worker专题

java线程深度解析(四)——并发模型(Master-Worker)
http://blog.csdn.net/daybreak1209/article/details/51372929 二、Master-worker ——分而治之 Master-worker常用的并行模式之一,核心思想是由两个进程协作工作,master负责接收和分配任务,worker负责处理任务,并把处理结果返回给Master进程,由Master进行汇总,返回给客

【HarmonyOS】-TaskPool和Worker的对比实践
ArkTS提供了TaskPool与Worker两种多线程并发方案,下面我们将从其工作原理、使用效果对比两种方案的差异,进而选择适用于ArkTS图片编辑场景的并发方案。 TaskPool与Worker工作原理 TaskPool与Worker两种多线程并发能力均是基于 Actor并发模型实现的。Worker主、子线程通过收发消息进行通信;TaskPool基于Worker做了更多场景化的功能封装,例


程序员面试之nginx和apache的区别,nginx在开启时,会生成一个master进程,然后,master进程会fork多个worker子进程,最后每个用户的请求由worker的子线程处理。
Apache和Nginx最核心的区别在于 apache 是同步多进程模型,一个连接对应一个进程;而 nginx 是异步的,多个连接(万级别)可以对应一个进程。下面本篇文章就来给大家介绍一下Apache和Nginx的区别有那些,选择哪个好?希望对你们有所帮助。 AI:please wait...Nginx和Apache都是常用的Web服务器软件,它们在以下几个方面有一些区别:1. 架构和性能:N

Spark Worker原理
Master发送LaunchDriver和LaunchExecutor到Worker LaunchDriver -DriverRunner 内部使用Thread来处理Driver的启动。 1.创建Driver在本地文件系统的工作目录。 2.封装好Driver的启动Command,并通过ProcessBuilder来启动Driver。 3.Driver进程 LaunchEx

JS New Worker() 深度解析
JS New Worker() 深度解析 文章目录 一、New Worker() 是什么及为什么出现二、JS中如何使用 New Worker()1. 创建 Worker 线程2. 向 Worker 发送消息3. 接收 Worker 的消息4. 监听错误和结束事件5. 终止 Worker 三、Worker 包含哪些属性或方法 API1. 属性2

Web Worker 应用场景和实现
应用场景 众所周知JavaScript是单线程的语言,所有任务只能在一个线程上完成,一次只能做一件事,即前面的任务还没有完成,后面的任务只能排队等待。如果前面的任务需要执行一些大数据量的计算,页面就会出现卡顿、点击无反应、甚至页面崩溃等现象。这对用户体验而言是非常糟糕的。 在这种情况下,Web Worker可以为js提供一个多线程环境 ,主线程可以将一些耗时、复杂的计算任务分配给
Resend Cloudflare Worker Service
提供中文、英文两个版本。 目录 准备工作Worker / Pages 中使用本地开发测试PrepareUse in Worker / PagesLocal Development 代码仓库: https://github.com/willin/resend-cloudflare-service-worker 准备工作 Use this template 活 Fork 这个仓

Web Worker 学习及使用
了解什么是 Web Worker 提供了可以在后台线程中运行 js 的方法。可以不占用主线程,不干扰用户界面,可以用来执行复杂、耗时的任务。 在worker中运行的是另一个全局上下文,不能直接获取 Window 全局对象。不同的 worker 可以分为专用和共享,专用 worker 仅在单一脚本中被使用,它的上下文对象是DedicatedWorkerGlobalScope;共享 worker
![gunicorn超时报错[CRITICAL] WORKER TIMEOUT](https://img-blog.csdnimg.cn/direct/3fe8a9fa468d4e808c827a0332eebe4e.jpeg)
gunicorn超时报错[CRITICAL] WORKER TIMEOUT
一. 问题描述 2024-06-18T08:40:39.858804039Z [2024-06-18 08:40:39 +0000] [1] [CRITICAL] WORKER TIMEOUT (pid:332)2024-06-18T08:40:40.918093090Z [2024-06-18 08:40:40 +0000] [1] [ERROR] Worker (pid:332) was
Kubernetes面试整理-Master节点和Worker节点的作用
在 Kubernetes 中,集群由两类节点组成:Master 节点和 Worker 节点。每类节点都有其特定的作用和职责。 Master 节点 Master 节点是 Kubernetes 集群的控制平面,负责管理集群的状态和控制整个集群的操作。主要组件及其作用如下: 1. API 服务器(kube-apiserver): ● 作为控制平面的前端,接收、验证并处理所有的 API 请求。

Worker内部工作原理
Worker、Executor、Task 三者的关系 storm集群中的一台机器可能运行着一个或者多个worker进程,其从属于一个或者多个topology。一个worker进程运行着多个executor线程;每一个worker从属于一个topology;executor是单线程,每一个executor运行着相同组件(spout或者bolt)的1个或者多个task;1个task执行(spo
使用Service Worker、Web Workers进行地图渲染优化
地图的渲染涉及到大量的dom, 如果每次地图重渲染都操作dom将会照成很大的性能开销,下面总结两个方案来开发和优化离线地图,以提升地图操作的流畅性和性能: 方案一:使用Service Worker和离线缓存 利用Service Worker技术,可以拦截网页的网络请求,并可在离线时为这些请求提供缓存响应。通过注册一个Service Worker脚本,我们可以实现地图资源的离线缓存。 在Se
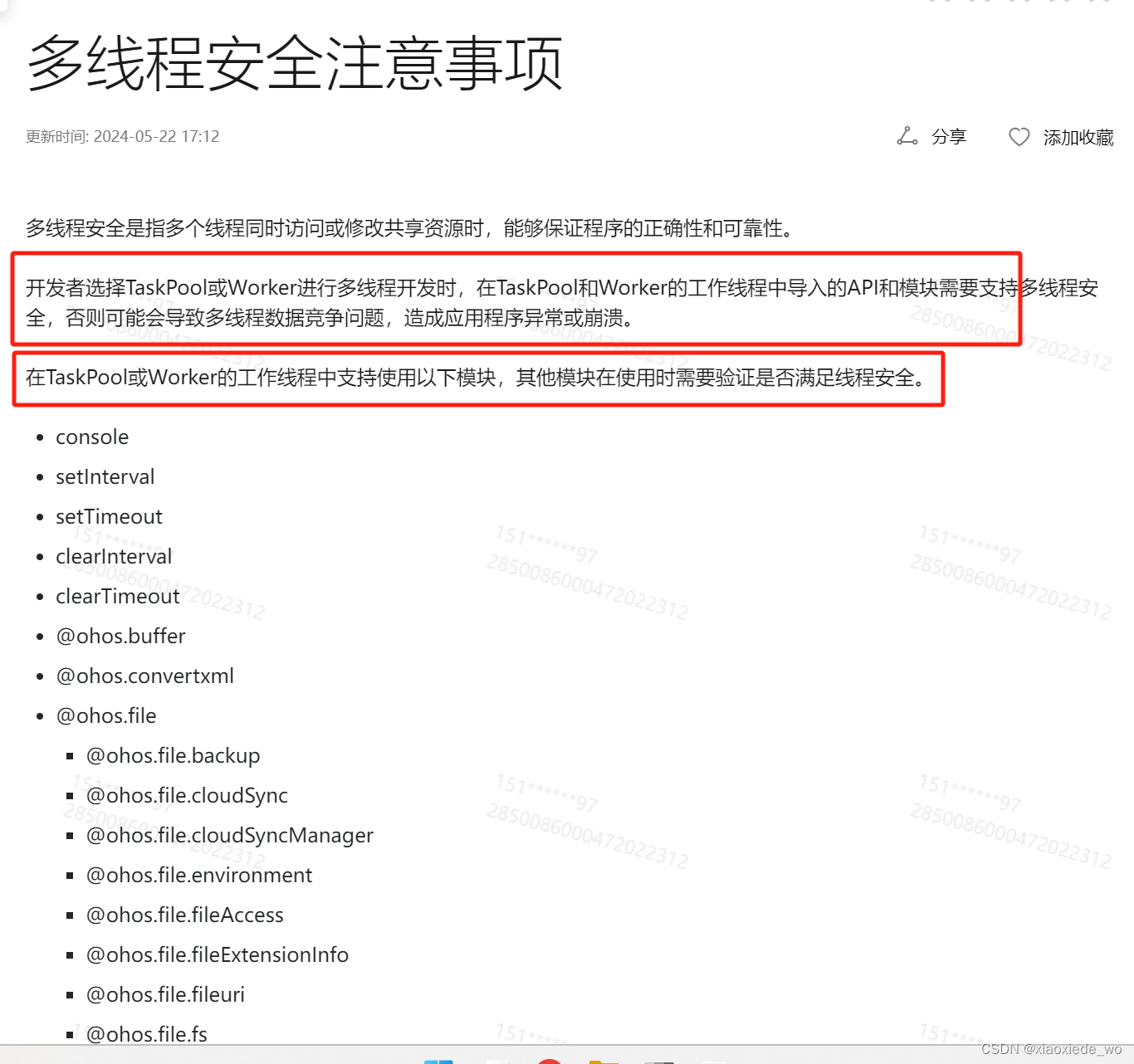
ArkTs-TaskPool和Worker的使用
TaskPool和Worker的区别 实现TaskPoolWorker内存模型线程间隔离,内存不共享。线程间隔离,内存不共享。参数传递机制 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。 支持ArrayBuffer转移和SharedArrayBuffer共享。 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完
如何在Spark的Worker节点中给RocketMq发送消息
1.背景 之前使用spark进行数据计算,需要将计算结果发送到rocketmq上去,有两种做法:第一种是将计算结果collect到Driver端,然后统一发送。第二种是直接在各个计算结果的partition(即foreachPartition函数)分片中发送。第一种存在的问题是,如果计算结果的数据量非常庞大,如上千万,就需要很大的内存来支持,同时增加了网络传输开销。如果是第二种就不

Line Worker(流水线工人休闲游戏模板)
您是地狱工厂的流水线工人。您的工作是在产品不断流动的情况下,将有缺陷的产品与合格产品区分开来。通过点击左右键来保留合格产品并丢弃不合格产品。错误太多,您将被解雇!《流水线工人》是一款有趣、轻松、超级休闲的游戏,适合所有年龄段的人! 亮点: - 上瘾的超休闲游戏适合所有人。 - 3种开箱即用的产品类型,更有趣:瓶子、泰迪熊和机器人。 易于定制。 - 资产(声音、字体、模型、精灵等)可免费用于商业
Docker Swarm - 删除 worker 节点
1、前提:集群环境已经运行 在manager节点上执行: # 查看节点信息>>> docker node lsID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSIONjr06s8pbrclkrxt7jpy7wae8t *

Spark中Master、Worker、Client通信示意图
1.Master和Worker之间的消息传递示意图 2.Master和Client之间的消息传递示意图 这几天主要都是基于Standalone分析的,最后以两张图完美收工 原文地址:http://www.cnblogs.com/yourarebest/p/5313056.html client to master RegisterApplication (向master
源码- Spark中Worker源码分析(二)
继续前一篇的内容。前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, receive方法主要分为以下14种情况: (1)worker向master注册成功后,详见代码 (2)worker向master发送心跳消息,如果还没有注册到master上,该消息将被忽略,
源码-Spark中Worker源码分析(一)
Worker作为对于Spark集群的健壮运行起着举足轻重的作用,作为Master的奴隶,每15s向Master告诉自己还活着,一旦主人(Master》有了任务(Application),立马交给属于它的奴隶们(Workers),那么奴隶们就会数数自己有多少家当(比如内存、核数),量力而行地交给主人完成的任务,如果奴隶不量力而行在执行任务过程中不幸死了的话,作为主人的Master只会等待60s,如
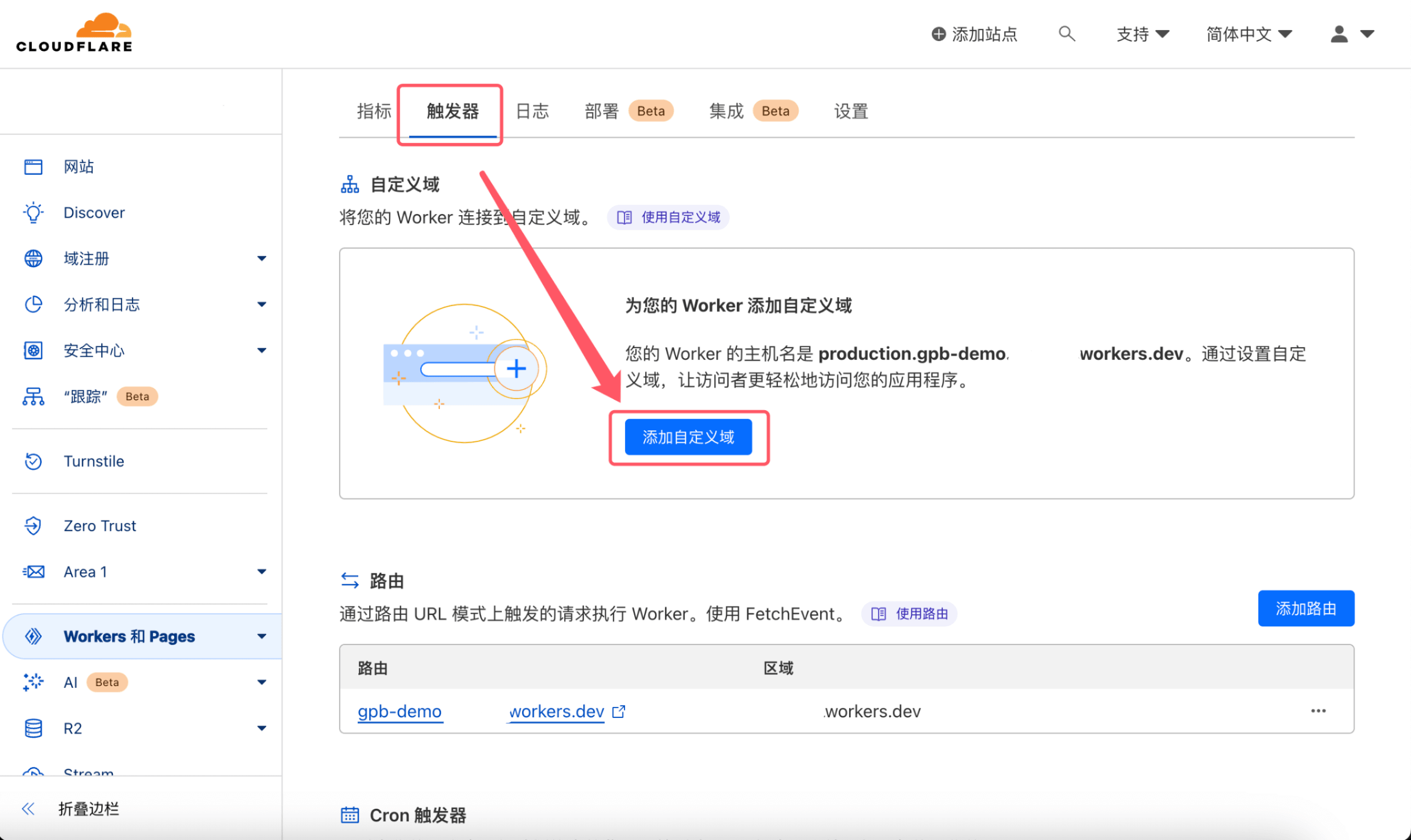
Cloudflare Worker 部署bingai
Cloudflare Worker 部署 1. 注册 Cloudflare 账号 2. 一键部署 登录账户后, 点击下面链接 https://deploy.workers.cloudflare.com/?url=https://github.com/Harry-zklcdc/go-proxy-bingai 点击「Authorize Workers」, 登录 Github 账号授权 Clo

纯血鸿蒙APP实战开发——Worker子线程中解压文件
介绍 本示例介绍在Worker 子线程使用@ohos.zlib 提供的zlib.decompressfile接口对沙箱目录中的压缩文件进行解压操作,解压成功后将解压路径返回主线程,获取解压文件列表。 效果图预览 使用说明 点击解压按钮,解压test.zip文件,显示解压结果。 实现思路 在/src/main/ets/workers目录下创建Worker.ets线程文件,绑定Work

海豚调度器如何看工作流是在哪个worker节点执行
用海豚调度器,执行一个工作流时,有时成功,有时失败,怀疑跟worker节点环境配置不一样有关。要怎样看是在哪个worker节点执行,在 海豚调度器 Web UI 中,您可以查看任务实例,里面有一列显示host,可以根据host看是哪一个worker节点运行。
海豚调度器早期版本如何新增worker分组
在DolphinScheduler 1.3.5版本中,Worker分组通常是在部署时通过配置文件进行定义的,而不是在用户界面上直接操作。以下是在DolphinScheduler中新增Worker分组的一般步骤: 修改配置文件: DolphinScheduler的Worker分组信息通常在/conf目录下的配置文件中定义。你需要找到相关的配置文件,比如dolphinscheduler-env.sh
node.js中 cluster 模块和 worker_threads 模块
1. cluster 模块 const cluster = require('cluster');if (cluster.isMaster) {// 主进程代码for (let i = 0; i < numCPUs; i++) {cluster.fork();}} else {// 子进程代码// 创建 Nest.js 应用程序实例等} 2. worker_threads 模块 con

16 Master-Worker模式
6.3 Master-Worker模式 Master-Worker模式是常用的并行计算模式,它的核心思想是系统由两类进程协作工作:Master进程和Worker进程。Master负责接收和分配任务,Woker负责处理子任务。当各个Worker子进程处理完后,会将结果返回给Master,由Master做归纳和总结。其好处是能将一个大任务分解成若干小任务,并行执行,从而提高系统的吞吐量。