亿个专题
一亿个数据数据一行一个数据512M内存实现排序文件写入输出文件解决办法
// private static int MAXNUM=1000; //4Kb --->1000个数据 private static int MAXNUM = 1000000000; //847M --->一亿个数据// private static int MAXNUM = 100000000; //847M --->一亿个数据// private static int

40亿个非负整数中找到出现两次的数和所有数的中位数
40亿个非负整数中找到出现两次的数和所有数的中位数 【题目】 32位无符号整数的范围是0-4294967295,现在有40亿个无符号整数,可以使用的最大内存是1GB,找出所有出现了两次的数。 【解答】 对于在很多整数中找出现次数的题,一般是使用哈希表对出现的每一个数做词频统计的。但是这个题只需要找出现2次的整数,如果还使用哈希表 key表示出现的数,value表示出现的数的次数,那

典型的Top K算法 _找出一个数组里面前K个最大数_找出1亿个浮点数中最大的10000个_一个文本文件,找出前10个经常出现的词,但这次文件比较长,说是上亿行或十亿行,总之无法一次读入内存.
Top K 算法详解 另参见http://blog.csdn.net/xiaoding133/article/details/8037086 应用场景: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个

面试题:2G内存找出20亿个整数中出现次数最多的数
空间限制:2G内存找出20亿个整数中出现次数最多的数 我们假设整数是32位,也就是4B大小的int类型 极端情况: 每个数都一样,该整数统计只需要8B大小的空间每个数都不一样,此时占用空间最大20亿 * 8B 接近 16GB 需要解决这个问题,我们可以先了解一个算法: 哈希分流: 哈希分流指的是通过哈希算法将数据或请求分散到多个处理单元上,以实现负载均衡和高效率处理的技术。在不同的应用
从两个文件(各含50亿个url)中找出共同的url、不同的url
问题: 给定a、b两个文件,各存放50亿个url,每个url各占用64字节,内存限制是4G,如何找出a、b文件共同的url? 算法思路: 方法一、 可以估计每个文件的大小为5G*64=300G (50亿是5000000000,即5G),远大于4G。 所以不可能将其完全加载到内存中处理,考虑采取分而治

12 | 有一亿个keys要统计,应该用哪种集合?
文章目录 Redis核心技术与实战实践篇12 | 有一亿个keys要统计,应该用哪种集合?聚合统计排序统计二值状态统计基数统计Redis 集合类型比较 Redis核心技术与实战 实践篇 12 | 有一亿个keys要统计,应该用哪种集合? 要想选择合适的集合,就得了解常用的集合统计模式。集合类型常见的四种统计模式,包括聚合统计、排序统计、二值状态统计和基数统计。 聚
OpenAI发布具有1750亿个参数的GPT-3 AI语言模型
论文地址:https://arxiv.org/abs/2005.14165 guthub:https://github.com/openai/gpt-3 OpenAI的一组研究人员最近发表了一篇论文,描述了GPT-3,这是一种具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍。该模型经过了将近0.5万亿个单词的预训练,并且在不进行微调的情况下,可以在多个NLP基准上达到

对一亿个数据排序时间少于1秒排序算法WaveSort
前言:干货干货,作者偶然在工作中悟出来了一种排序算法,听标题就很牛逼,下面开始一一让大家了解此算法。 一、首先我们直接与现有的排序算法:快速排序、C++库里的Sort、计数法桶排序进行速度对比 1、如图所示,这就是测试所需要的数据和方法。 2、用1000个升序数据进行排序,小于几毫秒我就不写了,直接写毫秒 C++Sort时间为:2ms,快排:2ms,波浪:1ms,桶排1ms,桶

40亿个骚扰电话,智能外呼机器人“荣登”315晚会,这口锅AI不背
AI“误入歧途”。 一天拨出5000个电话; 一年拨出超40亿个电话; 设备日活跃量5000台; 在使用设备数量3万台; …… 这些数据来源于刚刚落幕的315晚会的曝光,而被曝光的主体则是基于AI技术所研发的“外呼机器人”以及“探针盒子”,它们就是现如今骚扰电话的“元凶”。 其中,包括中科智联科技有限公司、易龙芯科人工智能有限公司、智子信息科技股份有限公司、秒嘀科技等在内的多家公
40亿个骚扰电话,智能外呼机器人“荣登”315晚会,这口锅AI不背...
AI“误入歧途”。 一天拨出5000个电话; 一年拨出超40亿个电话; 设备日活跃量5000台; 在使用设备数量3万台; …… 这些数据来源于刚刚落幕的315晚会的曝光,而被曝光的主体则是基于AI技术所研发的“外呼机器人”以及“探针盒子”,它们就是现如今骚扰电话的“元凶”。 其中,包括中科智联科技有限公司、易龙芯科人工智能有限公司、智子信息科技股份有限公司、秒嘀科技等在内的多家公

菜鸟末端轨迹 - 电子围栏(解密支撑每天251亿个包裹的数据库) - 阿里云RDS PostgreSQL最佳实践
菜鸟末端轨迹 - 电子围栏(解密支撑每天251亿个包裹的数据库) - 阿里云RDS PostgreSQL最佳实践 作者 digoal 日期 2017-08-03 标签 PostgreSQL , PostGIS , 多边形 , 面 , 点 , 面点判断 , 菜鸟 背景 菜鸟末端轨迹项目中涉及的一个关键需求,面面判断。 在数据库中存储了一些多边形记录,约几百万到千万条记录,例如一

结构体数组所有元素(1亿个元素)初始化为相同的值
一个结构体数组,有1亿个元素,每个元素都要初始化为相同的值,如果没有现成的语法直接支持这样的初始化操作,就得用for循环写,会不会非常耗时? 如果结构体里的成员都是一些简单的基本数据类型,整个结构体才几十个字节,即使有1亿个元素,用for循环赋值,程序执行时间也只要10^8纳秒级别,0.1秒的样子。编译器优化+高速缓存命中,速度已经飞快了,不用操心那么多。循环展开这些优化方法,编译器优化都可能帮

快速查找一个数字是否出现在40亿个数字中
1.问题描述 给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中 2.解决方法 这个问题在《编程珠玑》里有很好的描述,大家可以参考下面的思路,探讨一下: 又因为2^32为40亿多,所以给定一个数可能在,也可能不在其中; 这里我们把40亿个数中的每一个用32位的二进制来表示 假设这40亿个数开始放在一个文件中。 然后将这40
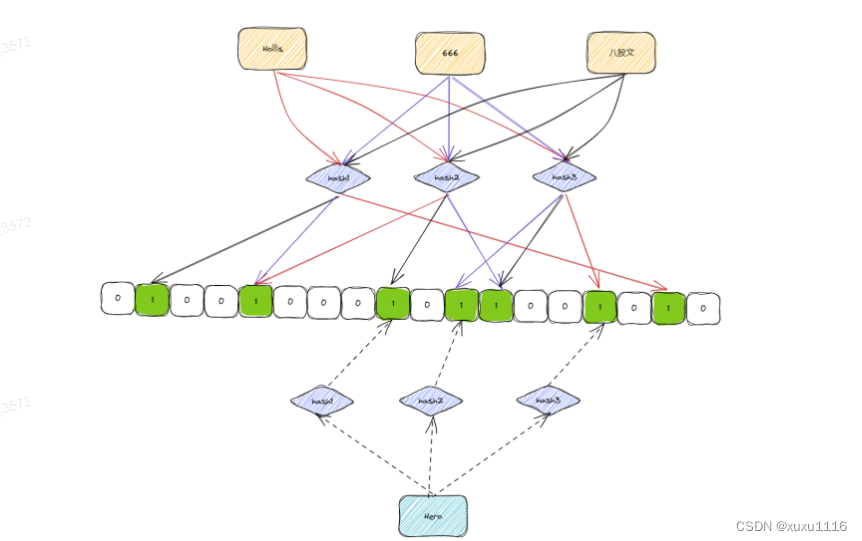
面试题:40亿个QQ号,限制1G内存,如何去重?
文章目录 概要什么是BitMap?有什么用?什么是布隆过滤器,实现原理是什么?应用场景如何使用 概要 40亿个unsigned int,如果直接用内存存储的话,需要: 4*4000000000 /1024/1024/1024 = 14.9G ,考虑到其中有一些重复的话,那1G的空间也基本上是不够用的。 想要实现这个功能,可以借助位图。 使用位图的话,一个数字只需要占用1个

马杜罗下令发行一亿个以石油储备为价值支撑的加密货币Petro
点击上方 “蓝色字” 可关注我们! 暴走时评: 委内瑞拉总统马杜罗在确定发行国家加密货币petro之后便创建了相关的技术及货币监管。最近详述介绍了petro的挖矿等事宜。本月他下令发行一亿个petro,号召组织petro矿工首届全国会议,并会在会上发布新货币白皮书。对于这些货币将以国内石油储备为支撑的说法,遭到以国内出油储备相关法律为
面试题:从10亿个随机整数中,找出前1000个最大数
题目描述 从10亿个随机整数中,找出前1000个最大数,要求以最小的时间复杂度及空间复杂度实现该需求。 解题思路 这道题的解决思路是将无序整数排列为有序序列,升序或降序,从中取出前1000个最大数。适用的排序算法包括: 插入排序、选择排序、冒泡排序、快速排序等,时间复杂度:堆排序、归并排序,时间复杂度: 本题需要实现的是找出前1000个最大数,空间上可以只做1000条最大目标数组,

【Bitmap】在20亿个随机整数中找出m是否存在,你打算用什么算法呢?
嗨,大家好,我是一条。 告诉大家一个好消息,一条IT访问量突破20w,达到申请博客专家的条件。感谢大家的支持,一条会创作更多的优质内容。 为了让更多的人看到一条的分享,一条准备报名原力计划,报名条件是粉丝数超过2000。 所以一条现在非常需要大家的关注,如果觉得一条写的还可以,就点个关注再走吧! 等粉丝数达到2000时,一条给大家在微信准备一个抽奖,奖品暂定键盘和手环二选一。关注微信

Java算法之 排一亿个随机数
前言 插入排序狭义上指的是简单插入排序(选择集合,比较大小,插入元素),广义上还应该包括希尔排序(分治思想)及其两种实现方式, 最激动人心的是 , 希尔排序(移位法)的效率奇高, 在本地调试中,一亿 个随机数仅需30S即可排完 (不同机器可能结果不同) ,在数据量较大时效率是比堆排序要高的 结果在希尔排序移位法的第3点中 , 可以直接跳转查看 下面将介绍这几种排序方式及其同异点 提示
1 亿个数据取出最大前 100 个有什么方法?
1 亿个数据取出最大前 100 个有什么方法? 大家好,这是一道经常在面试中被遇到的一个问题,我之前面试也是被问到过得,现在一起学习下,下次再被问到就可以轻松地用对。 在计算机科学和数据处理领域,我们经常会遇到需要从海量的数据中找出最大或最小的若干个元素的情况。本文将以 Java 为例,介绍几种从 1 亿个数据中取出最大前 100 个的方法。 方法一:排序后取前 100 个 最直观的方法是

你会不会排序 | 腾讯三面:40亿个QQ号码如何去重?
来源 | 爱码有道 今天,我们来聊一道常见的考题,也出现在腾讯面试的三面环节,非常有意思。具体的题目如下: 文件中有40亿个QQ号码,请设计算法对QQ号码去重,相同的QQ号码仅保留一个,内存限制1G。 这个题目的意思应该很清楚了,比较直白。为了便于大家理解,我来画个动图玩玩,希望大家喜欢。 能否做对这道题目,很大程度上就决定了能否拿下腾讯的offer,有一定的技巧性,一起来看

腾讯二面:20亿个QQ号码如何去重?
背景 之前找工作在腾讯面试遇到了一个很有意思的面试题,当时我记得现场还没有答出来,后来回家想了一下其实也没有那么难,而且还挺有意思的,今天做个整理分享给大家,希望对你有用 题目如下 文件中有20亿个QQ号码,请设计算法对QQ号码去重,相同的QQ号码仅保留一个,内存限制1G. 这个题目的意思应该很清楚了,不过为了方便大家理解,我画了一个比较有年代感的动画,希望大家喜欢 方法一 排序去重
菜鸟末端轨迹 - 电子围栏(解密支撑每天251亿个包裹的数据库) - 阿里云RDS PostgreSQL最佳实践
菜鸟末端轨迹 - 电子围栏(解密支撑每天251亿个包裹的数据库) - 阿里云RDS PostgreSQL最佳实践 作者 digoal 日期 2017-08-03 标签 PostgreSQL , PostGIS , 多边形 , 面 , 点 , 面点判断 , 菜鸟 背景 菜鸟末端轨迹项目中涉及的一个关键需求,面面判断。 在数据库中存储了一些多边形记录,约几百万到千万条记录,例如一

菜鸟末端轨迹(解密支撑每天251亿个包裹的数据库)
背景 菜鸟末端轨迹项目中涉及的一个关键需求,面面判断。 在数据库中存储了一些多边形记录,约几百万到千万条记录,例如一个小区,在地图上是一个多边形。 不同的快递公司,会有各自不同的多边形划分方法(每个网点负责的片区(多边形),每个快递员负责的片区(多边形))。 用户在寄件时,根据用户的位置,查找对应快递公司负责这个片区的网点、或者负责该片区的快递员。 一、需求 1、在数据
菜鸟末端轨迹(解密支撑每天251亿个包裹的数据库) - 阿里云RDS PostgreSQL最佳实践...
标签 PostgreSQL , PostGIS , 多边形 , 面 , 点 , 面点判断 , 菜鸟 背景 菜鸟末端轨迹项目中涉及的一个关键需求,面面判断。 在数据库中存储了一些多边形记录,约几百万到千万条记录,例如一个小区,在地图上是一个多边形。 不同的快递公司,会有各自不同的多边形划分方法(每个网点负责的片区(多边形),每个快递员负责的片区(多边形))。 用户在寄件时,根据用户的位
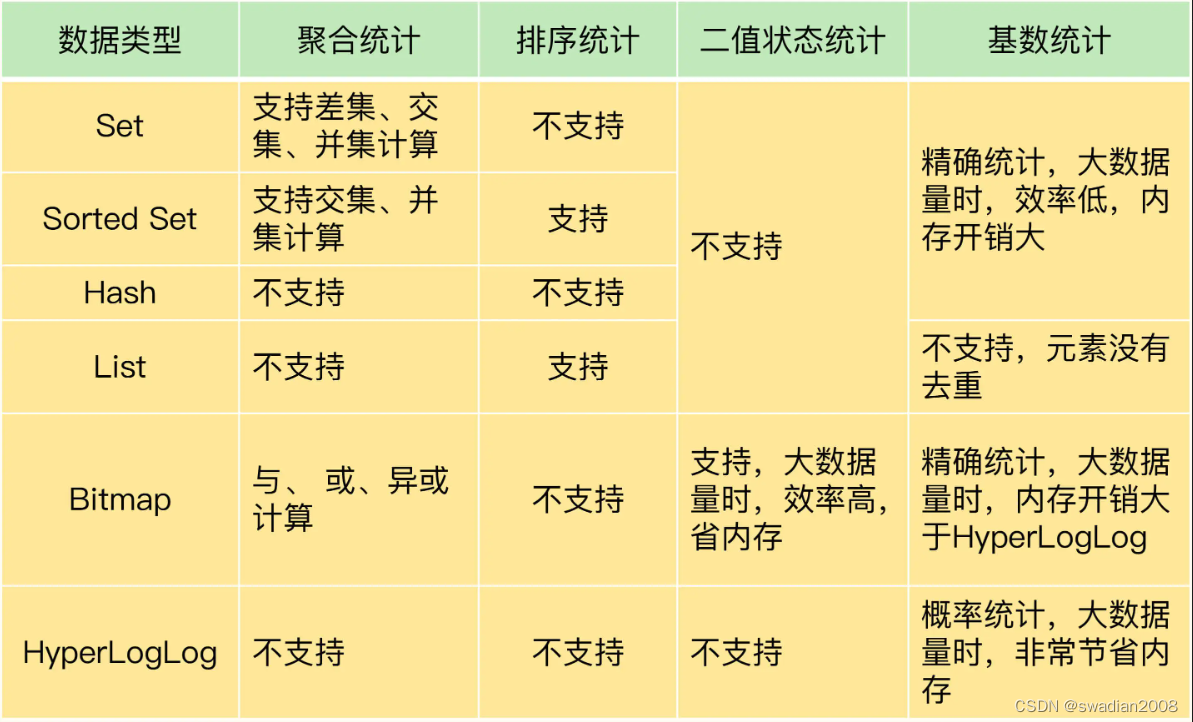
使用 Redis 如何统计一亿个 keys ?
目录 1、聚合统计 2、排序统计 3、二值状态统计 4、基数统计 总结 // 淡泊明志,宁静致远 在 Web 和移动应用的业务场景中,我们经常需要保存这样一种信息:一个 key 对应了一个数据集合。举几个例子: 手机 App 中的每天的用户登录信息:一天对应一系列用户 ID 或移动设备 ID;电商网站上商品的用户评论列表:一个商品对应了一系列的评论;用户在手
使用 Redis 如何统计一亿个 keys ?
目录 1、聚合统计 2、排序统计 3、二值状态统计 4、基数统计 总结 // 淡泊明志,宁静致远 在 Web 和移动应用的业务场景中,我们经常需要保存这样一种信息:一个 key 对应了一个数据集合。举几个例子: 手机 App 中的每天的用户登录信息:一天对应一系列用户 ID 或移动设备 ID;电商网站上商品的用户评论列表:一个商品对应了一系列的评论;用户在手