xgboost专题
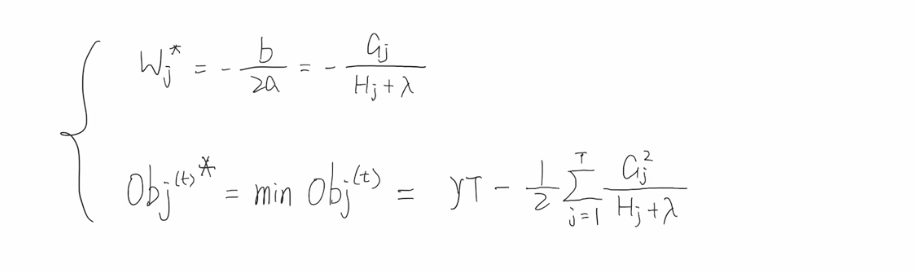
XGBoost算法-上
简单解释一下xgboost这个模型 xg是一个非常强大,非常受欢迎的机器学习模型,其中最大的特色就是boosting(改进、推进),怎么改进呢?就是xgboost这个算法,它会先建立一颗简单的决策树,然后看这个决策树的预测结果,有哪些地方算错了,针对这些错误,来进行一些改进,又拿到一颗决策树,然后看第二颗决策树预测结果又哪些地方错了,然后再根据这些错误再做一些改进,通过这一次次的快速的改进,将错

【机器学习】XGBoost的用法和参数解释
一、XGBoost的用法 流程: 代码案例: 二、XGBoost的几大参数 1、一般参数,用于集成算法本身 ①n_estimators 集成算法通过在数据上构建多个弱 评估器,汇总所有弱评估器的建模结果,以获取比单个模型更好的回归或分类表现。sklearn中n_estimators表示弱评估器的个数,在xgboost中用num_boost_round表示,是xgboost.tr

回归预测 | Matlab基于贝叶斯算法优化XGBoost(BO-XGBoost/Bayes-XGBoost)的数据回归预测+交叉验证
回归预测 | Matlab基于贝叶斯算法优化XGBoost(BO-XGBoost/Bayes-XGBoost)的数据回归预测+交叉验证 目录 回归预测 | Matlab基于贝叶斯算法优化XGBoost(BO-XGBoost/Bayes-XGBoost)的数据回归预测+交叉验证效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现基于贝叶斯算法优化X

数据分析:R语言计算XGBoost线性回归模型的SHAP值
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍SHAP用途计算方法:应用 加载R包导入数据数据预处理函数模型 介绍 SHAP(SHapley Additive exPlanations)值是一种解释机器学习模型预测的方法。它基于博弈论中的Shapley值概念,用于解释任何机器学习模型的输出。 SHAP用途 解释性:机器学习模型

Kaggle刷比赛的利器,LR,LGBM,XGBoost,Keras
刷比赛利器,感谢分享的人。 摘要 最近打各种比赛,在这里分享一些General Model,稍微改改就能用的 环境: python 3.5.2 XGBoost调参大全: http://blog.csdn.net/han_xiaoyang/article/details/52665396 XGBoost 官方API: http://xgboost.readthedocs.io/en

【数据分析案例】从XGBoost算法开始,更好地理解和改进你的模型
案例来源:@将门创投 案例地址: https://mp.weixin.qq.com/s/oeetxWMM3cr1BgvIaGU54A 1. 目标:使用xgb评估客户的信贷风险时,还希望得出揭示 2. xgb全局特征重要性度量

机器学习项目——基于机器学习(决策树 随机森林 朴素贝叶斯 SVM KNN XGBoost)的帕金森脑电特征识别研究(代码/报告材料)
完整的论文代码见文章末尾 以下为核心内容和部分结果 问题背景 帕金森病(Parkinson’s Disease, PD)是一种常见的神经退行性疾病,其主要特征是中枢神经系统的多巴胺能神经元逐渐丧失,导致患者出现运动障碍、震颤、僵硬等症状。然而,除运动症状外,帕金森病患者还常常伴有一系列非运动症状,其中睡眠障碍是最为显著的非运动症状之一。 脑电图(Electroencephalogram, E

分类预测|基于蜣螂优化极限梯度提升决策树的数据分类预测Matlab程序DBO-Xgboost 多特征输入单输出 含基础模型
分类预测|基于蜣螂优化极限梯度提升决策树的数据分类预测Matlab程序DBO-Xgboost 多特征输入单输出 含基础模型 文章目录 一、基本原理1. 数据准备2. XGBoost模型建立3. DBO优化XGBoost参数4. 模型训练5. 模型评估6. 结果分析与应用原理总结 二、实验结果三、核心代码四、代码获取五、总结 分类预测|基于蜣螂优化极限梯度提升决策树的数据分类

分类预测|基于雪消融优化极端梯度提升的数据分类预测Matlab程序SAO-XGBoost 多特征输入多类别输出
分类预测|基于雪消融优化极端梯度提升的数据分类预测Matlab程序SAO-XGBoost 多特征输入多类别输出 文章目录 一、基本原理SAO(雪消融智能优化算法)回归预测中的应用XGBoost 回归预测基本原理SAO-XGBoost 流程 二、实验结果三、核心代码四、代码获取五、总结 分类预测|基于雪消融优化极端梯度提升的数据分类预测Matlab程序SAO-XGBoost

猫头虎 分享:Python库 XGBoost 的简介、安装、用法详解入门教程
猫头虎 分享:Python库 XGBoost 的简介、安装、用法详解入门教程 🎯 ✨ 引言 今天猫头虎收到一位粉丝的提问:“猫哥,我在项目中需要用到 XGBoost,可是对它的了解不够深入,不知道从哪开始,能否详细讲解一下?” 当然可以! 今天猫头虎就给大家带来一篇详细的 XGBoost 入门教程,帮助大家从零开始掌握这个在机器学习领域备受欢迎的工具。本文将涵盖 XGBoost 的简介、安装

集成学习之GBDT、XGBOOST、RF
GBDT&&XGBOOST 都属于GBM(GradientBoosting Machine)方法,传统GBDT以CART(分类回归树)作为基分类器,利用损失函数的负梯度方向在当前模型的值作为残差的近似值,可以说在RF的基础上又有进一步提升,能灵活的处理各种类型的数据,在相对较小的调参时间下,预测的准确度较高。 XGBOOST基学习器除了树,还支持线性分类器;XGBOOST在代价函数中加入了

智能优化特征选择|基于鲸鱼WOA优化算法实现的特征选择研究Matlab程序(XGBoost分类器)
智能优化特征选择|基于鲸鱼WOA优化算法实现的特征选择研究Matlab程序(XGBoost分类器) 文章目录 一、基本原理鲸鱼智能优化特征选择流程 二、实验结果三、核心代码四、代码获取五、总结 智能优化特征选择|基于鲸鱼WOA优化算法实现的特征选择研究Matlab程序(XGBoost分类器) 一、基本原理 当然,这里是鲸鱼智能优化算法(WOA)与XGBoost分类器结

win64环境下安装xgboost包
whl下载地址https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost anaconda: cmd 1.切换到anaconda装python的路径: D:\Anaconda\Scripts(roots) 如果是虚拟环境 D:\Anaconda\envs\python35\Scripts 2.然后根据下载的whl文件的位置,继续: pip instal

xgboost在Windows下的安装
1、从此https://git-for-windows.github.io/网址下载Git,安装Git,一直点击下一步即可 2、转到要安装xgboost的路径,输入下列命令下载xgboost git clone --recursive https://github.com/dmlc/xgboost 3、进入xgboost目录,输入以下命令 $ cd xgboost $ gi
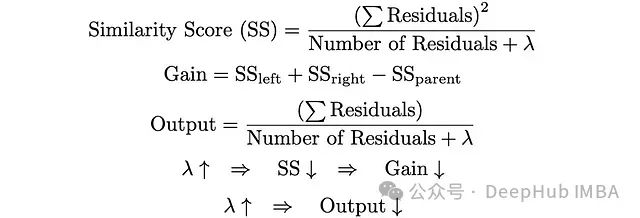
XGBoost中正则化的9个超参数
正则化是一种强大的技术,通过防止过拟合来提高模型性能。本文将探索各种XGBoost中的正则化方法及其优势。 为什么正则化在XGBoost中很重要? XGBoost是一种以其在各种机器学习任务中的效率和性能而闻名的强大算法。像任何其他复杂模型一样,它可能会过拟合,特别是在处理噪声数据或过多特征时。XGBoost中的正则化有助于通过以下方式缓解这一问题: 降低模型复杂度: 通过惩罚较大的系数
大数据竞赛中的xgboost
参考目录1,xgboost参数配置:http://www.cnblogs.com/mfryf/p/6293814.html 参考目录2:http://www.cnblogs.com/mfryf/p/5946815.html 区别回归树和决策树:http://blog.csdn.net/shitaixiaoniu/article/details/53161348 #强烈推荐参考这个网址
XGboost的安装与使用
安装xgboost: conda install py-xgboost 下载demo的数据: https://github.com/dmlc/xgboost 安装graphviz conda install python-graphviz 数据 在demo/data里面: 训练集是:agaricus.txt.train、测试集是:agaricus.txt.test可以直接把de
对比分析:GBDT、XGBoost、CatBoost和LightGBM
对比分析:GBDT、XGBoost、CatBoost和LightGBM 梯度提升决策树(GBDT)是当前机器学习中常用的集成学习方法之一,它通过集成多个弱学习器(通常是决策树)来构建强学习器。GBDT在分类和回归任务中表现优异,并在许多机器学习竞赛中频频获胜。随着算法的发展,GBDT衍生出了多种实现,其中以XGBoost、CatBoost和LightGBM最为知名。本文将详细介绍这四种算法的特点
xgboost的参数设定
先列出Xgboost中可指定的参数,参数的详细说明如下 总共有3类参数:通用参数/general parameters, 集成(增强)参数/booster parameters 和 任务参数/task parameters 通用参数/General Parameters booster [default=gbtree] gbtree 和 gblinear silent [default
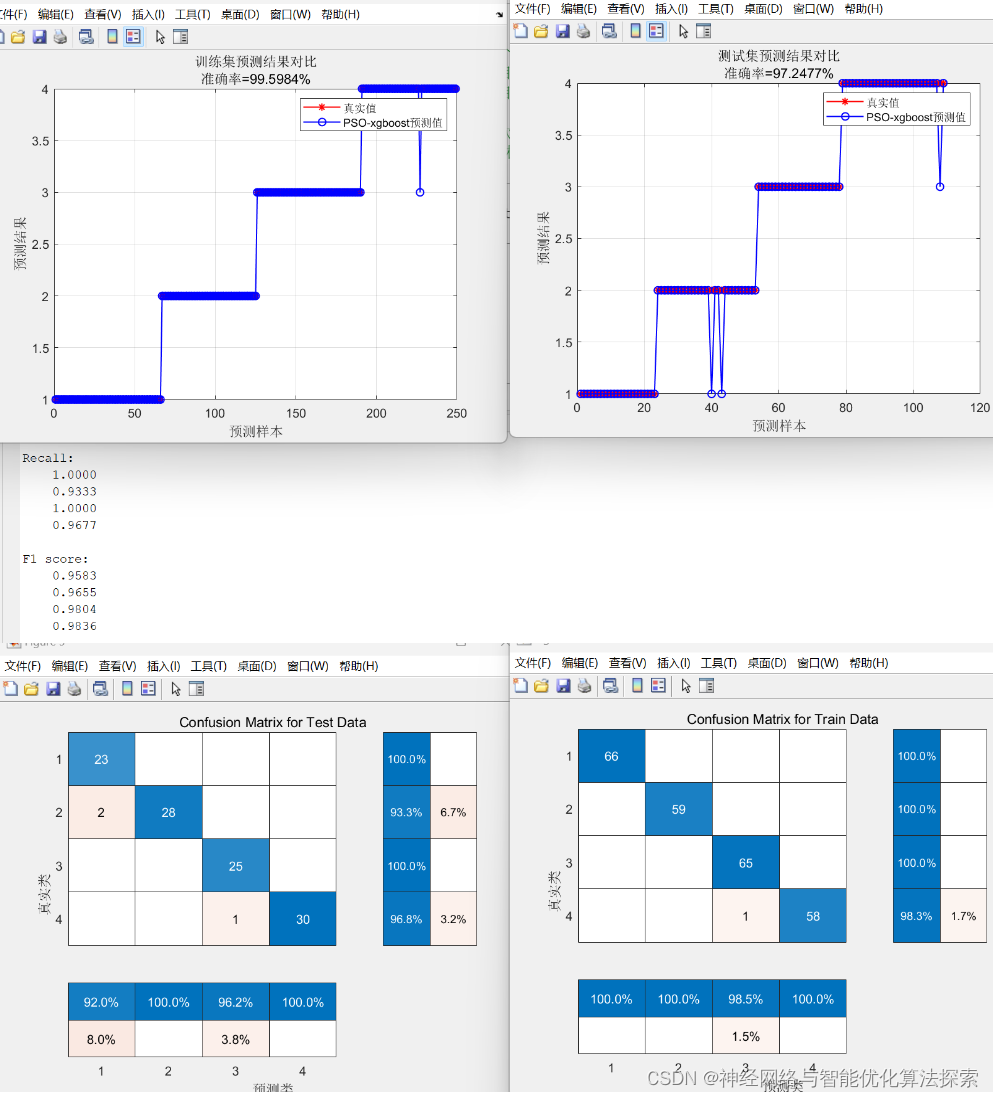
PSO-xgboost分类模型,粒子群优化xgboost(多输入多分类)-MATLAB实现
PSO-xgboost分类模型,粒子群优化xgboost(多输入多分类)-MATLAB实现 使用粒子群优化 (PSO) 来优化 XGBoost 分类模型的超参数是一种有效的方法,可以提高模型的性能。 结果 获取方式 https://mbd.pub/o/bread/mbd-ZpeWlZ9t
GBDTGBRT与XGBoost
在看清华学霸版《Python大战机器学习》的过程中,集成学习章节中出现了两个新的名词:GBDT&GBRT,也许是西瓜书定位于全面,而没有拘泥于细节。后来科普发现,这两个东西和陈天奇大神的XGBoost紧密相连,于是估摸着花时间弄懂这两个东西。 首先回顾一下集成学习的核心要点:在基学习器有一定准确性的基础上保证基学习器之间的多样性,总而言之即“好而不同”四字真言。集成学习主要有两种类型的学习算法:
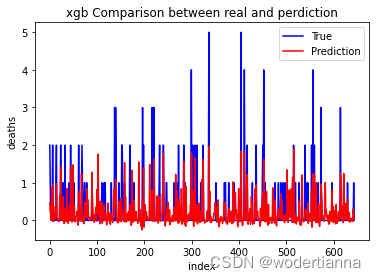
XGBoost预测及调参过程(+变量重要性)--血友病计数数据
所使用的数据是血友病数据,如有需要,可在主页资源处获取,数据信息如下: 读取数据及数据集区分 数据预处理及区分数据集代码如下(详细预处理说明见上篇文章--随机森林): import pandas as pdimport numpy as nphemophilia = pd.read_csv('D:/my_files/data.csv') #读取数据

xgboost安装使用(anaconda中)
本人使用windows系统下的anocaonda的版本为Anaconda2-4.0.0-Windows-x86_64.exe,自带python版本python2.7.13。 通过conda install py-xgboost命令就可以进行安装 通过conda list命令我们可以查看安装的所有库。 然后直接运行下面的测试例子用出错, *找不到要加载的dll库,这时候我们需要重要的一步就是
Windows下快速安装xgboost
Windows下快速安装xgboost 开始安装网上的教程各种配置环境很复杂,其实完全可以不要那样操作。直接pip安装就好。就是需要先下载相应符合要求的xgboost的包即可。 如Windows10 Python3.6 64位系统,就下载xgboost-0.6-cp36-cp36m-win_amd64.whl。。然后 cmd下输入: pip install xgboost-0.6-cp36-