wgan专题


从GAN到WGAN及WGAN-GP
20200910 - 0. 引言 最近看了PassGAN的代码,他是使用了WGAN-GP的代码作为GAN的框架,来进行密码生成,由此引出了对GAN的学习。在GAN的研究中,有一个方向就是研究如何使GAN更加稳定的训练。在此之中,WGAN和WGAN-GP算是比较好的解决方案。 为了弄明白这些东西,也是花费了很长时间,主要是因为这部分都是数学公式的内容,而我这种半吊子也不是搞数学的,也不是专门搞人

从GAN到WGAN(02/2)
文章目录 一、说明二、GAN中的问题2.1 难以实现纳什均衡(Nash equilibrium)2.2 低维度支撑2.3 梯度消失2.4 模式坍缩2.5 缺乏适当的评估指标 三、改进的GAN训练四、瓦瑟斯坦(Wasserstein)WGAN4.1 什么是 Wasserstein 距离?4.2 为什么 Wasserstein 优于 JS 或 KL 背离?4.3 使用 Wasserstein 距
从GAN到WGAN(01/2)
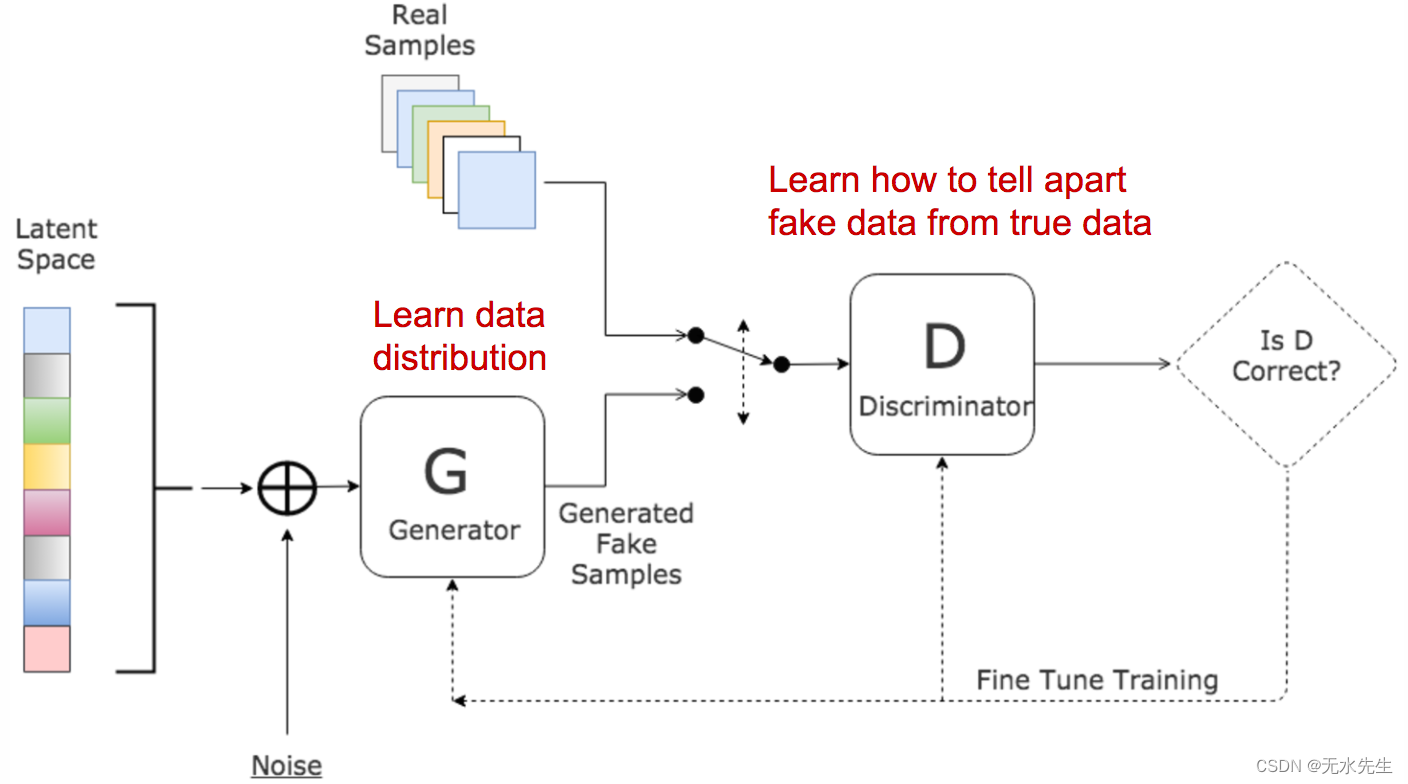
从GAN到WGAN 文章目录 一、说明二、Kullback-Leibler 和 Jensen-Shannon 背离三、生成对抗网络 (GAN)四、D 的最优值是多少?五、什么是全局最优?六、损失函数代表什么?七、GAN中的问题 一、说明 生成对抗网络 (GAN) 在许多生成任务中显示出巨大的效果,以复制现实世界的丰富内容,如图像、人类语言和音乐。它的灵感来自博弈论:两个模型,一个
Deep-Fake原理揭示:使用WGAN-GP算法构造精致人脸
在上一节中可以看到基于”推土距离“的WGAN网络能够有效生成马图片,但是网络构造能力有所不足,因此导致有些图片模糊,甚至有些图片连马的轮廓都没有构建出来,本节我们改进WGAN网络,让它具有更强大的图像生成能力。 在介绍WGAN网络算法时提到,如果把网络看成一个函数,那么网络要想具备好的图像生成能力就必须满足1-Lipshitz条件,也就是要满足公式: 根据微积分的中值定理,如果函数f(x)可导
使用WGAN-GP算法构造精致人脸
在上一节中可以看到基于”推土距离“的WGAN网络能够有效生成马图片,但是网络构造能力有所不足,因此导致有些图片模糊,甚至有些图片连马的轮廓都没有构建出来,本节我们改进WGAN网络,让它具有更强大的图像生成能力。 在介绍WGAN网络算法时提到,如果把网络看成一个函数,那么网络要想具备好的图像生成能力就必须满足1-Lipshitz条件,也就是要满足公式: 根据微积分的中值定理,如果函数f(x)
使用’推土距离‘构建强悍的WGAN
读者读到此处时或许会有一个感触,网络训练的目的是让网络在接收输入数据后,它输出的结果在给定衡量标准上变得越来越好,由此“衡量标准”设计的好坏对网络训练最终结果产生至关重要的作用。 回想上一节,当我们把N张数据图片输入到网络后,网络会输出一个含有N个分量的向量,接着我们先构造一个含有N个1的向量,然后判断网络得出的向量与构造的含有N个1的向量是否足够“接近”。 算法判断两个向量是否接近的标准是“
GAN笔记_李弘毅教程(六)WGAN、EBGAN
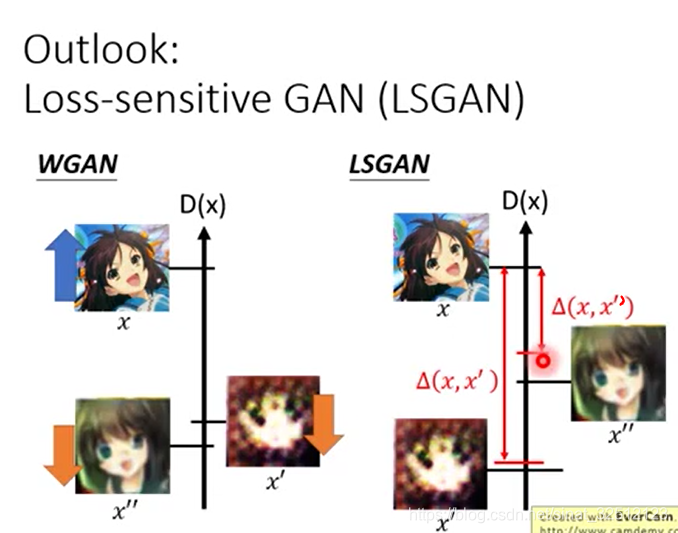
文章目录 Wasserstein GAN(WGAN)Improved WGAN(WGAN GP)Energy-based GAN(EBGAN)Loss-sensitive GAN(LSGAN) 在大多数情况下, P G {P_G} PG和 P d a t a {P_{data}} Pdata训练到最后是不会重叠的。因为有两点。 1.data本质: P G

GAN:WGAN-GP-带有梯度惩罚的WGAN
论文:https://arxiv.org/pdf/1704.00028.pdf 代码:GitHub - igul222/improved_wgan_training: Code for reproducing experiments in "Improved Training of Wasserstein GANs" 发表:2017 WGAN三部曲的终章-WGAN-GP 摘要 W
李宏毅对抗生成网络 (GAN)教程(4)Tips for GAN (WGAN EBGAN)
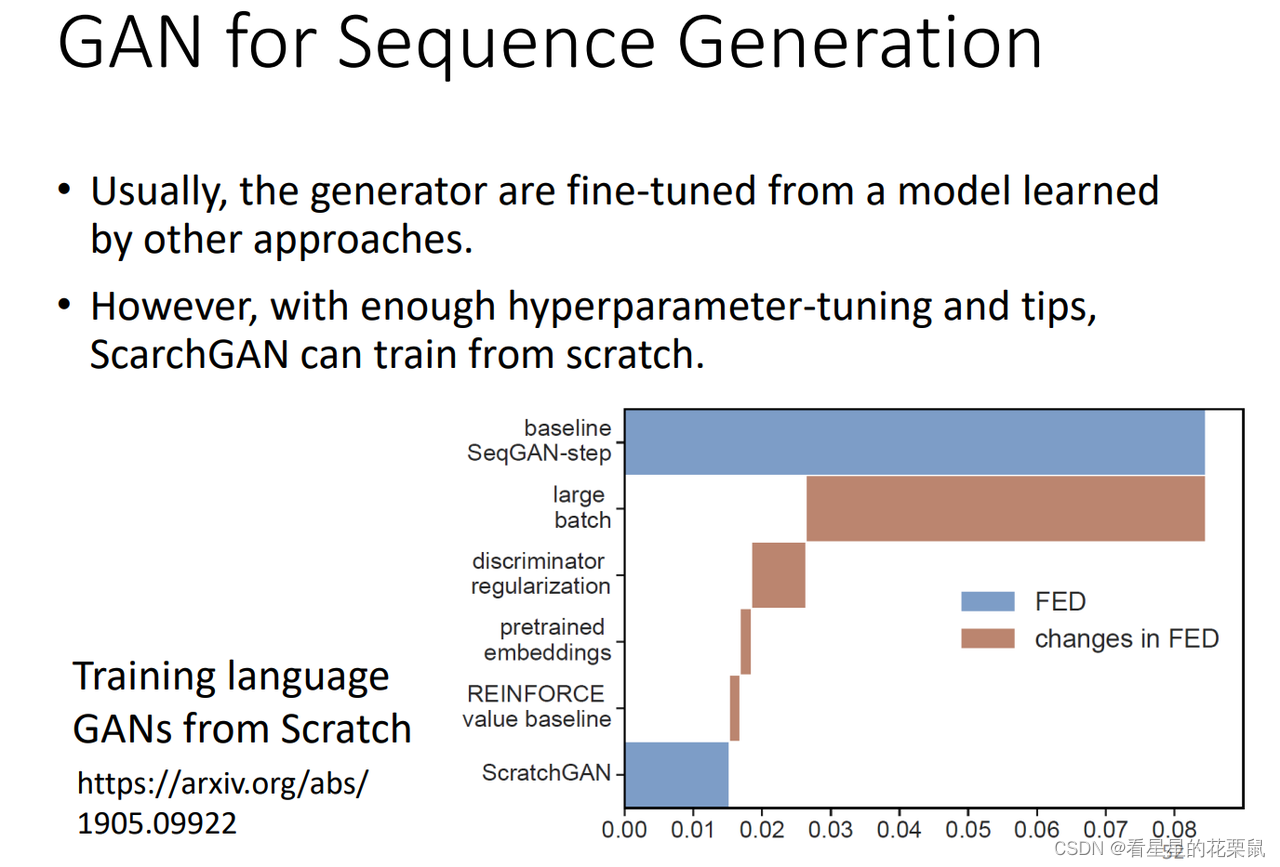
在李宏毅GAN教程(3) 的基础上增添修改内容 文章目录 JS散度不是很适合LSGANEBGANLSGAN(Loss-sensitive GAN)仍然存在的问题GAN for Sequence Generation 为了让GAN容易训练 JS散度不是很适合 最原始的GAN量的是Pg和Pdata之间的JS散度;但是有一个严重的问题:可能两个分布没有任何的重叠,一方面的原因是

GAN:WGAN前作
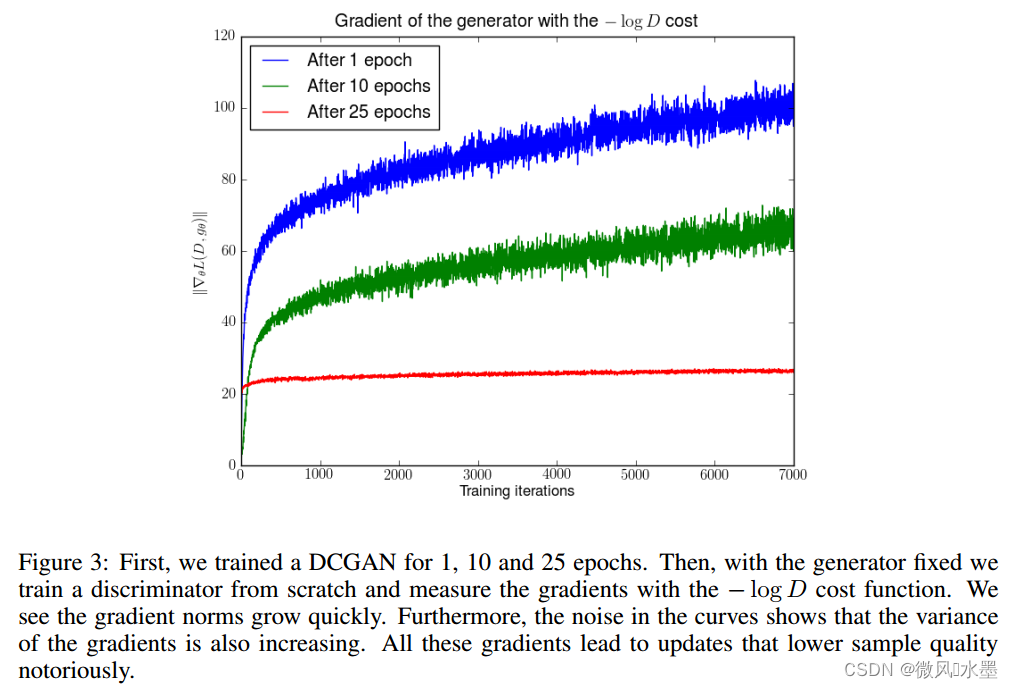
WGAN前作:有原则的方法来训练GANs 论文:https://arxiv.org/abs/1701.04862 发表:ICLR 2017 本文是wgan三部曲的第一部。文中并没有引入新的算法,而是标是朝着完全理解生成对抗网络的训练动态过程迈进理论性的一步。 文中基本是理论公式的推导,看起来确实头大,偷懒就直接阅读网上整理好的资料了,参考 1:译文 2:生成模型(一):GAN -
![[PyTorch][chapter 57][WGAN-GP 代码实现]](https://img-blog.csdnimg.cn/1a227a6496cf4e3fb077aa12551839c9.png)
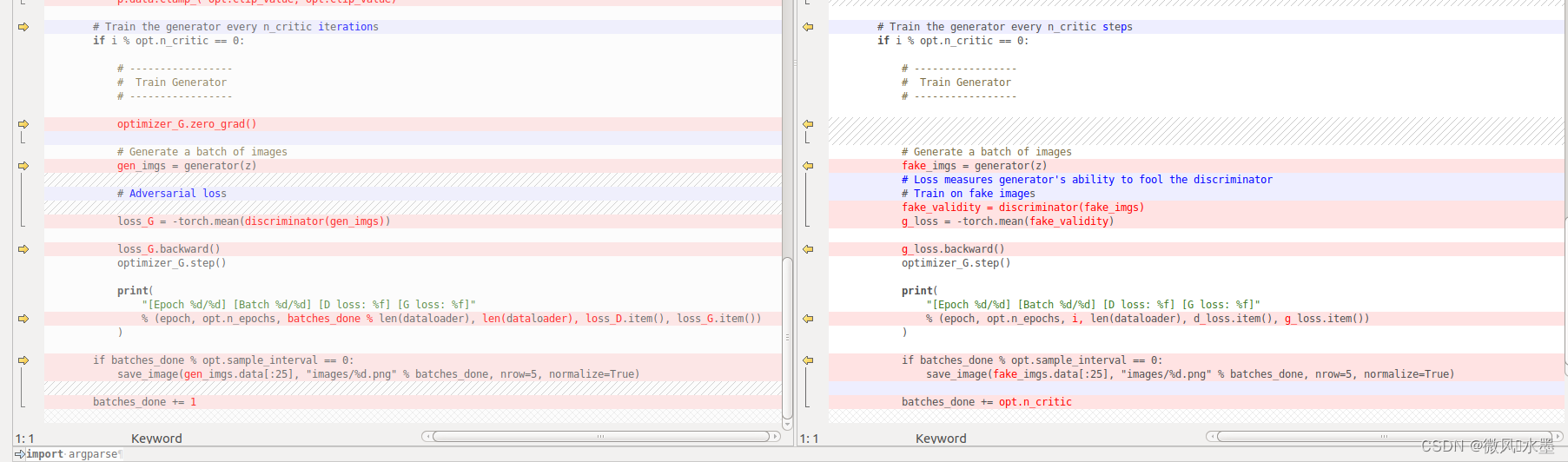
[PyTorch][chapter 57][WGAN-GP 代码实现]
前言: 下图为WGAN 的效果图: 绿色为真实数据的分布: 8个高斯分布 红色: 为随机产生的数据分布,跟真实分布基本一致 WGAN-GP: 1 判别器D: 最后一层去掉sigmoid 2 生成器G 和判别器D: loss不取log 3 损失函数 增加了penalty,使用Adam Wasserstein GAN 1 判别器D: 最后一层去掉sigmoid 2 生成器G