本文主要是介绍ArkTs-TaskPool和Worker的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TaskPool和Worker的区别
| 实现 | TaskPool | Worker |
|---|---|---|
| 内存模型 | 线程间隔离,内存不共享。 | 线程间隔离,内存不共享。 |
| 参数传递机制 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。 支持ArrayBuffer转移和SharedArrayBuffer共享。 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。 支持ArrayBuffer转移和SharedArrayBuffer共享。 |
| 参数传递 | 直接传递,无需封装,默认进行transfer。 | 消息对象唯一参数,需要自己封装。 |
| 方法调用 | 直接将方法传入调用。 | 在Worker线程中进行消息解析并调用对应方法。 |
| 返回值 | 异步调用后默认返回。 | 主动发送消息,需在onmessage解析赋值。 |
| 生命周期 | TaskPool自行管理生命周期,无需关心任务负载高低。 | 开发者自行管理Worker的数量及生命周期。 |
| 任务池个数上限 | 自动管理,无需配置。 | 同个进程下,最多支持同时开启8个Worker线程。 |
| 任务执行时长上限 | 3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时)。 | 无限制。 |
| 设置任务的优先级 | 支持配置任务优先级。 | 不支持。 |
| 执行任务的取消 | 支持取消已经发起的任务。 | 不支持。 |
| 线程复用 | 支持。 | 不支持。 |
| 任务延时执行 | 支持。 | 不支持。 |
| 设置任务依赖关系 | 支持。 | 不支持。 |
| 串行队列 | 支持。 | 不支持。 |
| 任务组 | 支持。 | 不支持。 |
性能优化:
- 启动问题
- 多线程不会造成卡死的问题,同时做多件事情
- 主线程负责UI渲染-数据加载
taskPool
1、excute执行函数, 必须执行被Concurrent修饰的方法
2、 必须是全局方法--(该修饰符必须在全局定义,不支持在组件内部定义)
3、该方法中 不能用导入的方法
4、 不能直接返回,要求先把事情做完,再返回结果,不能返回一个没有结果的耗时任务
import { http } from '@kit.NetworkKit'
import { taskpool, worker } from '@kit.ArkTS'@Concurrent
async function getMyInfo() {/*1、 必须执行被Concurrent修饰的方法2、 必须是全局方法3、该方法中 不能用导入的方法4、 不能直接返回,要求先把事情做完,再返回结果,不能返回一个没有结果的耗时任务*/// return http.createHttp().request("https://****")const result = await http.createHttp().request("https://toutiao.itheima.net/v1_0/channels")return result
}@Entry
@Component
struct Home {aboutToAppear(): void {// 开启多线程,请求我的数据const task1 = new taskpool.Task(getMyInfo)taskpool.execute(task1).then(res => {//使用场景:在tab1页面把tab4页面的数据请求回来存到全局,tab4的页面直接获取数据,显示就会更丝滑AlertDialog.show({ message: JSON.stringify(res, null, 2) })})}build() {}
}Worker
1.在ets下面新建一个worker 2.写入worker的路径的写法规则如下
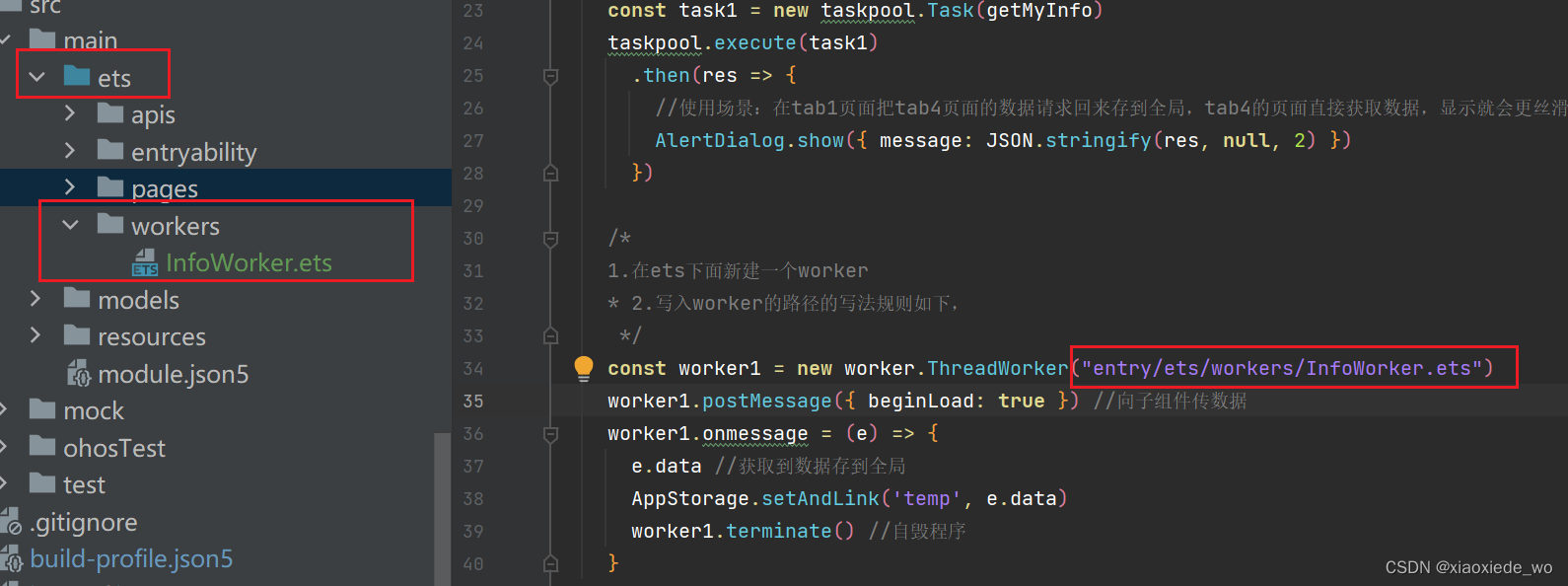
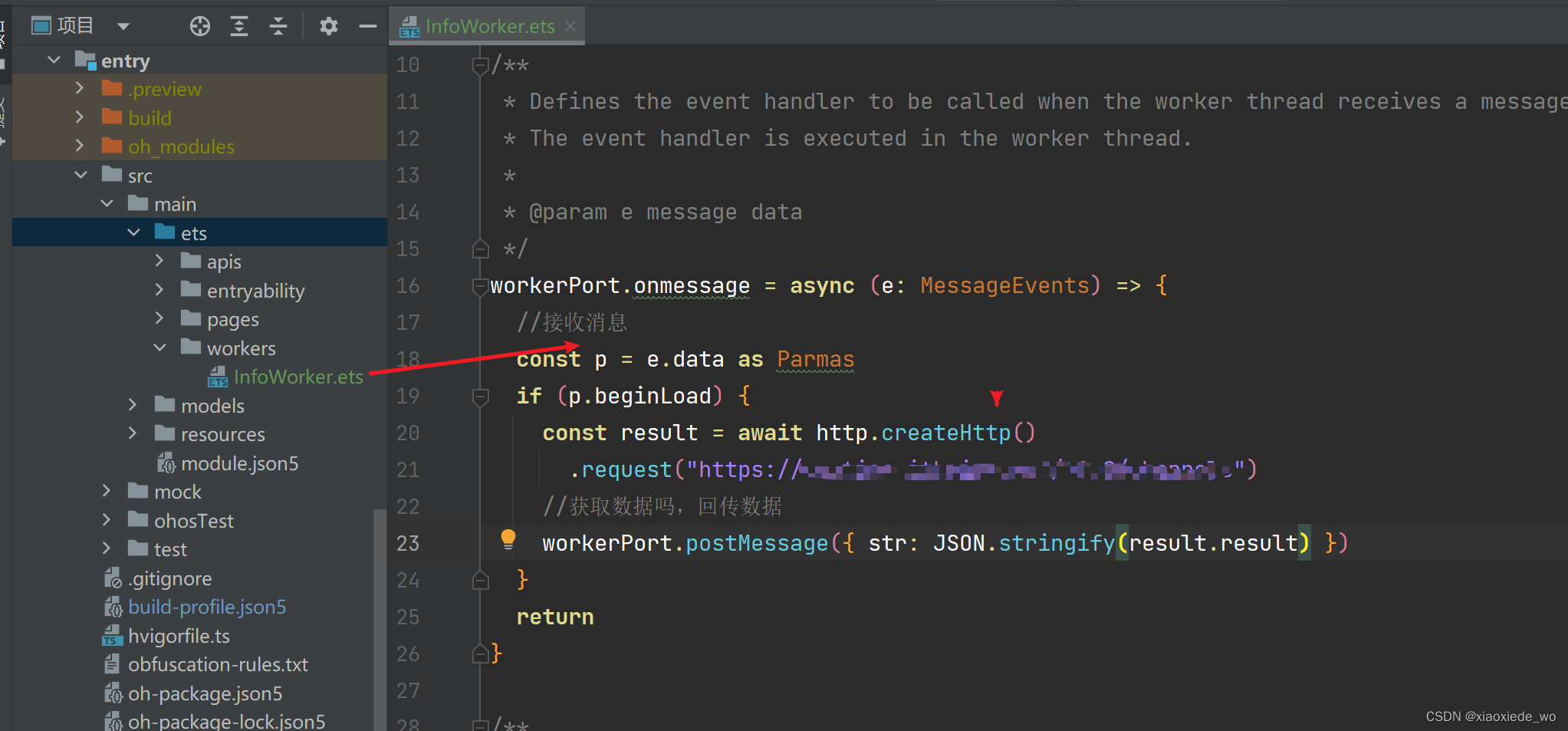
注意
传值的时候,必须传可被序列化的数据
被@State、@Link @Provide等修饰的变量,都不可被序列化,因为都被包了一层Proxy
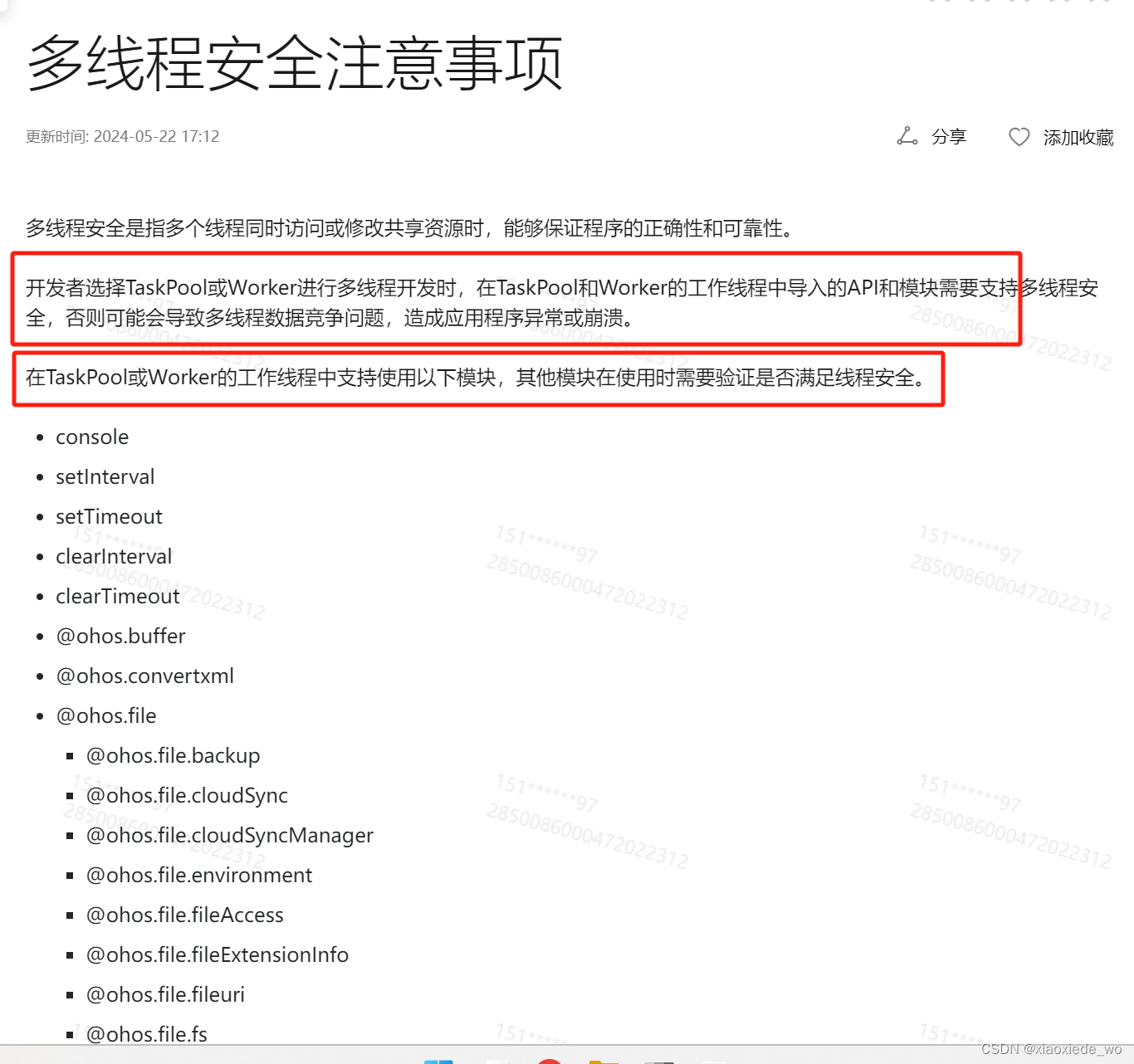
线程安全问题
如:同一时间多个线程处理同一个文件
规定:必须使用线程安全的库
自行控制 如:打标记
比如声明一个当前文件是否正在编辑的状态,isEdit
isEdit==true;正在编辑状态,等待
isEdit==false;置为true,编辑..完成后置为false
这篇关于ArkTs-TaskPool和Worker的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







