的数据久需要更多的节点,B树为了承载更多的节点为了满足结构特性就需要更多的分叉,因此就导致树的深度更大,每一个层级都意味着一次IO操作导致IO次数更多
-
以为Mysql为案例分析:
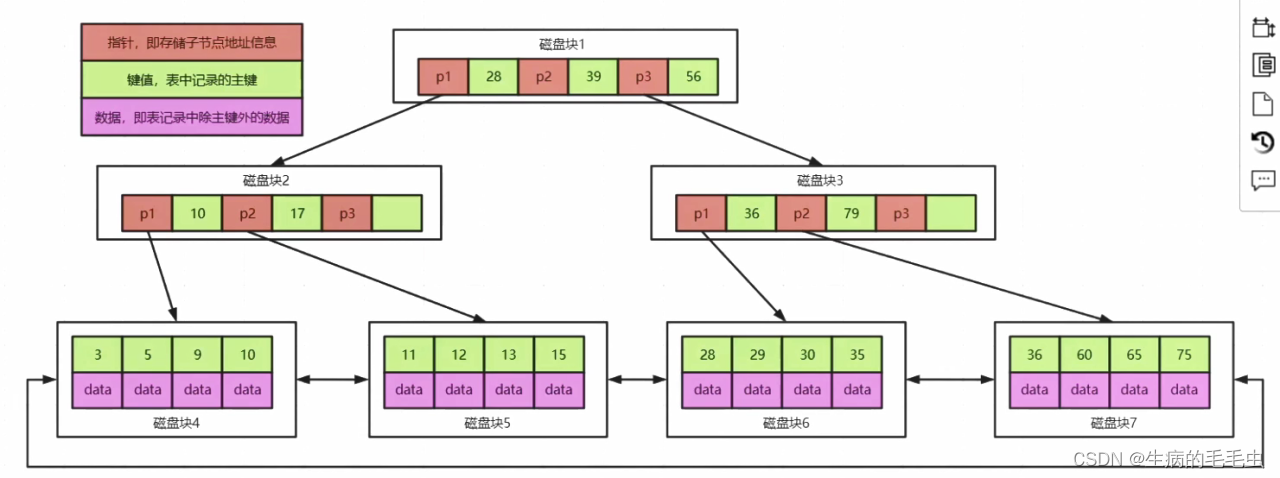
- Mysql中innoDB 使用的索引结构是B+树,
- B+ 树是B树的变种,区别在于:
- 叶子结点保存了完整的索引 & 数据,非叶子结点只保存索引值,因此他的查询时间固定为logn
- 叶子结点中有指向下一个叶子结点的指针,叶子结点类似一个双向链表
- 因为叶子结点有完整数据,并且有双链表结构,因此我们在范围查询的时候能有效提升查询效率。
- 数据都在子节点上,因此非自节点就能容纳更多的索引信息,这样就增加了同一个节点的出度,减少了数据信息,同一个节点久能容纳更多的数据信息,因此能用更少的节点来完成所有数据的索引存储,节点的减少导致减少了树的深度,查询的IO次数就变少了。
倒排索引数据结构
- 对如上两个索引结构的分析,我们能看到MySql 无法解决大数据索引问题:
- 第一点:索引往往字段很长,如果使用B+trees,树可能很深,IO很可怕
- 第二点:索引可能会失效
- 第三点:查询准确度差,
- 有如下案例,有1亿条数据的商品信息,我们需要对其中的product字段进行查询,而且是文本信息查询,例如“小米”这个字段查询,那么有如下查询语句:
select * from product where brand like "%小米 NFC 手机%"
-
第一点说明:以上查询语句,我们需要在product上建索引, MySql上使用的B+树,因为文本的信息量特别的大,导致所需要的节点就更多N个16KB(MySql索引中如果一个数据行的大小超过了页的大小16KB,MySQL 会将该行的部分数据存储在行溢出页中。这意味着数据行会被分割,一部分存储在索引页中,而溢出的部分存储在单独的溢出页中),节点数的增加,导致树深度增大查询IO次数增加

-
第二点说明:“%小米 NFC 手机%” 查询中用做匹配的方式去查询,会导致索引失效,这样导致全表扫描。
-
第三点说明:“小米 NFC 手机%” 去掉做匹配,走索引的方式,则会只查询"小米 NFC 手机"开头的,这样就会导致结果不准确
ElascitSearch索引解决方案
- 对product字段进行分词拆分,得到如下一个词项 与id的匹配关系如下

- 索引系统通过扫描文章中的每一个词,对其创建索引,指明在文章中出现的次数和位置,当用户查询时,索引系统过就会根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式,利用如上表可以快速完成全文检索
- 在为属性(product)构建倒排索引后,此时,本类别中包含了所有文档中所有字段的一个 分词(term) 文档id对应关系的字典信息通过倒排索引,我们可以迅速找到符合添加的文档,例如“手机” 在文档 1,2,3 中。
- 当我们进行Elasticsearch查询,为了能快速找到某个term在倒排表中的位置,ElasticSearch 将类型中所有的term进行排序,然后通过二分法查找term,时间复杂度能达到 logN的查找效率,就像通过字典查找一样,这就是Term Dictionary,整个是二级辅助索引
- 同时参照 B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,将term Dictionary这个构建的Mapping存放在内存中。但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,因此整个ElasticSearch的数据结构如下图
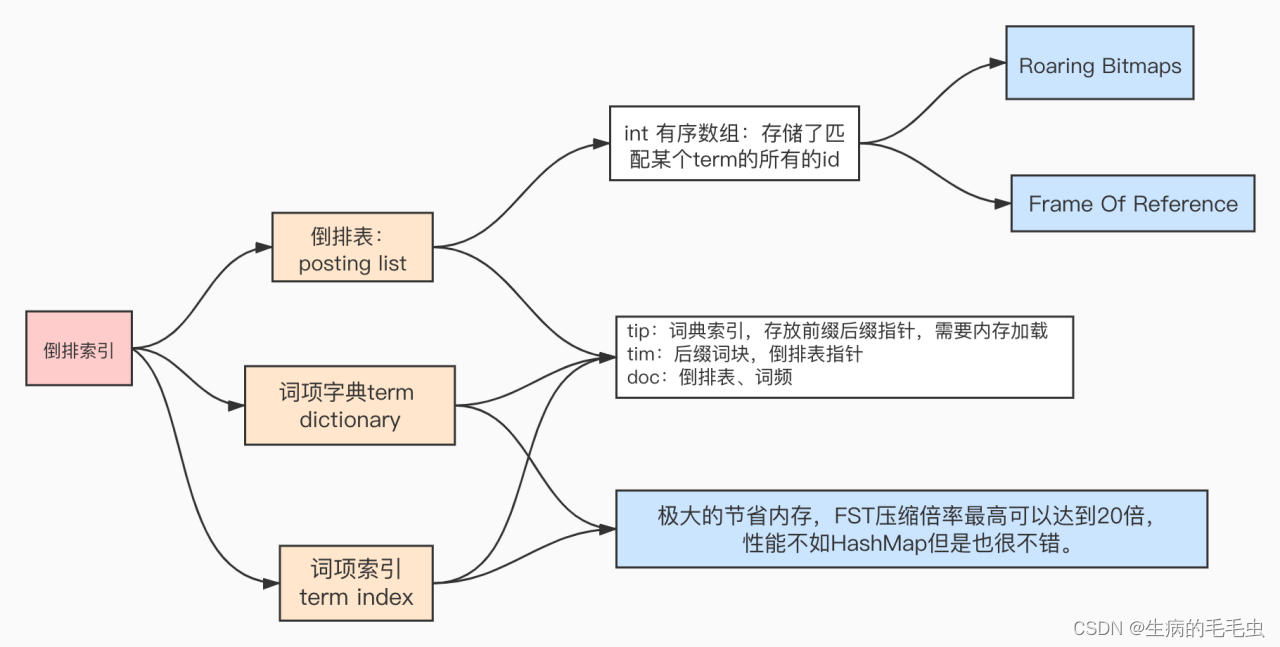
压缩算法
这篇关于Interview preparation--elasticSearch倒排索引原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





