二十七专题

每天一个数据分析题(五百二十七)- word2vec模型
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。关于word2vec模型,下面说法不正确的是: A. 得到的词向量维度小,可以节省存储和计算资源 B. 考虑了全局语料库的信息 C. 无法解决多义词的问题 D. 可以表示词和词之间的关系 数据分析认证考试介绍:点击进入 数据分析考试大纲下载 题目来源于CDA模拟题库 点

leetcode解题思路分析(二十七)193 - 199题
有效电话号码 给定一个包含电话号码列表(一行一个电话号码)的文本文件 file.txt,写一个 bash 脚本输出所有有效的电话号码。你可以假设一个有效的电话号码必须满足以下两种格式: (xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一个数字)你也可以假设每行前后没有多余的空格字符。 正则表达式的重点有三:特殊字符、限定字符、定位符 表达 (xxx) xxx-xxxx

Linux操作系统学习笔记(二十七)磁盘I/O性能优化
一. 前言 本文是性能优化系列的最后一篇,将分析磁盘I/O的性能指标、测试方法、常见问题的优化套路等内容。 二. I/O性能指标及查询工具 磁盘性能的衡量标准经常用到的包括使用率、饱和度、IOPS、吞吐量以及响应时间等。这五个指标是衡量磁盘性能的基本指标。 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。饱和度,是指

【Unity 3D】学习笔记二十七:unity游戏脚本(七)
使用C#编写游戏脚本 在前面提到,unity支持三种语言编写脚本:js,C#,boo。入门的时候建议只用js,因为js比较简单易懂,语法也不是很严格。但后来晋级的时候推荐使用C#,因为它比较符合unity的编程思想,执行效率更高。下面总结下怎么使用C#编写脚本。 继承MonoBehaviour类 在unity中,任何一个脚本,包括上述三种语言都需要去继承MonoBehaviour
OpenGL学习笔记(二十七)
目录 混合 混合 在OpenGL中,物体透明技术通常被叫做混合(Blending)。透明是物体(或物体的一部分)非纯色而是混合色,这种颜色来自于不同浓度的自身颜色和它后面的物体颜色。一个有色玻璃窗就是一种透明物体,玻璃有自身的颜色,但是最终的颜色包含了所有玻璃后面的颜色。这也正是混合这名称的出处,因为我们将多种(来自于不同物体)颜色混合为一个颜色,透明使得我们可以看穿物体。

Python基础教程(二十七):urllib模块
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 💝💝💝如有需要请大家订阅我的专栏【Python系列】哟!我会定期更新相关系列的文章 💝💝💝关注!关注!!请关注!!!请大家关注下博主,您的支持是我不断创作的最大动力!!! 文章目录 引言一、urllib.request:发送网络请求1

汽车IVI中控开发入门及进阶(二十七):车载摄像头vehicle camera
前言: 在车载IVI、智能座舱系统中,有一个重要的应用场景就是视频。视频应用又可分为三种,一种是直接解码U盘、SD卡里面的视频文件进行播放,一种是手机投屏,就是把手机投屏软件已视频方式投屏到显示屏上显示,另外一种就是对视频采集设备(主要就是摄像头Camera)的视频源进行解析解码显示。随着汽车智能化大趋势的演进,车载摄像头也是越来越多,所以对于这一块的视频处理需求也就越来越旺盛。 根据安装

二十七、 如何确定数据出境安全评估的申报主体?
根据《评估办法》第二条,数据出境安全评估的申报主体为向境外提供在中华人民共和国境内运营中收集和产生的重要数据和个人信息的数据处理者。 值得注意的是,根据《评估申报指南(第二版)》和《标准合同备案指南(第二版)》规定,未在中国境内设立办事机构或分支机构的境外主体如果向境内自然人提供产品服务,构成在境外处理中国境内自然人个人信息的情况,那么当其符合法定需要申报数据出境安全评估的情形时,也应遵

Python代码:二十七、append函数
1、题目 牛牛有一个name = ['Niumei', 'YOLO', 'Niu Ke Le', 'Mona'] 记录了他最好的朋友们的名字,请创建一个二维列表friends,使用append函数将name添加到friends的第一行。 假如Niumei最喜欢吃pizza,最喜欢数字3,YOLO最喜欢吃fish, 最喜欢数字6,Niu Ke Le最喜欢吃potato,最喜欢数字0,Mona最喜
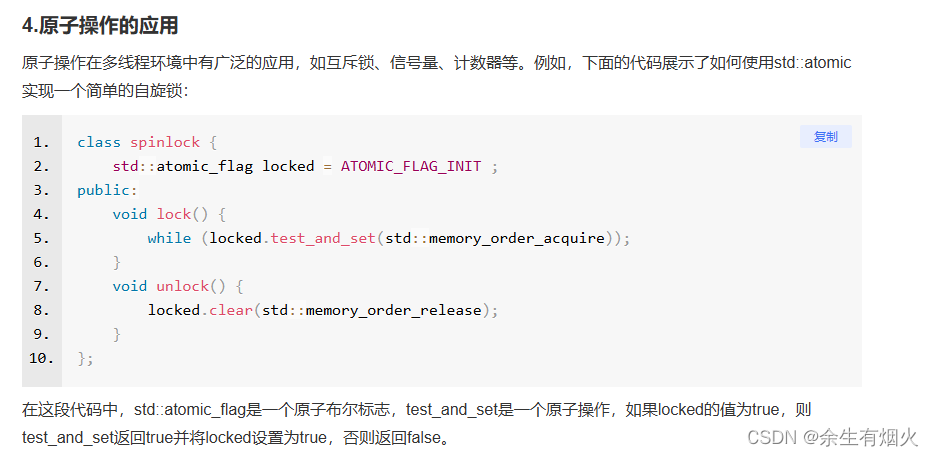
面试二十七、 CAS和Atomic
CAS锁机制(无锁、自旋锁、乐观锁、轻量级锁)-CSDN博客 1. ABA问题 在C++中,可以使用std::atomic和版本号来解决ABA问题。C++标准库没有直接提供类似Java的AtomicStampedReference,但可以通过将版本号和指针组合在一起实现类似的效果。 #include <atomic>#include <iostream>#include <t
面试二十七、异步的日志
日志消息的写入操作在一个独立的线程中进行,而不是在调用log函数的主线程中进行。这意味着主线程可以继续执行其他任务,而不需要等待日志消息写入完成。这提高了程序的性能和响应速度,特别是在日志写入操作耗时较长的情况下。 #include <iostream>#include <fstream>#include <string>#include <thread>#include
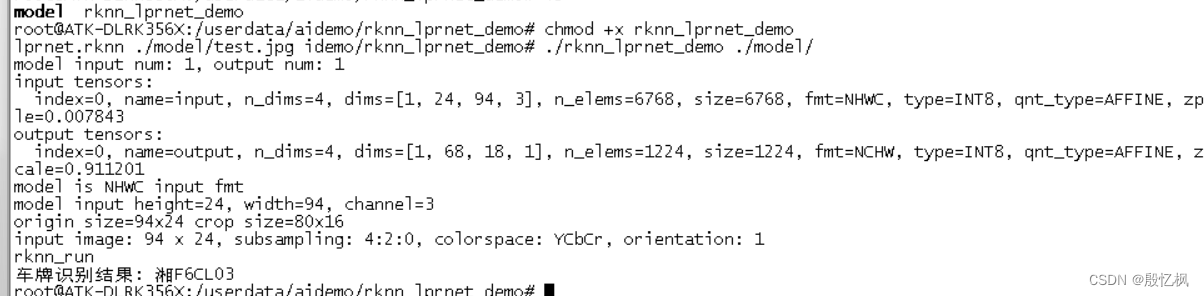
RK3568笔记二十七:LPRNet车牌识别
若该文为原创文章,转载请注明原文出处。 记录自训练并在RK3568上部署。 一、介绍 LPRNet的Pytorch实现,一种高性能和轻量级的车牌识别框架。完全适用于中国车牌识别(Chinese License Plate Recognition)及国外车牌识别! 目前仅支持同时识别蓝牌和绿牌,即新能源车牌等中国车牌,但可通过扩展训练数据或微调支持其他类型车牌及提高识别准确率! 该网络的特点
嵌入式linux开发 (二十七) 存储管理(1)从flash到内存
本文主要参考代码 执行方式 嵌入式系统中代码的执行方式主要有3种:1.完全映射(fully shadowed)。嵌入式系统程序运行时,将所有的代码从非易失存储器(Flash、ROM等)复制到RAM中运行。例子:s3c2440的nandflash和i.mx6ull的sd卡2.按需分页(demand paging)。只复制部分代码到RAM中。这种方法对RAM中的页进行导入导出管理,如果访问位于
emacs for Mac命令(二十七)
在Mac上装了emacs,由于Mac OS和键盘不同,emacs的命令也有差异,在这里记录下备忘,并持续更新... C代表control S代表shift O代表option 1、选中一段文字 C + S + 2 // 标记 C + a/e //向前、后选中 注:在.emacs加入:global-set-key (kbd"C-q") 'set-mark-command)
汉译英早操练-(二十七)
hello,汉语在表达成英语的时候你是否有困惑。不要着急,一起来看看需要我们注意一些什么,慢慢的就不恐惧用英语表达汉语这件事了。给大家奉献系列文章,供大家参考学习。 往期回顾在这里,请随便点击过去查看,(#^.^#) 汉译英早操练-(十九)-CSDN博客 汉译英早操练-(二十)-CSDN博客 汉译英早操练-(二十一)-CSDN博客 汉译英早操练-(二十

政安晨:【Keras机器学习示例演绎】(二十七)—— 利用 NNCLR 进行自我监督对比学习
目录 简介 自我监督学习 对比学习 NNCLR 设置 超参数 加载数据集 增强 准备扩增模块 编码器结构 用于对比预训练的 NNCLR 模型 预训练 NNCLR 政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras机器学习实战 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本文目标:计
软考之零碎片段记录(二十七)+复习巩固(十三、十四)
学习 1. 案例题 涉及到更新的。肯能会是数据流的终点E, P, D 数据流转。可能是 P->EP->D(数据更新)P->P(信息处理)D->P(提取数据信息) 2. 案例2 补充关系图时会提示不增加新的实体。则增加关联关系 3. 案例3 用例图 extend用于拓展,当一个用例混合两种场景,可将用例分为一个基本用例或多个拓展用例include提取出两个用例的公共部分。 4.
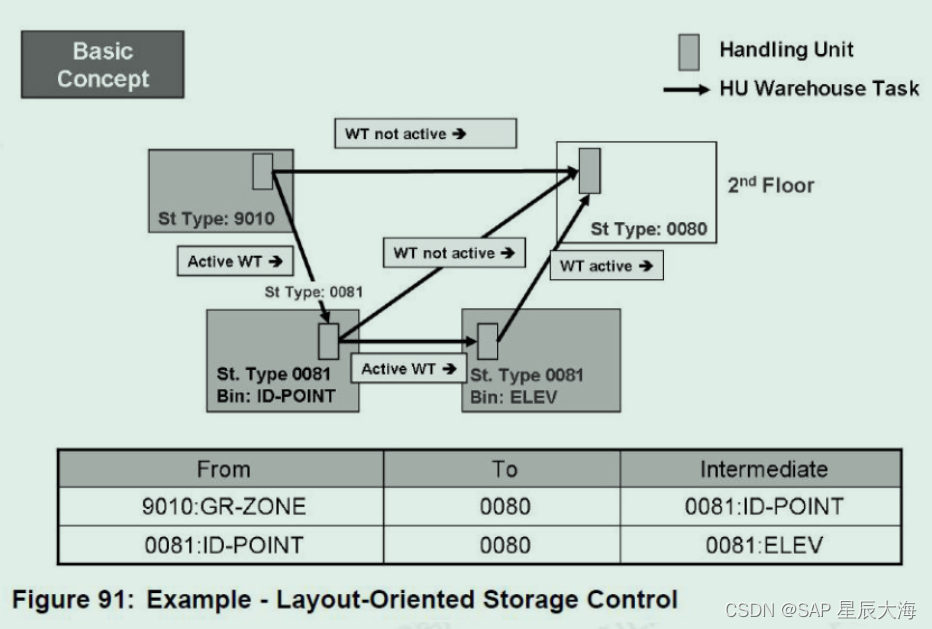
【学习笔记二十七】EWM存储类型控制
一、EWM存储类型控制概述 Storage control 是用来决定仓库产品移动时所需要的流程步骤。它的目的是用来处理基于仓库物理布局及仓库流程所要求的复杂的上架和下架流程步骤。 仓库里常见的操作步骤有:Picking、Packing、Staging、Loading、Putaway、Unloading、Counting、Quality Inspection、D
【Visual C++】游戏开发笔记二十七 Direct3D 11入门级知识介绍
上一节里我们介绍了在迈入DirectX 11的学习旅程之后第一个demo创建的全过程。但由于知识衔接的需要,我们的第一个demo里面涉及到的大部分知识都是关于Win32的。而为了使之前讲解的Blank Win32 Window Demo蜕变成我们期望的Direct3D的模样,我们将在这节的笔记里面对Direct3D的入门级的基础知识做一个详细的介绍,以便在下节笔记里轻车熟路地写出属于我们的第一个完
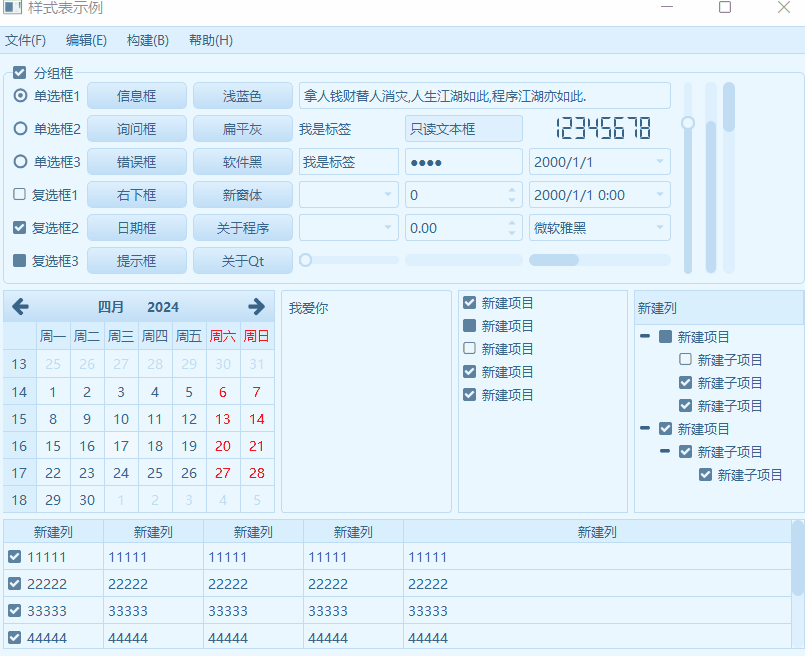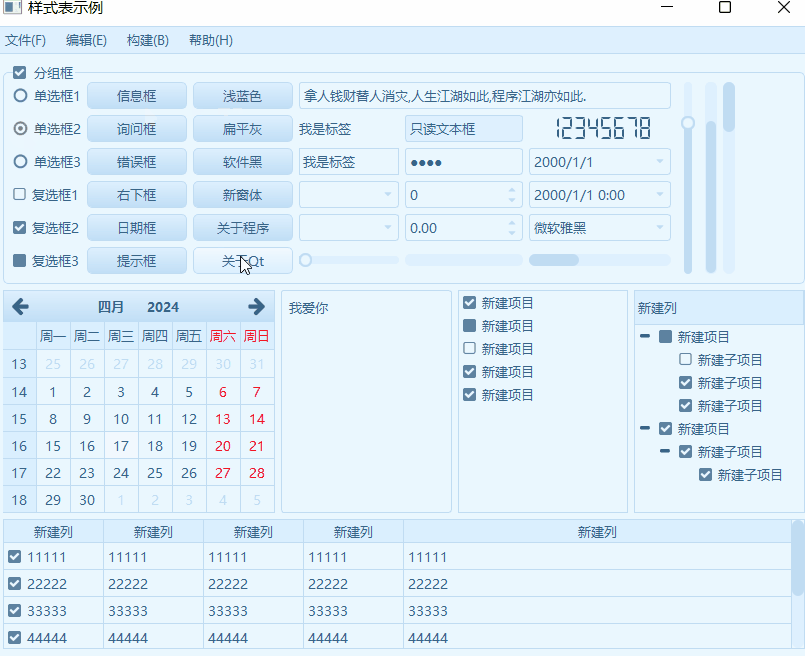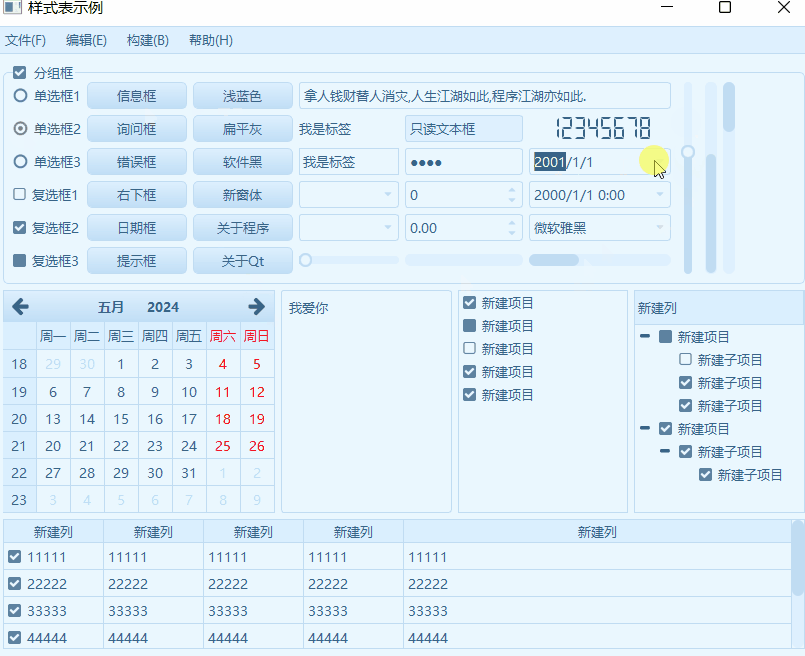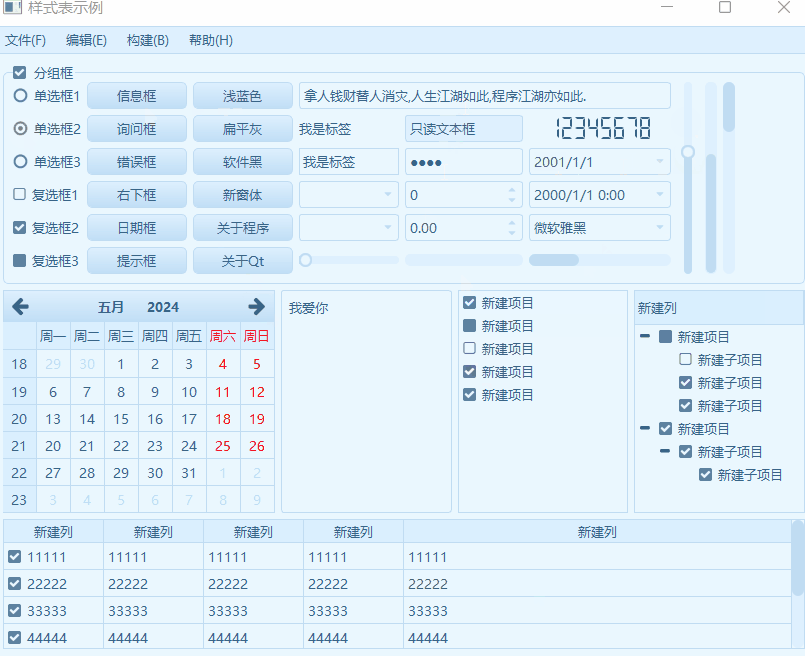
《QT实用小工具·二十七》各种炫酷的样式表
1、概述 源码放在文章末尾 该项目实现了各种炫酷的样式表,如单选、多选、按钮、日历、表格、下拉框、滚轮等,下面是项目demo演示: 项目部分代码如下: #include "frmmain.h"#include "ui_frmmain.h"#include "head.h"frmMain::frmMain(QWidget *parent) : QMainWindow(parent), u
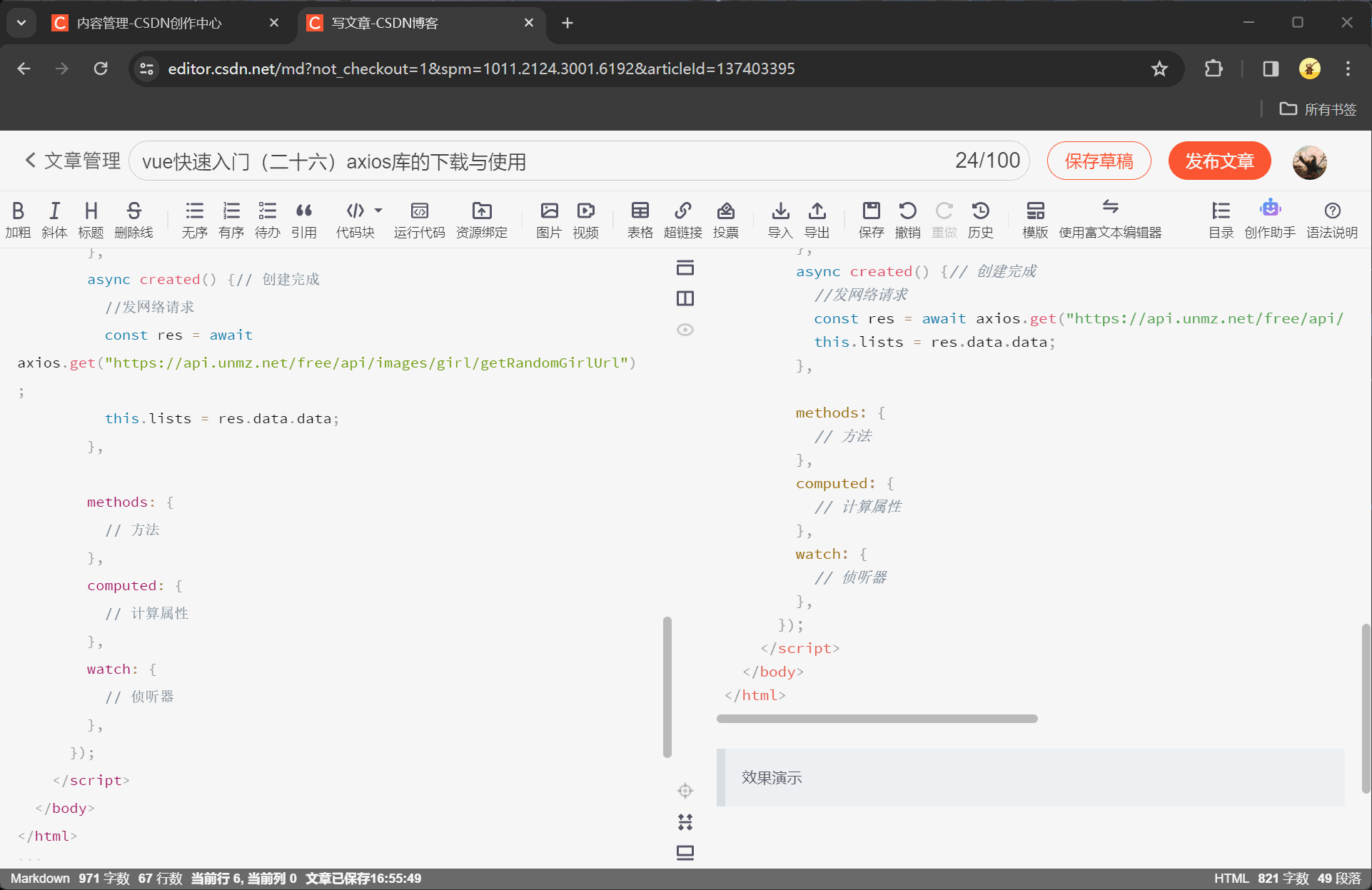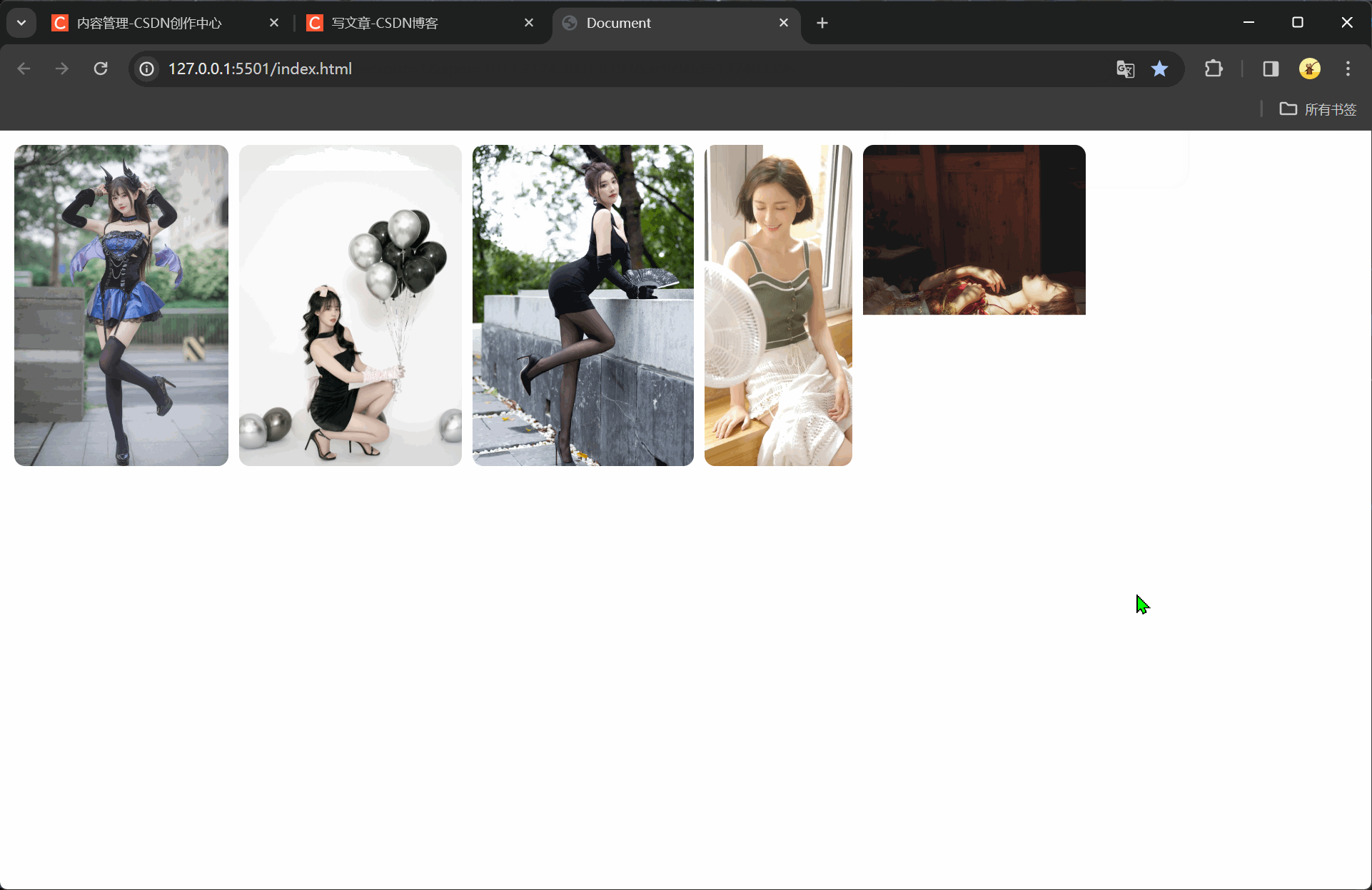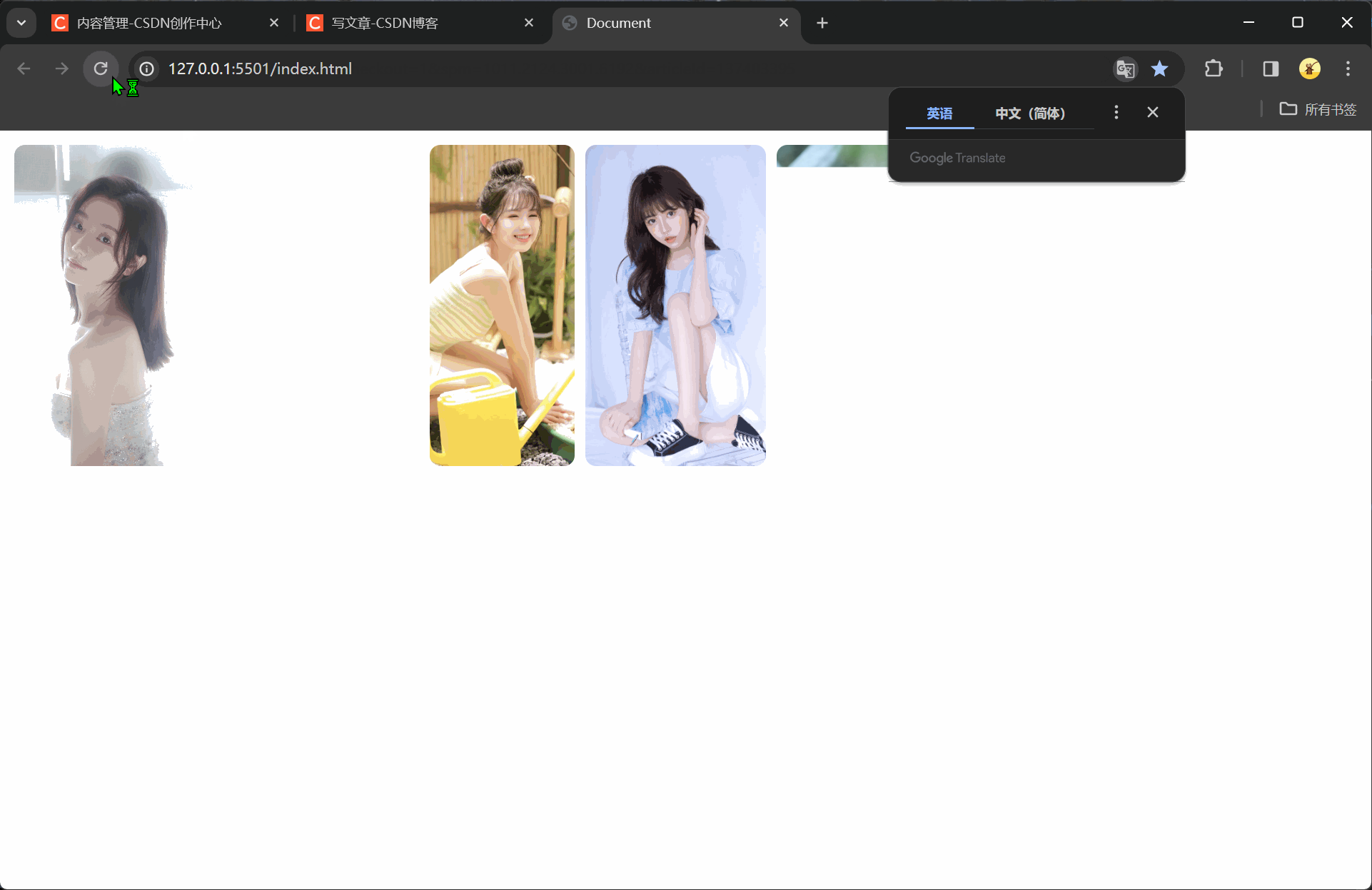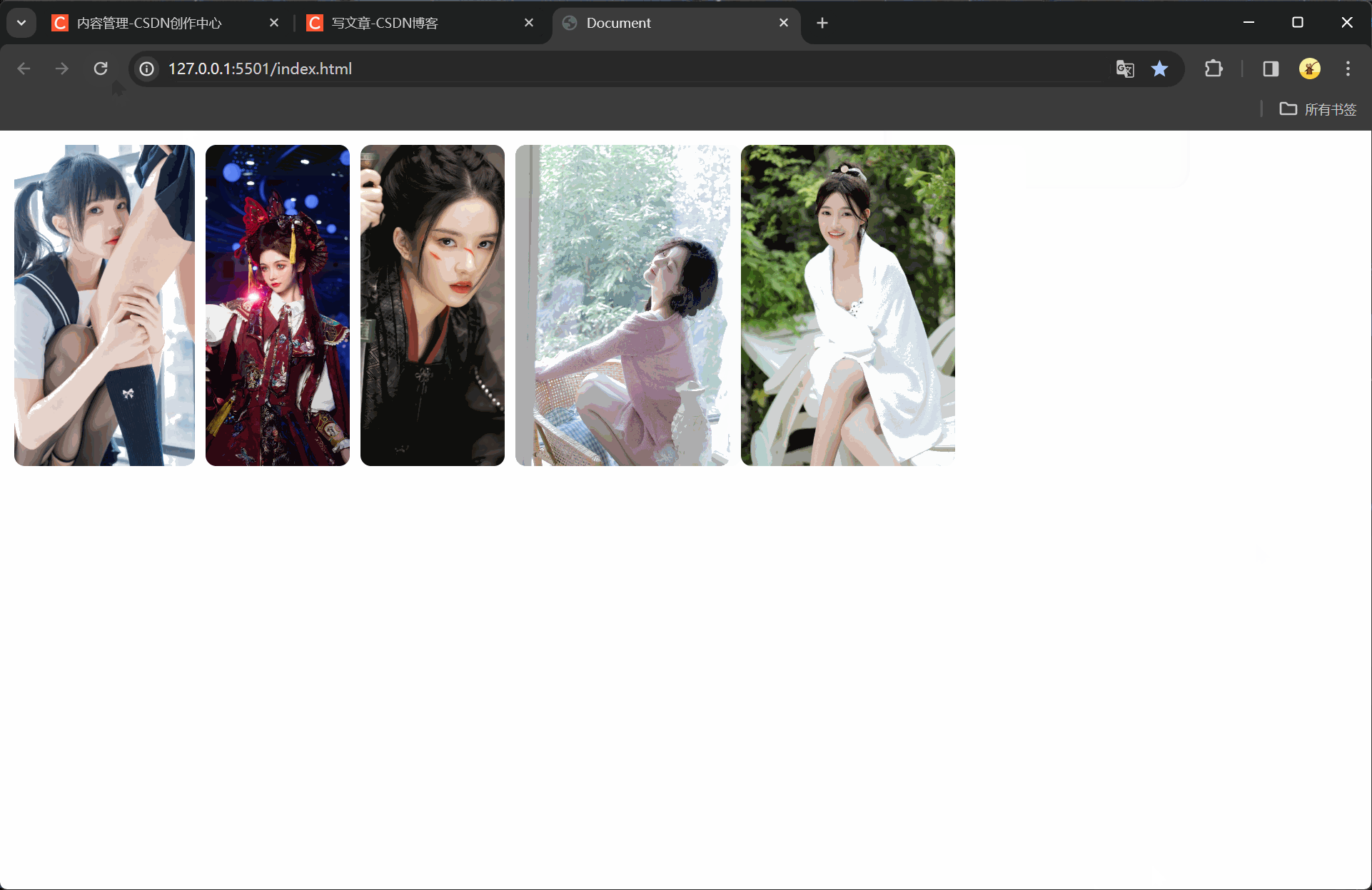
vue快速入门(二十七)axios库的下载与使用
注释很详细,直接上代码 上一篇 新增内容 axios.js文件的下载与导入axios请求的使用与解析赋值 官网不科学上网太慢,csdn资源审核太慢,so我传自己主机了(访问不了@我) axios.js文件 自己下载一下吧 源码 <!DOCTYPE html><html lang="en"><head><meta charset="UTF-8" /><meta nam
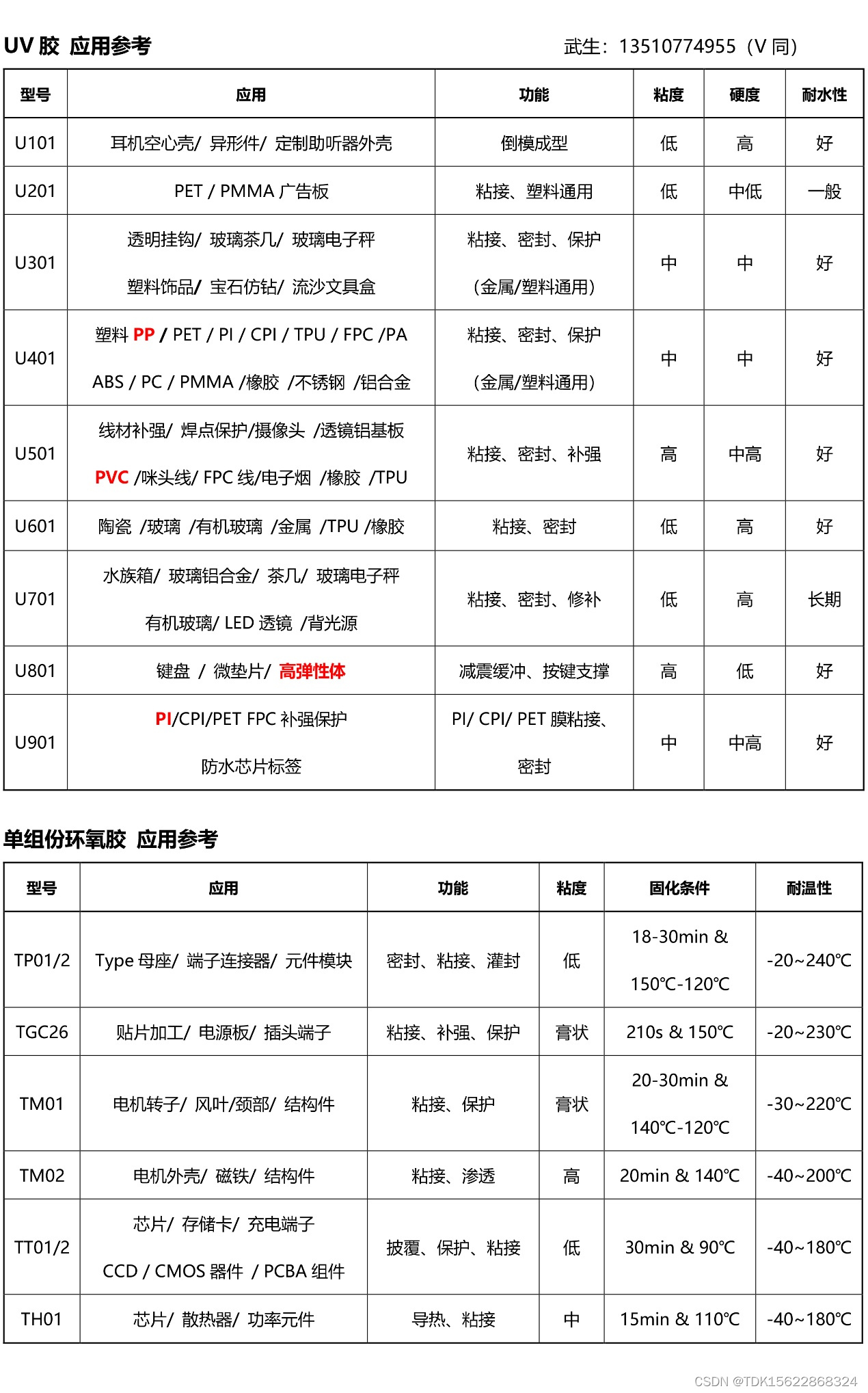
聚酰亚胺PI材料难于粘接,用什么胶水粘接?那么让我们先一步步的从认识它开始(二十七): 聚酰亚胺PI材料难于粘接,有什么可以解决粘接问题的方案呢?
聚酰亚胺PI材料难于粘接,有什么可以解决粘接问题的方案呢? 聚酰亚胺(PI)材料由于其特殊的物理和化学性质,的确在粘接方面存在挑战。为了克服这些问题,以下是一些可能的解决方案: 表面处理:对PI薄膜表面进行改性处理,如酸碱处理、等离子处理、离子束法或表面接枝改性,这些方法可以有效地改善其表面的粘接性能。通过改变PI材料表面的化学性质或物理结构,增加其与粘合剂之间的相互作用,从而提高
2024年150道高频Java面试题(二十七)
53. 什么是 Java 中的死锁?如何避免? Java中的死锁是指两个或两个以上的线程因为竞争资源而造成的一种僵持状态,每个线程都在等待其他线程释放锁,但是这些锁又被其他线程持有,导致没有任何线程能继续执行下去,形成一种循环等待的局面。 死锁通常发生在以下四个条件同时满足时: 互斥条件:资源不能被多个线程共同使用,只能由一个线程独占。占有且等待条件:线程至少持有一个资源,并且正在等待获取额
量化交易入门(二十七)回撤、收益率、夏普比率
回撤 一、回撤的定义与计算 回撤是指投资组合或交易账户从历史最高点下跌到后来最低点的幅度,通常用百分比表示。计算公式为: 回撤 = (历史最高净值 - 当前净值) / 历史最高净值 × 100% 例如,某策略历史最高净值为150万,当前净值跌到了100万,则回撤为:(150-100)/150×100%=33.33% 二、回撤的分类 最大回撤:是指账户或策略在一段时间内(通常指回测或实盘
每天一个数据分析题(二百二十七)
进行超参数调参时,当处理连续的数值型超参数时,随机搜索(Randomized Search)相较于网格搜索(Grid Search)的一个主要优势是什么? A. 随机搜索仅考虑整数值。 B. 随机搜索可以更均匀地探索整个参数空间。 C. 随机搜索在数值型参数上可以进行无限的采样。 D. 随机搜索总是返回全局最佳解。 题目来源于CDA模拟题库 点击此处获取答案
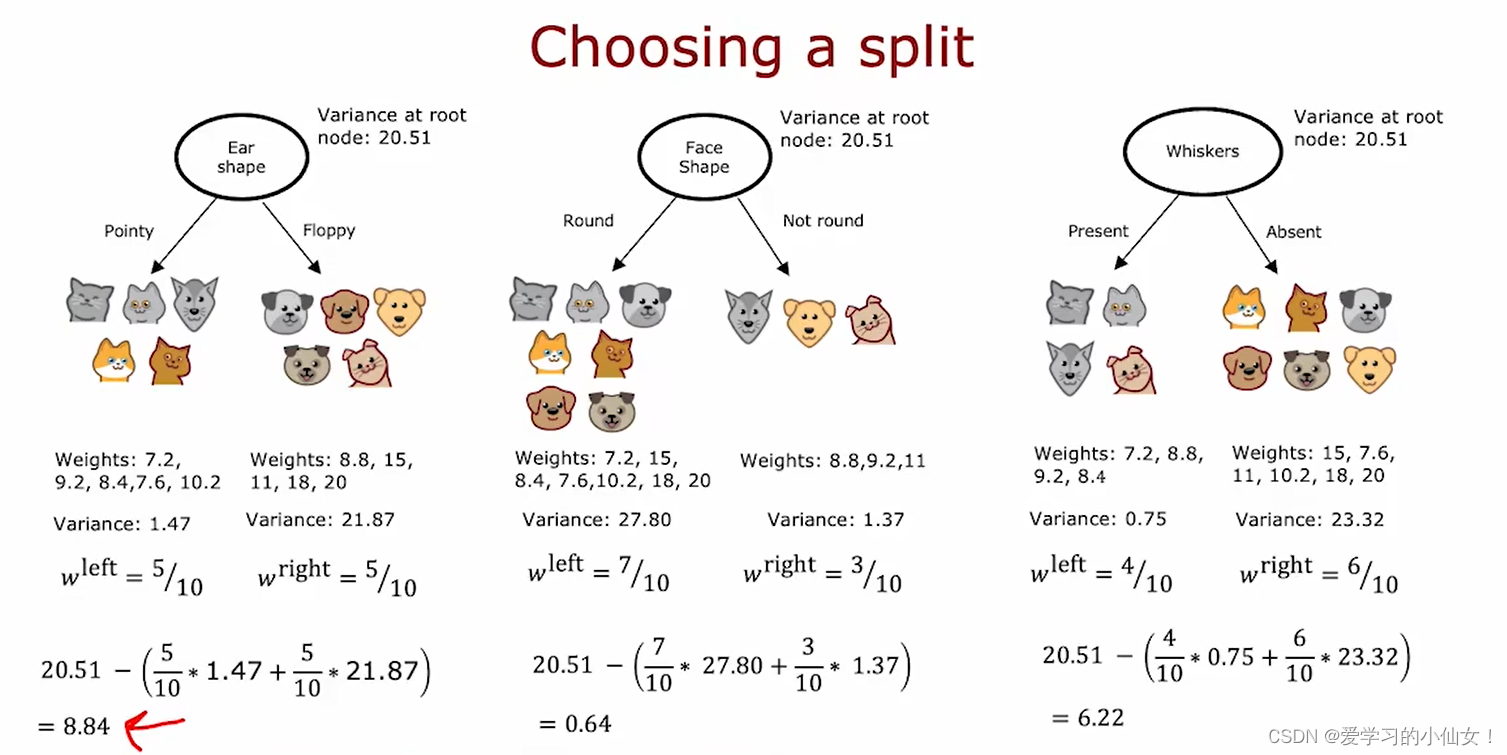
吴恩达机器学习笔记 二十七 决策树中连续值特征的选择 回归树
还是猫狗分类的案例,假如再增加一个特征weight,该值是一个连续的值,如何在决策树中使用该特征? 如下图所示,尝试不同的阈值,如 weight<=9 , 此时左边有四个样本,都为猫,右边有六个样本,其中一个为猫,计算信息增益(绿色的那个)。同理,把条件设为weight<=8,划分后左边有两个样本,全是猫,右边有八个样本,其中三个是猫,计算信息增益(蓝色的那个),可以发现边界设为